Recommended
PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」
PDF
PDF
PDF
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
PDF
PDF
PDF
【DL輪読会】GPT-4Technical Report
PDF
PPTX
PDF
PDF
Cosine Based Softmax による Metric Learning が上手くいく理由
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
PDF
PDF
【メタサーベイ】基盤モデル / Foundation Models
PDF
PPTX
トランザクションをSerializableにする4つの方法
PDF
PPTX
PPTX
PPTX
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
PPTX
[DL輪読会]Neural Ordinary Differential Equations
PDF
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
PPTX
検索評価ツールキットNTCIREVALを用いた様々な情報アクセス技術の評価方法
PDF
組み合わせテストの設計(PictMaster勉強会) 2008年7月17日
More Related Content
PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」
PDF
PDF
PDF
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
PDF
What's hot
PDF
PDF
【DL輪読会】GPT-4Technical Report
PDF
PPTX
PDF
PDF
Cosine Based Softmax による Metric Learning が上手くいく理由
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
PDF
PDF
【メタサーベイ】基盤モデル / Foundation Models
PDF
PPTX
トランザクションをSerializableにする4つの方法
PDF
PPTX
PPTX
PPTX
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
PPTX
[DL輪読会]Neural Ordinary Differential Equations
PDF
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
Similar to 情報アクセス技術のためのテストコレクション作成
PPTX
検索評価ツールキットNTCIREVALを用いた様々な情報アクセス技術の評価方法
PDF
組み合わせテストの設計(PictMaster勉強会) 2008年7月17日
PPTX
情報検索の基礎 #9適合フィードバックとクエリ拡張
PDF
PDF
平成24年度社会知能情報学専攻修士論文中間発表会(予稿)
PDF
[DSO]勉強会_データサイエンス講義_Chapter7
PDF
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP
PDF
Chapter 8 : Evaluation in Information Retrieval
PDF
マイニング探検会#09 情報レコメンデーションとは
PDF
PDF
PDF
マイニング探検会#31 情報検索システムのユーザーのニーズを考える
PDF
Introduction to Recommender Systems 2012.1.30 Zansa #3
PDF
PDF
PDF
PPTX
機械学習 / Deep Learning 大全 (3) 時系列 / リコメンデーション編
PDF
PPTX
More from kt.mako
PPTX
PPTX
PPTX
DEIM2017 私が愛したSIGIR Paper [京都大学 加藤誠]
PPTX
Context-guided Learning to Rank Entities
PDF
筑波大学 図書館情報メディア系 知識獲得システム 研究紹介
PDF
Two-layered Summaries for Mobile Search: Does the Evaluation Measure Reflect ...
PDF
NTCIR-12 MobileClick-2 Overview
PPTX
MobileClick-2 Kickoff Event
PPTX
Recently uploaded
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
PDF
PMBOK 7th Edition Project Management Process Scrum
PDF
PMBOK 7th Edition_Project Management Context Diagram
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
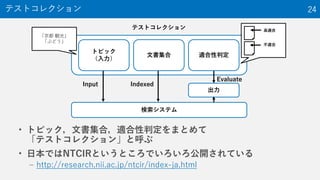
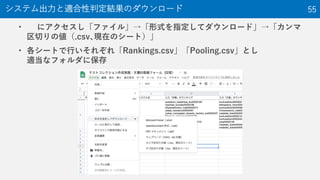
情報アクセス技術のためのテストコレクション作成 1. 2. 3. • 多くの研究の30%~40%は実験(≒評価)
– ある目的に対して本当に良い手段を採用しているかを
検証するには評価を行う必要がある
• 実サービスの方が評価を重視!?
