Downloaded 405 times











![Content-based side information
● VBPR: helping cold-start by augmenting item
factors with visual factors from CNNs [He et. al.,
2015]
● Content2Vec [Nedelec et. al., 2017]
● Learning to approximate MF item embeddings
from content [Dieleman, 2014]](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-15-320.jpg)
![Metadata-based side information
● Factorization Machines [Rendle, 2010] with
side-information
○ Extending the factorization framework to an arbitrary
number of inputs
● Meta-Prod2Vec [Vasile et. al., 2016]
○ Regularize item embeddings using side-information
● DCF [Li et al., 2016]
● Using associated textual information for
recommendations [Bansal et. al., 2016]](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-16-320.jpg)
![YouTube Recommendations
● Two stage ranker:
candidate generation
(shrinking set of items to
rank) and ranking
(classifying actual
impressions)
● Two feed-forward, fully
connected, networks with
hundreds of features
[Covington et. al., 2016]](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-17-320.jpg)

![Restricted Boltzmann Machines
● RBMs for Collaborative
Filtering [Salakhutdinov,
Minh & Hinton, 2007]
● Part of the ensemble that
won the $1M Netflix Prize
● Used in our rating
prediction system for
several years](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-19-320.jpg)
![Auto-encoders
● RBMs are hard to train
● CF-NADE [Zheng et al., 2016]
○ Define (random) orderings over conditionals
and model with a neural network
● Denoising auto-encoders: CDL [Wang et
al., 2015], CDAE [Wu et al., 2016]
● Variational auto-encoders [Liang et al.,
2017]](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-20-320.jpg)
![(*)2Vec
● Prod2Vec [Grbovic et al., 2015],
Item2Vec [Barkan & Koenigstein,
2016], Pin2Vec [Ma, 2017]
● Item-item co-occurrence
factorization (instead of user-item
factorization)
● The two approaches can be
blended [Liang et al., 2016]
prod2vec
(Skip-gram)
user2vec
(Continuous Bag of Words)](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-21-320.jpg)
![Wide + Deep models
● Wide model:
memorize
sparse, specific
rules
● Deep model:
generalize to
similar items via
embeddings
[Cheng et. al., 2016]
Deep Wide
(many parameters due
to cross product)](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-22-320.jpg)

![Sequence prediction
● Treat recommendations as a
sequence classification problem
○ Input: sequence of user actions
○ Output: next action
● E.g. Gru4Rec [Hidasi et. al., 2016]
○ Input: sequence of items in a
sessions
○ Output: next item in the session
● Also co-evolution: [Wu et al., 2017],
[Dai et al., 2017]](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-24-320.jpg)
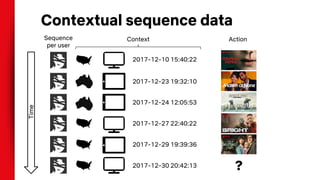
![Contextual sequence prediction
● Input: sequence of contextual user actions, plus
current context
● Output: probability of next action
● E.g. “Given all the actions a user has taken so far,
what’s the most likely video they’re going to play right
now?”
● e.g. [Smirnova & Vasile, 2017], [Beutel et. al., 2018]](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-25-320.jpg)

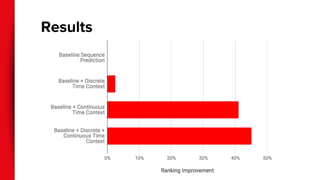
![Other framings
● Causality in recommendations
○ Explicitly modeling the consequence of a recommender systems’ intervention
[Schnabel et al., 2016]
● Recommendation as question answering
○ E.g. “I loved Billy Madison, My Neighbor Totoro, Blades of Glory, Bio-Dome,
Clue, and Happy Gilmore. I’m looking for a Music movie.” [Dodge et al., 2016]
● Deep Reinforcement Learning for
recommendations [Zhao et al, 2017]](https://image.slidesharecdn.com/deeplearningforrecommendersystems-180126172147/85/Deep-Learning-for-Recommender-Systems-29-320.jpg)





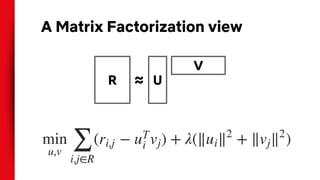
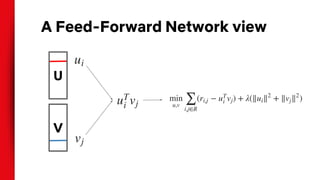
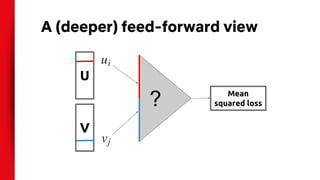
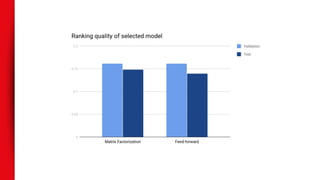
The document discusses the application of deep learning to recommender systems, highlighting its potential for personalized recommendations that enhance customer satisfaction and revenue. It compares traditional matrix factorization techniques with feed-forward networks, illustrating similar performance yet emphasizing the need for innovative approaches. The authors propose exploring alternative data inputs, sequence prediction models, and other problem framings to further improve recommendation systems using deep learning.












































































