Downloaded 759 times




























![public class SimpleWordCount
extends Configured implements Tool {
public static class MapClass
extends Mapper<Object, Text, Text, IntWritable> {
...
}
public static class Reduce
extends Reducer<Text, IntWritable, Text, IntWritable> {
...
}
public int run(String[] args) throws Exception { ... }
public static void main(String[] args) { ... }
}](https://image.slidesharecdn.com/hadoop-110509234250-phpapp02/85/Hadoop-34-320.jpg)


![public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf, "Counting Words");
job.setJarByClass(SimpleWordCount.class);
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}](https://image.slidesharecdn.com/hadoop-110509234250-phpapp02/85/Hadoop-37-320.jpg)
![public static void main(String[] args) throws Exception {
int result = ToolRunner.run(new Configuration(),
new SimpleWordCount(),
args);
System.exit(result);
}](https://image.slidesharecdn.com/hadoop-110509234250-phpapp02/85/Hadoop-38-320.jpg)
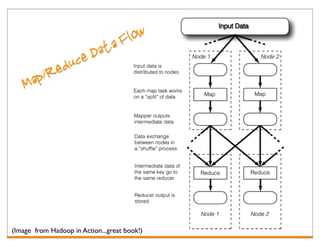

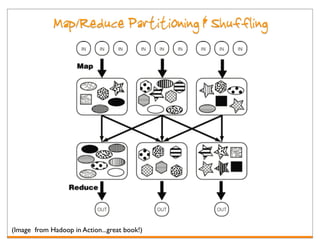




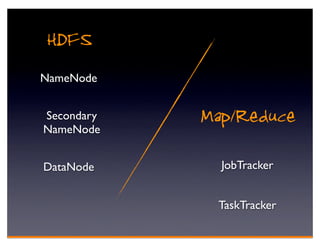
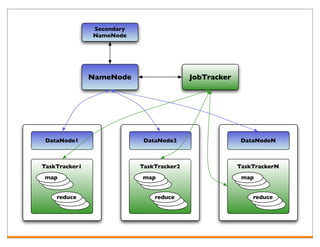

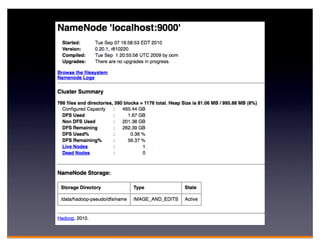
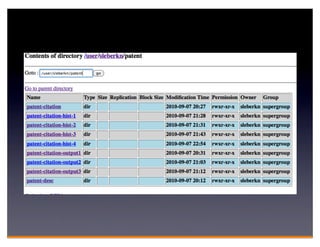


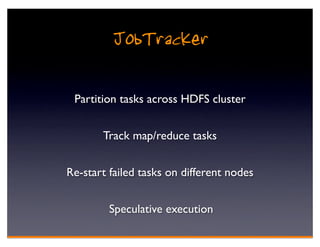

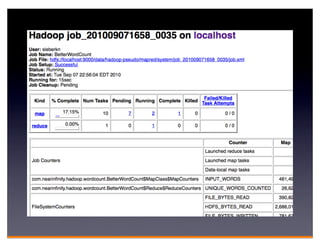

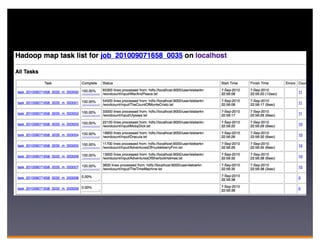


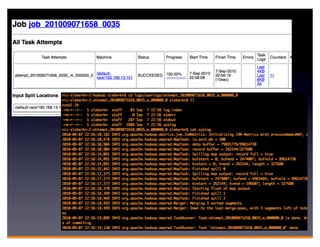

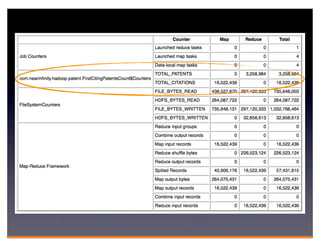








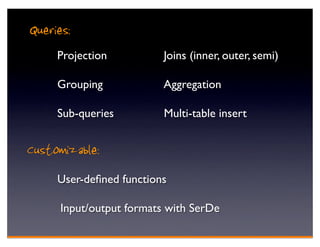

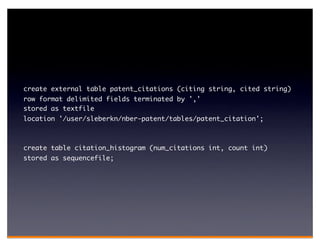












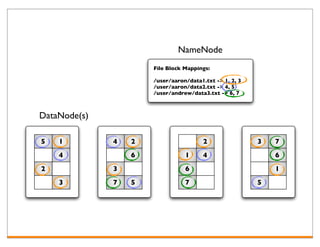
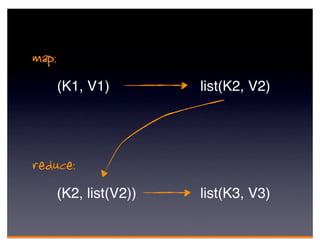
Hadoop is an open-source framework for distributed storage and processing of large datasets across clusters of computers. It consists of HDFS for distributed storage and MapReduce for distributed processing. HDFS stores large files across multiple machines and provides high throughput access to application data. MapReduce allows processing of large datasets in parallel by splitting the work into independent tasks called maps and reduces. Companies use Hadoop for applications like log analysis, data warehousing, machine learning, and scientific computing on large datasets.






































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