– オンライン評価の論文の多くはMicrosoftと米Yahoo
– どのWebサービスでもA/Bテストは日常的に行われている
– サービスを改善しようと思ったら必ず定量化が求められる
• 現状のA手法と新しいB手法があった場合、B手法が採用されるかは評価次第
– An Academic in a Data Wonderland: Five Lessons from
Commercial Search @ NTCIR-14 Conference
• 評価を専門とする大学教授がFacebookで2年間エンジニアとして働いた経験を
共有
評価の重要性 3
4. 情報アクセス系の研究の評価 4
• 入力
– 検索: クエリ
– 推薦: 購買履歴
– 質問応答: 質問
• 出力
– 検索: 文書ランキング
– 推薦: 商品ランキング
– 質問応答: 回答
• 評価指標
– 検索・推薦: 適合率・再現率
– 質問応答: ROUGE
入力1 入力2
評価値1 評価値2
システム
出力1 出力2
評価指標
平均値
5. 6. 7. 8. 入力(2/2) 8
• クエリログからどのように入力
を選ぶか?
– 無作為抽出法 △
• 頻度を考慮しないとTailに偏る
• 頻度を考慮するとHeadに偏る
– 層化抽出法 ○
• カテゴリごと,頻度ごとにわけて,
適当な数を無作為に選択
• HeadやTailに特殊なクエリが多いこと
から,Torsoのみから選ぶ場合もある
頻度
クエリ
「情報検索 評価」「京都」
典型的なクエリログの度数分布
頻度無考慮
頻度考慮
頻度
クエリ
典型的なクエリログの度数分布
頻度ごとに
無作為抽出
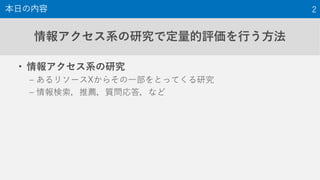
9. 10. <queries>
<query>
<qid>0001</qid>
<content>Halloween picture</content>
<description>Halloween is coming. You want to find some pictures about
Halloween to introduce it to your children.</description>
</query>
<query>
<qid>0002</qid>
<content>calendar</content>
<description>You need to find a convenient online calendar.</description>
</query>
<query>
<qid>0003</qid>
<content>women's clothing winter</content>
<description>Winter is coming. You want to look for information on women's
clothes for yourself.</description>
</query>
...
実例: NTCIR-14 WWW-2 Task 10
後述の適合性判定のために
情報要求を含めることもある
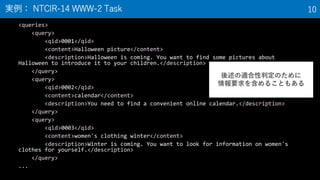
11. 12. • 適合性
– ある出力が情報要求を満たす度合い
• 特に「話題適合性」が用いられる
– 話題適合性: 情報要求によって必要とされる「話題」が,
ある出力にどの程度記述されているか
– 例: 情報要求「京都の観光地を知りたい」
• 適合度 高:金閣寺について書かれたページ
• 適合度 中:近畿の寺に全般について書かれたページ
• 適合度 低:通天閣について書かれたページ
• 近年では段階的適合性(高適合,部分適合,不適合など)が
広く用いられる
• 複数の評価者によって判定されるべき
適合性 12
13. 段階的適合性(NTCIR-9 INTENT-1 Taskの例) 13
• Highly relevant (2点)
– The document fully satisfies the
information need
• Relevant (1点)
– The document only partially
satisfies the information need
