Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Sho Shimauchi
ODP, PDF
735 views
Programming Collective Intelligence 100111
"Programming Collective Intelligence" reading party, Chapter 2: Recommendation
Technology
◦
Read more
4
Save
Share
Embed
Embed presentation
Download
Downloaded 10 times
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
Data-Intensive Text Processing with MapReduce ch6.1
by
Sho Shimauchi
PDF
Cloudera Impala #pyfes 2012.11.24
by
Sho Shimauchi
PPTX
Hadoop summit 2012 report
by
Sho Shimauchi
PPTX
Incredere
by
MinuneMica Project
ODP
Programming Collective Intelligence 100131
by
Sho Shimauchi
PPTX
Calendar 2010
by
MinuneMica Project
PDF
Clarity Profile
by
Rajesh Pandey
PDF
Code complete ch22_developper_test
by
Sho Shimauchi
Data-Intensive Text Processing with MapReduce ch6.1
by
Sho Shimauchi
Cloudera Impala #pyfes 2012.11.24
by
Sho Shimauchi
Hadoop summit 2012 report
by
Sho Shimauchi
Incredere
by
MinuneMica Project
Programming Collective Intelligence 100131
by
Sho Shimauchi
Calendar 2010
by
MinuneMica Project
Clarity Profile
by
Rajesh Pandey
Code complete ch22_developper_test
by
Sho Shimauchi
Viewers also liked
ODP
Decotai Shiumachi 091228
by
Sho Shimauchi
PPTX
My Immortal
by
MinuneMica Project
ODP
Decotai Shiumachi 091206
by
Sho Shimauchi
PDF
Data-Intensive Text Processing with MapReduce ch4
by
Sho Shimauchi
PDF
使い捨て python コードの書き方
by
Sho Shimauchi
PDF
20分でわかるHBase
by
Sho Shimauchi
PDF
Fabric + Amazon EC2で快適サポート生活 #PyFes
by
Sho Shimauchi
ODP
Hadoop for programmer
by
Sho Shimauchi
PPTX
Mantra Tara Verde
by
MinuneMica Project
PPT
Christmas Spirit in Romania
by
MinuneMica Project
PPTX
浅野高等学校 2015年度 卒業生講演
by
Sho Shimauchi
Decotai Shiumachi 091228
by
Sho Shimauchi
My Immortal
by
MinuneMica Project
Decotai Shiumachi 091206
by
Sho Shimauchi
Data-Intensive Text Processing with MapReduce ch4
by
Sho Shimauchi
使い捨て python コードの書き方
by
Sho Shimauchi
20分でわかるHBase
by
Sho Shimauchi
Fabric + Amazon EC2で快適サポート生活 #PyFes
by
Sho Shimauchi
Hadoop for programmer
by
Sho Shimauchi
Mantra Tara Verde
by
MinuneMica Project
Christmas Spirit in Romania
by
MinuneMica Project
浅野高等学校 2015年度 卒業生講演
by
Sho Shimauchi
Similar to Programming Collective Intelligence 100111
PDF
JOI夏季セミ2014、集合知プログラミング_2、5
by
Kai Katsumata
PDF
Introduction to Recommender Systems 2012.1.30 Zansa #3
by
Atsushi KOMIYA
PDF
ゼロから始めるレコメンダシステム
by
Kazuaki Tanida
PDF
集合知プログラミング第2章推薦を行う
by
Hiroko Onari
PDF
情報推薦システム入門:講義スライド
by
Kenta Oku
PDF
協調フィルタリング入門
by
hoxo_m
PDF
協調フィルタリングを利用した推薦システム構築
by
Masayuki Ota
PPTX
WebDB Forum 2015 pinterest webpagever
by
helro
PDF
yamasita m
by
harmonylab
PDF
SQLで身につける!初めてのレコメンド 〜 基礎から応用まで ~
by
Naoto Tamiya
PDF
レコメンデーション(協調フィルタリング)の基礎
by
Katsuhiro Takata
PDF
Collaborativefilteringwith r
by
Teito Nakagawa
PDF
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
PDF
Ppt yamashita
by
harmonylab
PDF
レコメンドアルゴリズムの基礎と「B-dash」におけるシステム構成の紹介
by
Takeshi Mikami
PPTX
レコメンド研究のあれこれ
by
Masahiro Sato
PPT
レコメンドしてみよう!
