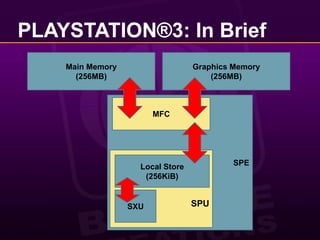
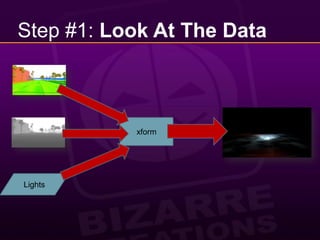
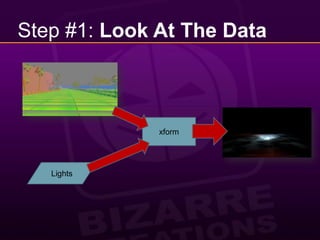
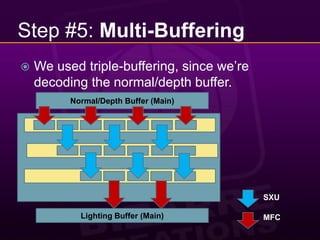
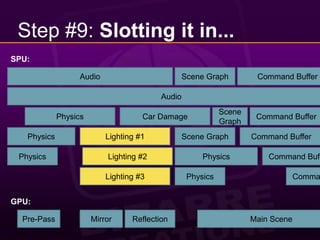
This document provides a 10 step guide for implementing real-time lighting on the PlayStation 3 (PS3) using its parallel architecture of 6 Synergistic Processing Units (SPUs). It discusses rendering a pre-pass to extract normals and depth, calculating lighting in a tile-based parallel manner on the SPUs, and compositing the final lighting texture. Special techniques like using atomics, striping data across SPUs, and maintaining pipeline balance are needed to optimize performance on the PS3's parallel architecture. The goal is to achieve real-time lighting for a game with 20 cars racing at night, while preserving picture quality and reducing frame latency to acceptable levels.







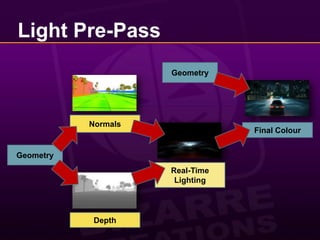
![Light Pre-PassMany people came up with this… so you know it’s good!Given its name by [Engel08].Credits also due to [Balestra08].Half-way between traditional and deferred rendering.](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-7-320.jpg)


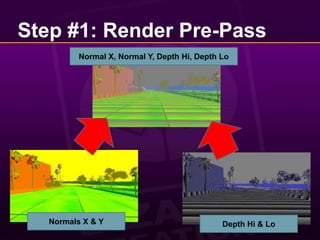
![Step #1: Render Pre-PassPack depth:Unpack depth:(Note: here fDepth is in [0, 1] range)half2 vPackedDepth = half2( floor(fDepth * 255.f) / 255.f,frac(fDepth * 255.f) );float fDepth =vPackedDepth.x + vPackedDepth.y * (1.f / 255.f);](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-11-320.jpg)
![Step #1: Render Pre-PassGet view space position from texture coordinates and depth:float3 vPosition = float3(g_vScale.xy * vUV + g_vScale.zw, 1.f) * fDepth;In some circumstances, possible to move this to the vertex shader.In [0, FarClip] rangeg_vScalemoves vUV into [-1, 1] range and scales by inverse projection matrix values](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-12-320.jpg)

![Step #2: The LightingWe render the lighting to an RGBA8 texture.Lighting is in [0, 1] range.We just about got away with range and precision issues.Two types of lights:Point lightsSpot lights](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-15-320.jpg)
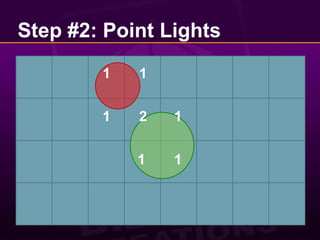
![Step #2: Point LightsFirst up, it’s the point lights turn.Let’s copy [Balestra08] and render them tiled.Split the screen into tiles:Big savings!Save on fill rate.Minimise overhead of unpacking view space position and normal.for each tile gather affecting lights select shader render tileend](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-16-320.jpg)



















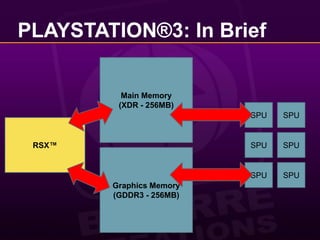
![Goals for PLAYSTATION®3Reduce overall frame latency to acceptable level (<33ms).Preserve picture quality (and resolution).Blur runs @ 720p on X360 and PS3.Preserve lighting accuracy.Lighting and main scene must match:Cars move fast... Deferring the lighting simply not an option, works great in [Swoboda09] though.](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-39-320.jpg)







![Step #6: Lighting (SOA)Pre-transpose lighting data, splat values across entire qword.16 byte aligned, single lqd.4 copies of world-space X, in each element of the arraystruct light{ float m_x[4]; float m_y[4]; float m_z[4]; float m_inv_radius_sq[4]; float m_colour_r[4]; float m_colour_g[4]; float m_colour_b[4];};Never actually used radius, pre-compute (1/radius)^2](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-50-320.jpg)










![References[Engel08] W. Engel, “Light Pre-Pass Renderer”, http://diaryofagraphicsprogrammer.blogspot.com/2008/03/light-pre-pass-renderer.html, accessed on 4th July 2009 [Balestra08] C. Balestra and P. Engstad, “The Technology of Uncharted: Drake’s Fortune”, GDC2008. [Swoboda09] M. Swoboda, “Deferred Lighting and Post Processing on PLAYSTATION®3”, GDC2009.](https://image.slidesharecdn.com/abizarrewaytodoreal-timelighting-100510065009-phpapp02/85/A-Bizarre-Way-to-do-Real-Time-Lighting-62-320.jpg)






































