• Non-relevant (0点)
金閣寺
通天閣
出力
近畿の
お寺
Highly relevant
Relevant
Non-relevant
14. • 独立に得られた評価がどれくらい一致しているかを計算する
– Inter-rater agreementと呼ばれる
• 代表的な指標: カッパ係数 𝜅 =
𝑝 𝑜−𝑝 𝑒
1−𝑝 𝑒
• 段階的適合性の場合は重み付きカッパ係数などを利用
適合性判定の信頼性評価 14
評価者1が
適合と評価
評価者1が
不適合と評価
評価者2が
適合と評価 𝑎 =30 𝑏 =11
評価者2が
不適合と評価 𝑐 =10 𝑑 =60
𝑝 𝑜 =
𝑎+𝑑
𝑎+𝑏+𝑐+𝑑
(一致した割合)
𝑝 𝑒 = 𝑝 𝑒+ + 𝑝 𝑒− (たまたま一致する確率)
𝑝 𝑒+ =
𝑎+𝑐
𝑎+𝑏+𝑐+𝑑
𝑎+𝑏
𝑎+𝑏+𝑐+𝑑
𝑝 𝑒− =
𝑏+𝑑
𝑎+𝑏+𝑐+𝑑
𝑐+𝑑
𝑎+𝑏+𝑐+𝑑
15. • −1 ≤ 𝜅 ≤ 1で,目安としては
– < 0: no agreement
– 0–0.20: slight agreement
– 0.21–0.40: fair agreement
– 0.41–0.60: moderate agreement
– 0.61–0.80: substantial agreement
– 0.81–1: almost perfect agreement
• 個人的な感覚として,𝜅 < 0.6 の場合は以下の懸念がある
– 評価者の背景情報に大きく依存する
→評価を安定させるために評価者数を増やした方がいい
– 評価者に適合性判定の基準が伝わっていない
→評価の基準を明文化し説明を改善する
– 評価者が真面目に評価していない(クラウドソーシングなど)
→評価者数を十分に増やすか,評価者の採用基準を厳しくする
カッパ係数の解釈 15
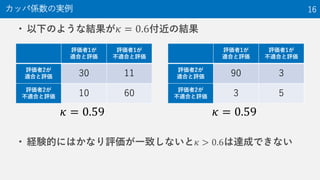
16. • 以下のような結果が 𝜅 = 0.6付近の結果
• 経験的にはかなり評価が一致しないと 𝜅 > 0.6は達成できない
カッパ係数の実例 16
評価者1が
適合と評価
評価者1が
不適合と評価
評価者2が
適合と評価 30 11
評価者2が
不適合と評価 10 60
評価者1が
適合と評価
評価者1が
不適合と評価
評価者2が
適合と評価 90 3
評価者2が
不適合と評価 3 5
𝜅 = 0.59 𝜅 = 0.59
17. • 出力の種類数が少ない場合
→出力されうるものすべてを適合性判定
– 例: 100種類の出力しかない場合
• 出力の種類数が少なくない場合
→複数システムの出力(の上位k件)をプーリング(和集合)
• プーリングで得られなかった出力は存在しなかったと考え
評価していくことになる
適合性判定の対象 17
入力1
システムA
システムB
1 3 6
6 8 1
1 3 6 8プーリング
出力
これを適合性判定の
対象とする
18. • 適合率
– P = (出力中の適合の数) / (出力数)
– 例: システムA’s P = 2/3,システムB’s P = 1/3
• 再現率
– R = (出力中の適合の数) / (すべての適合の数)
• すべての適合の数 = プーリングした結果中の適合の数,と考える
– 例: システムA’s P = 2/2,システムB’s P = 1/2
• 段階的適合性の場合はある段階以上を適合として計算
評価指標:適合率・再現率 18
入力1
システムA
システムB
1 3 6
6 8 1
1 3 6 8プーリング
出力 適合
19. • 上記の場合,システムA’s P = システムB’s P = 1/3
• 出力に順位がついている場合,
システムAの方をもっと高く評価したい
– システムAは1位に適合文書を順位付けできているため
– システムAの1位は高適合(2点)の文書であるため
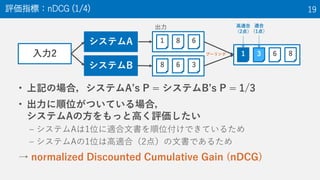
→ normalized Discounted Cumulative Gain (nDCG)
評価指標:nDCG (1/4) 19
入力2
システムA
システムB
1 8 6
8 6 3
1 3 6 8プーリング
出力 高適合
(2点)
適合
(1点)
20. • nDCG