by
Kazuya Obanayama
PDF
マイニング探検会#09 情報レコメンデーションとは
by
Yoji Kiyota
PDF
MP Joinを使った類似データ抽出
by
JAVA DM
PPTX
Recommend system
by
ilove2dgirl
JOI夏季セミ2014、集合知プログラミング_2、5
by
Kai Katsumata
Introduction to Recommender Systems 2012.1.30 Zansa #3
by
Atsushi KOMIYA
ゼロから始めるレコメンダシステム
by
Kazuaki Tanida
集合知プログラミング第2章推薦を行う
by
Hiroko Onari
情報推薦システム入門:講義スライド
by
Kenta Oku
協調フィルタリング入門
by
hoxo_m
協調フィルタリングを利用した推薦システム構築
by
Masayuki Ota
WebDB Forum 2015 pinterest webpagever
by
helro
yamasita m
by
harmonylab
SQLで身につける!初めてのレコメンド 〜 基礎から応用まで ~
by
Naoto Tamiya
レコメンデーション(協調フィルタリング)の基礎
by
Katsuhiro Takata
Collaborativefilteringwith r
by
Teito Nakagawa
Amebaにおけるレコメンデーションシステムの紹介
by
cyberagent
Ppt yamashita
by
harmonylab
レコメンドアルゴリズムの基礎と「B-dash」におけるシステム構成の紹介
by
Takeshi Mikami
レコメンド研究のあれこれ
by
Masahiro Sato
レコメンドしてみよう!
by
Kazuya Obanayama
マイニング探検会#09 情報レコメンデーションとは
by
Yoji Kiyota
MP Joinを使った類似データ抽出
by
JAVA DM
Recommend system
by
ilove2dgirl
Programming Collective Intelligence 100111
1.
集合知プログラミング Programming Collective
Intelligence (Ch.2 推薦を行う) 2010/01/11 id:shiumachi
2.
Agenda 2.1
協調フィルタリング
3.
2.2 嗜好の収集
4.
2.3 似ているユーザを探し出す
5.
2.4 アイテムを推薦する
6.
2.5 似ている製品
7.
2.6 del.icio.us
のリンクを推薦するシステムを作る
8.
2.7 アイテムベースのフィルタリング
9.
2.8 MovieLens
のデータセットを使う
10.
2.9 ユーザベース
VS アイテムベース
11.
2.10 練習問題
12.
2.1 協調フィルタリング
13.
協調フィルタリングとは? “協調フィルタリング(Collaborative Filtering,
CF)は、多くのユーザの嗜好情報を蓄積し、あるユーザと嗜好の類似した他のユーザの情報を用いて自動的に推論を行う方法論である” (wikipedia より)
14.
1992年、Xerox PARC の
David Goldberg の論文で初めて使われた用語
15.
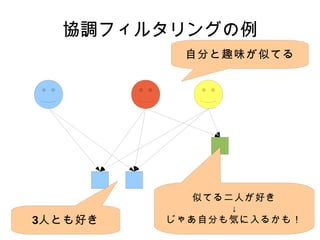
協調フィルタリングの例 3 人とも好き
自分と趣味が似てる 似てる二人が好き ↓ じゃあ自分も気に入るかも!
16.
2.2 嗜好の収集
17.
基本はデータ データがないと話にならない
18.
必要なデータは次の3つ ユーザ
19.
アイテム
20.
スコア スコアは Y/N
を 1/0 に変換するなどしてもいい。(ソーシャルブックマークなどではこの手法を使う)
21.
スコアの分類 スコアがたくさん出てくるから混乱しないよう注意
22.
アイテムのスコア 前述のスコア 類似性スコア
ユーザ間、アイテム間の類似性を表す指標 推薦スコア(shiumachiの造語) 推薦対象のユーザに対してどれだけ強く推薦するかを表す指標
23.
2.3 似ているユーザを探し出す
24.
類似性スコアの算出方法 協調フィルタリングのキモだが、方法はたくさんある http://ja.wikipedia.org/wiki/距離空間
を参照のこと
25.
テキストで取り上げているのは以下の2つ ユークリッド距離
26.
ピアソン相関 ここでいいスコアが出たユーザの嗜好を推薦するのがレコメンデーションの第一歩となる
27.
ユークリッド距離 ごく普通の距離。
28.
ユーザ間の、アイテムごとのスコアの差の2乗の和の平方根。
29.
データが正規化されていないと正しい類似性が得にくい。
30.
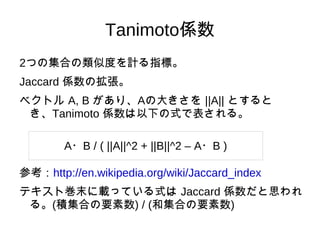
ピアソン相関係数 ユーザ間のスコアをそれぞれ x,y
とおき、標準偏差をσ(x), 共分散を V(x,y) とすると、ピアソン相関係数は V(x,y)/σ(x)σ(y) となる。
31.
-1 ~ 1
の値をとる。
Download