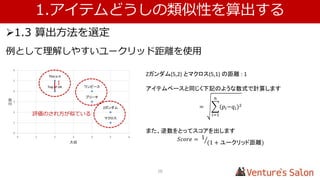
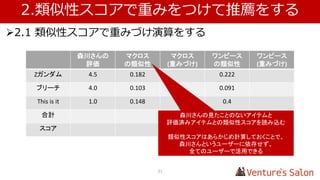
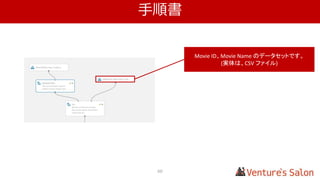
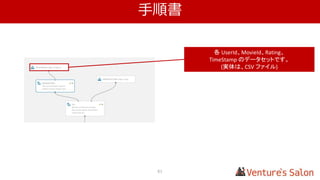
1.アイテムどうしの類似性を算出する
41
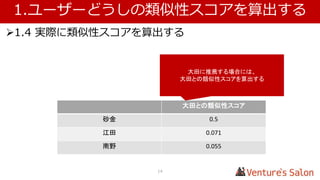
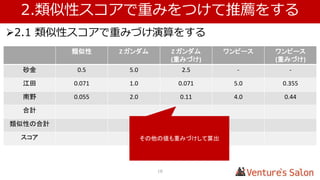
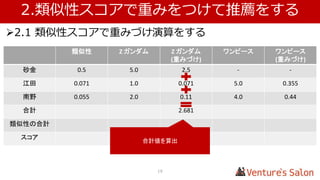
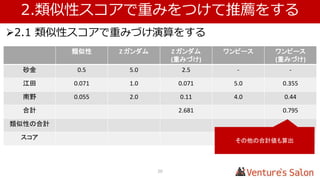
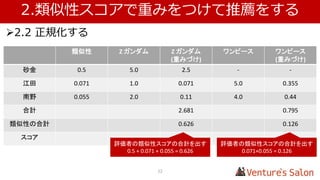
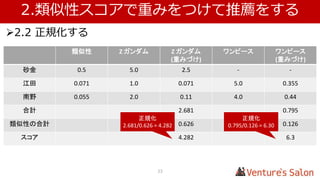
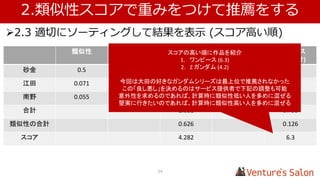
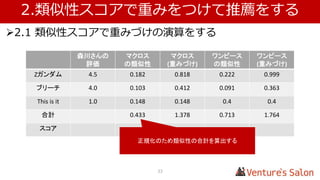
• 1.4 実際に類似性スコアを算出する
Zガンダム マクロス ・・・ Top of UK
Zガンダム - 0.182 0.012
マクロス 0.182 - 0.122
・・・
This is it 0.020 0.148 0.179
Top of UK 0.012 0.122 -
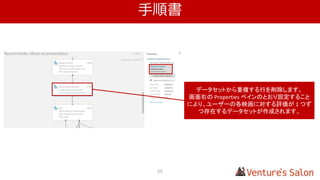
複数のユーザー、アイテムから算出した仮の値を表にしています
Azure MLの紹介
• MicrosoftAzure 上にホスト
されており環境構築が不要
• Microsoft Research の開発
した高度なモデルを無償で利
用可能
• Python, R で開発した独自プ
ログラムで拡張可能
• Web API として公開可能
59
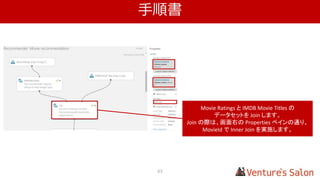
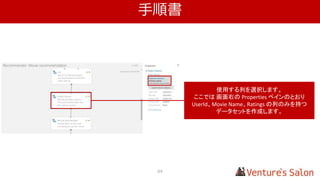
GUI ベースの機械学習ソリューション
59.
Training
Data
Web
Service
Azure Machine Learning
MicrosoftAzure
Webシステム
Azure Blob
ストレージ
Hive
Azure SQL Database
Azure テーブル
業務システム
HDInsight
( Hadoop )
他システム
Power View 等の
データ分析・可視化
ツール
Azure Blob
ストレージ
Azure SQL
Database
Batch Execution
Service
Request-Response
Service
評価モデル作成
(Training)
60

































































![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)












