– ランキングと段階的適合性を考慮した評価指標
– Web検索エンジンなどでも利用されている
DCG@𝑁 𝐝 =
𝑟=1
𝑁
𝑔(𝑑 𝑟)
1
log(𝑟 + 1)
nDCG@𝑁 𝐝 = DCG@𝑁(𝐝)/DCG@𝑁(𝐝∗
)
– 𝐝: 出力(ランキング)
– 𝐝∗
: 適合度が高い順に文書を並べて作った理想的な出力
– 𝑁: カットオフ(定数.この順位までの結果を考慮)
– 𝑑 𝑟: 𝐝の𝑟番目の文書(画像などでも良い)
– 𝑔(𝑑 𝑟): 𝐝の𝑟番目の文書の適合度
評価指標:nDCG (2/4) 20
21. • 𝑁 = 3とする, logの底を2とする(割愛するが底は結果に影響しない)
• DCG@3 システムAの出力 = 𝑔 𝑑1
1
log 1+1
+ 𝑔 𝑑2
1
log 2+1
+ 𝑔 𝑑3
1
log 3+1
= 2
1
log 2
+ 0
1
log 3
+ 0
1
log 4
=
2
log 2
= 2
• DCG@3 システムBの出力 = 𝑔 𝑑1
1
log 1+1
+ 𝑔 𝑑2
1
log 2+1
+ 𝑔 𝑑3
1
log 3+1
= 0
1
log 2
+ 0
1
log 3
+ 1
1
log 4
=
1
log 4
=
1
2
評価指標:nDCG (3/4) 21
入力2
システムA
システムB
1 8 6
8 6 3
1 3 6 8プーリング
出力 高適合
(2点)
適合
(1点)
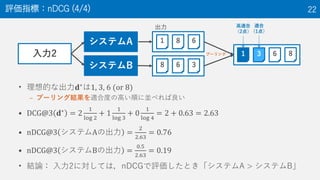
22. • 理想的な出力𝐝∗は1, 3, 6 (or 8)
– プーリング結果を適合度の高い順に並べれば良い
• DCG@3 𝐝∗
= 2
1
log 2
+ 1
1
log 3
+ 0
1
log 4
= 2 + 0.63 = 2.63
• nDCG@3 システムAの出力 =
2
2.63
= 0.76
• nDCG@3 システムBの出力 =
0.5
2.63
= 0.19
• 結論: 入力2に対しては,nDCGで評価したとき「システムA > システムB」
評価指標:nDCG (4/4) 22
入力2
システムA
システムB
1 8 6
8 6 3
1 3 6 8プーリング
出力 高適合
(2点)
適合
(1点)
23. 評価指標はたくさんあるので場合に応じて選べると良い 23
指標 AP RBP Q nDCG RR ERR
検索意図 Informational Navigational
適合性 二値 多値 多値 多値 二値 多値
正規化 ○ × ○ ○ ○ △ (nERR)
収穫逓減 × × × × ○ ○
判別能力 ○ × ○ ○ × ×
利用率 ◎ △ △ ◎ ◎ ○
• 正規化: 最大値が1に正規化されている
• 収穫逓減: ある文書が適合である場合,それより下位の文書の価値が低下
• 判別能力: 2つのシステムの優劣を判別できる能力
• 利用率: 加藤の主観
参考:「情報アクセス評価方法論: 検索エンジンの
進歩のために (コロナ社, 2015), 酒井哲也 著」
24. 25. • 入力を5個しか用意していない
– システムが研究対象ならアウト,ユーザが研究対象ならセーフ
• システムを1つしか用意していない
(関連研究がないから比較できない)
– 再現率やnDCGは複数システムがなければ意味をなさない指標
– 従来の手法に簡単な改良を加えて適用できないか考える
– 提案システムの特に工夫したところを除く,または,簡略化したシ
ステムを利用する
• プーリングをしないで各システムの出力を評価
– 典型的な事故
– 2つの評価対象が同じシステムから出力されたことがわかってしまう
場合,評価にバイアスがかかりやすい
よくある誤り・よくある質問 1/3 25
26. • 評価者が1人しかいない
– せめて2人,できれば3人以上の奇数人
– 2人いないと適合性判定の質をまったく補償できない
– 3人いると多数決ができるようになる
• nDCGの理想的な出力を1つのシステムの出力から作成
– 本当に多い致命的間違いNo. 1
– nDCGが高いとき(0.6を超えるなど)は注意
• 適合性の段階を100段階(100点満点)にした
– 再現性の面から問題が指摘されている
• 次の日,同じ人が同じ評価をしたときどれほど点数を再現可能か?
