Download as PDF, PPTX













![Got byte[]?](https://image.slidesharecdn.com/hbase-lightningtalk-120427164435-phpapp01/75/HBase-Lightning-Talk-15-2048.jpg)





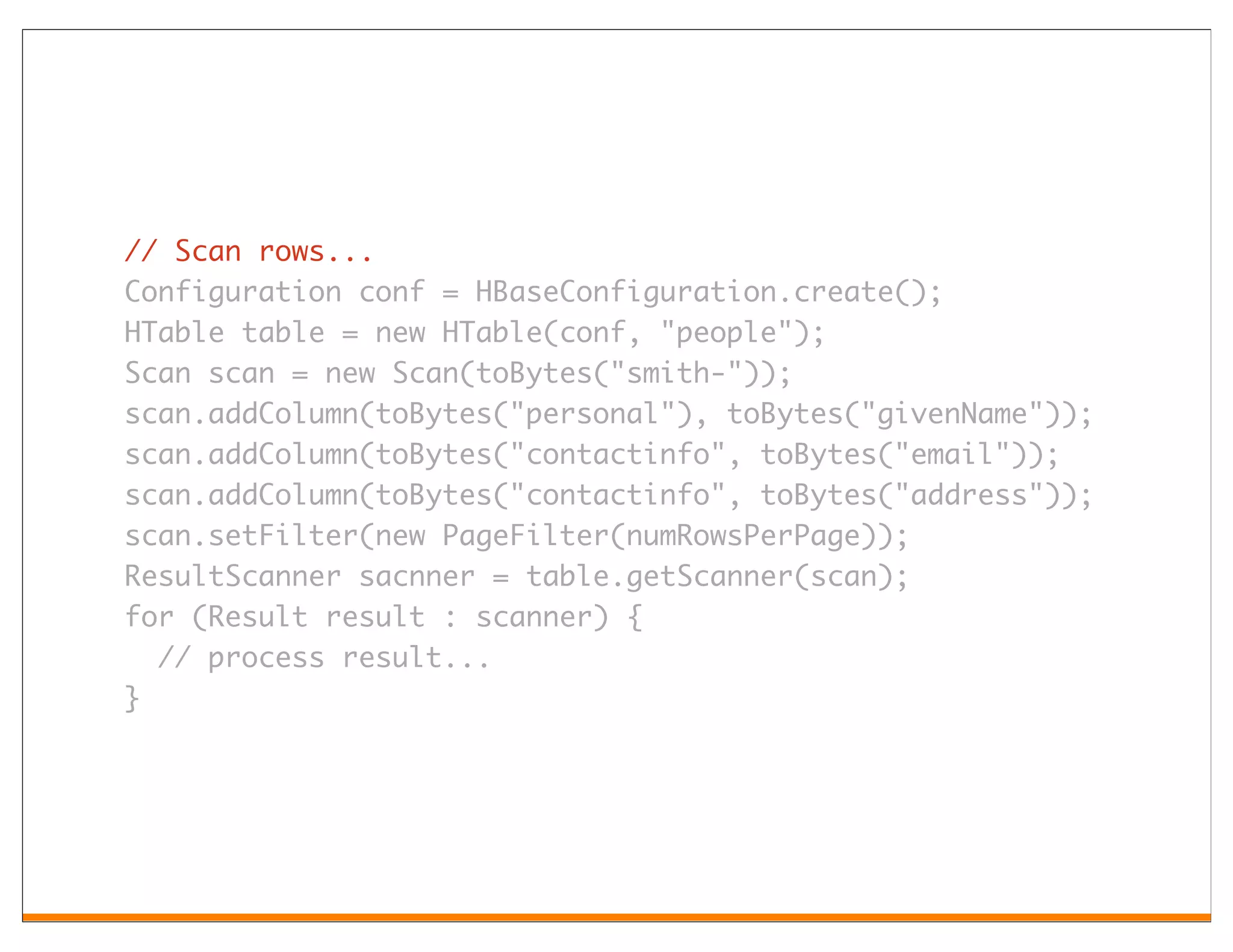




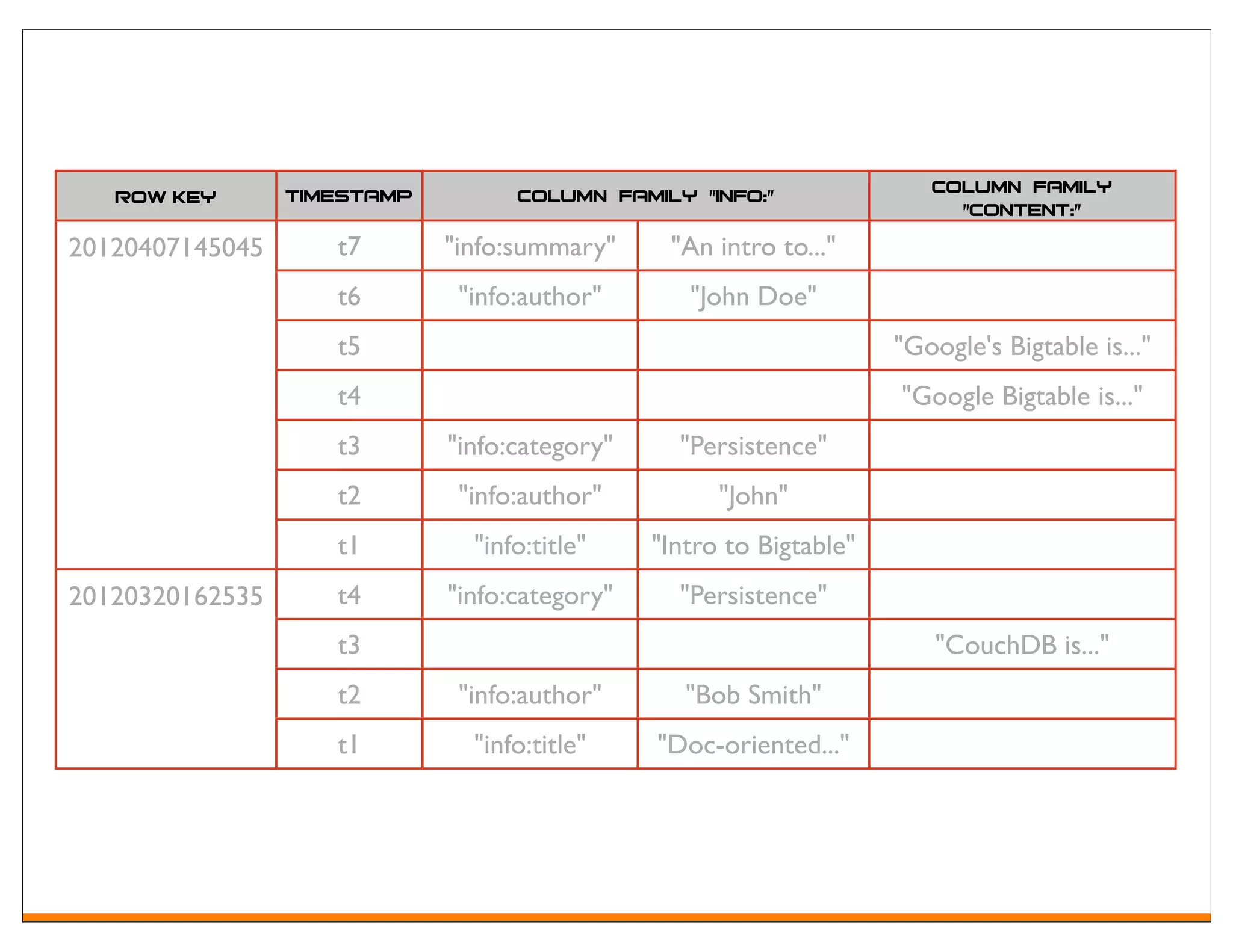
Apache HBase is an open-source, distributed, column-oriented storage system modeled after Google's Bigtable, designed to handle very large tables with billions of rows and millions of columns. It provides random, real-time read/write access, making it suitable for various big data applications. Key features include a sparse, multidimensional sorted map structure, versioning, and the ability to manage data through a row key, column key, and timestamp.








































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