– 2, 3, 5段階あたりが広く用いられている
よくある誤り・よくある質問 2/3 26
27. • 「人が評価するなんて主観的で非科学的じゃないですか?」
– 検索は人が利用するシステムなので人が評価するのは当たり前
• そこまで人自体の研究が進んでいないとも言える
– 主観性と科学性がなぜか結びつけられるのは再現性が低いことに由来
すると思われるが,そのためのinter-rater agreement
• 「著者が評価して公正な評価ができるんですか?」
– プーリングが適切に行われていれば恣意的な評価の余地はあまりない
• 「評価者が2名しかいないのですか?」
「実利用者との乖離があるのではないですか?」
– 話題適合性の評価には個人差が入る余地はあまりない
– Inter-rater agreementが高ければ個人差が少ないと期待できる
よくある誤り・よくある質問 3/3 27
28. • 情報アクセス系の研究で定量的評価を行う方法を説明
• 入力
– 50-100個の入力を,可能であればログから層化抽出法によって選ぼう
• 適合性判定
– 2名以上の評価者に2~5段階の適合度を判定してもらおう
– 複数システムの出力をプーリングした結果に対して適合性判定を行おう
– Inter-rater agreementを計算して適合性判定の定量的評価をしよう
• 評価指標
– 段階適合度でランキングの評価を行う場合の最初の選択肢としてnDCG
を検討しよう
まとめ 28
29. 30. 31. 32. 33. • Windows
– スタートメニュー(左下のWindowsマーク)→「Anaconda Navigator」を
選択し,「Anaconda Navigator」が起動するか確認しましょう(起動に少
し時間がかかります)
• Mac
– Launchpad→「Anaconda Navigator」を選択し,「Anaconda Navigator」
が起動するか確認しましょう(起動に少し時間がかかります)
インストールされたAnacondaの確認(共通) 33
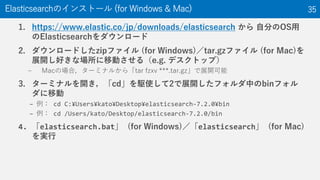
34. 35. 1. https://www.elastic.co/jp/downloads/elasticsearch から 自分のOS用
のElasticsearchをダウンロード
2. ダウンロードしたzipファイル (for Windows)/tar.gzファイル (for Mac)を
展開し好きな場所に移動させる(e.g. デスクトップ)
– Macの場合,ターミナルから「tar fzxv ***.tar.gz」で展開可能
3. ターミナルを開き,「cd」を駆使して2で展開したフォルダ中のbinフォル
ダに移動
– 例: cd C:¥Users¥kato¥Desktop¥elasticsearch-7.2.0¥bin
– 例: cd /Users/kato/Desktop/elasticsearch-7.2.0/bin
4. 「elasticsearch.bat」 (for Windows)/「elasticsearch」 (for Mac)
を実行
Elasticsearchのインストール (for Windows & Mac) 35
36. 37. 38. 39. • Docker
– コンテナ管理ソフトウェア
– コンテナ: 依存し合う複数のリソースをまとめたもの
• 以下,Mac/Linuxユーザ,および,Windows 10 Proユーザ
向けの手順(Windows 10 Homeは未対応)
Docker編(上級者?向け) 39
コンテナ
Elasticsearch
Java elasticsearch.yml
• 従来
– 持ち運びがしにくい
– 別の環境で構築するのが面倒(今回のケース)
• Docker
– コンテナ単位で共有可能
– 別の環境で構築が容易
40. • Windows(難易度高)
– 要件
• Windows 10 64bit: Pro, Enterprise or Education, 4GB以上のメモリ,
• 仮想化の有効化: https://docs.docker.com/docker-for-
windows/troubleshoot/#virtualization-must-be-enabled
– ダウンロード
• https://hub.docker.com/editions/community/docker-ce-desktop-windows
• Mac (難易度易)
– 要件
• 2010年以降のMac,macOS Sierra 10.12以降のmacOS,4GB以上のメモリ,
VirtualBox 4.3.30以前がインストールされていないこと
– ダウンロード
• https://hub.docker.com/editions/community/docker-ce-desktop-mac
Dockerのインストール (for Docker) 40
41. # versionは多少異なる.先頭の「$」は入力しない
$ docker --version
Docker version 18.09, build c97c6d6
$ docker-compose --version
docker-compose version 1.24.0, build 8dd22a9
$ docker-machine –version
docker-machine version 0.16.0, build 9ba6da9
Dockerがインストールされているか確認(for Docker) 41
42. # 以下を入力し「Hello from Docker!」とでれば成功
$ docker run hello-world
Hello from Docker!
This message shows that your installation appears to
be working correctly.
hello-world Dockerイメージの起動(for Docker) 42
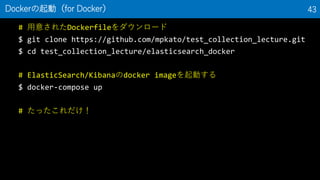
43. # 用意されたDockerfileをダウンロード
$ git clone https://github.com/mpkato/test_collection_lecture.git
$ cd test_collection_lecture/elasticsearch_docker
# ElasticSearch/Kibanaのdocker imageを起動する
$ docker-compose up
# たったこれだけ!
Dockerの起動(for Docker) 43
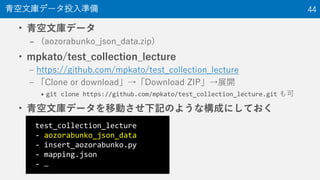
44. • 青空文庫データ
– (aozorabunko_json_data.zip)
• mpkato/test_collection_lecture
– https://github.com/mpkato/test_collection_lecture
– 「Clone or download」→「Download ZIP」→展開
• git clone https://github.com/mpkato/test_collection_lecture.git も可
• 青空文庫データを移動させ下記のような構成にしておく
青空文庫データ投入準備 44
test_collection_lecture
- aozorabunko_json_data
- insert_aozorabunko.py
- mapping.json
- …
45. $ python insert_aozorabunko.py
Index 'aozorabunko' has been deleted
Index 'aozorabunko' has been initialized
Inserting data from
'/Users/kato/dev/aozorabunko_json_data/aozorabunko.json.000' ...
Inserted 20000 documents
Inserting data from
'/Users/kato/dev/aozorabunko_json_data/aozorabunko.json.001' ...
Inserted 20000 documents
…
Inserted 199923 documents in total
青空文庫のデータを投入(共通) 45
46. 47. • 下記の4都市を入力とする:
– 京都
– 大阪
– 渋谷
– 札幌
• 適合度の基準
– 高適合 (2点)
• 町の様子の詳細が描かれている
– 部分適合 (1点)
• 町の様子が少しだけ描かれている
– 不適合 (0点)
• 町の様子が描かれていない
入力・適合度の基準 47
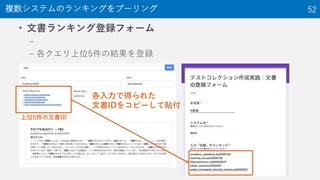
48. • システム1: 都市名をそのままクエリとして利用
– 京都→「京都」
– 大阪→「大阪」
– 渋谷→「渋谷」
– 札幌→「札幌」
• システム2, …,システムk: 都市名に単語Tを追加
– 京都→「京都 T」
– 大阪→「大阪 T」
– 渋谷→「渋谷 T」
– 札幌→「札幌 T」
– 例: 「町」を追加
• 京都→「京都 町」
• 大阪→「大阪 町」
• 渋谷→「渋谷 町」
• 札幌→「札幌 町」
比較対象システム 48
49. • Elasticsearchのデフォルトランキング手法はBM25
– BM25 (Okapi BM25): https://en.wikipedia.org/wiki/Okapi_BM25
– あるクエリ𝑞に対し,文書を以下の式の値が高い順にランキング
• score 𝑞, 𝑑 = 𝑖=1
𝑞
IDF 𝑞𝑖
TF 𝑞 𝑖,𝑑 (𝑘1+1)
TF 𝑞 𝑖,𝑑 +𝑘1 1−𝑏+𝑏
𝑑
avgd
– IDF 𝑞𝑖 = log
𝑁−DF 𝑞 𝑖 +0.5
DF 𝑞 𝑖 +0.5
– 𝑞𝑖: クエリ𝑞の𝑖番目の単語( 𝑞 はクエリ中の単語数)
– 𝑑: 文書( 𝑑 は文書長=文書中の単語数)
– DF 𝑞𝑖 : ある文書コーパス中で単語𝑞𝑖を含む文書数
– 𝑁: ある文書コーパス中の文書数
– TF 𝑞𝑖, 𝑑 : 文書𝑑における単語𝑞𝑖の出現頻度
– 𝑘1, 𝑏: パラメータ(デフォルト: 𝑘1 = 1.2, 𝑏 = 0.75)
– avgd: ある文書コーパス中の文書長の平均
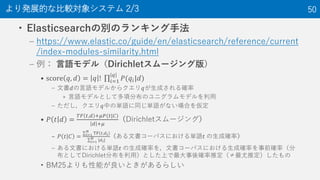
より発展的な比較対象システム 1/3 49
50. 51. • 言語モデル(Dirichletスムージング版)を利用する
• ranking.json
• 上記”type”を好きなランキング手法に変え
update_ranking.py を実行すればランキング手法が変わる
– ただし, 単語を追加する方法と併用すること
• 1語のクエリの場合,ほとんど変化がないため
より発展的な比較対象システム 3/3 51
{
"index": {
"similarity": {
"default": {
"type": "LMDirichlet"
}
}
}
}
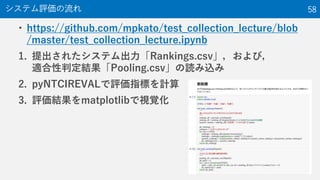
52. 53. 54. • 評価指標の計算
• pyNTCIREVAL
– README: https://github.com/mpkato/pyNTCIREVAL
– pyNTCIREVAL is a python version of NTCIREVAL developed by
Dr. Tetsuya Sakai http://www.f.waseda.jp/tetsuya/sakai.html
– ランキング評価のためのツール
• 日本語のグラフを書く準備
必要なPython Package (ライブラリ)のインストール 54
$ pip install pyNTCIREVAL
$ pip install japanize-matplotlib
55. 56. 57. 58. 59.























































![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSO]勉強会_データサイエンス講義_Chapter7](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter7-191122112044-thumbnail.jpg?width=640&height=640&fit=bounds)
















![DEIM2017 私が愛したSIGIR Paper [京都大学 加藤誠]](https://cdn.slidesharecdn.com/ss_thumbnails/deim2017-kato-my-favorite-sigir-paper-public-170429063024-thumbnail.jpg?width=640&height=640&fit=bounds)


















