Download as PDF, PPTX



![High Dimension Example: Sample Generation
→
data samples
[Berthelot et al. 2017, BEGAN]
3/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-5-320.jpg)
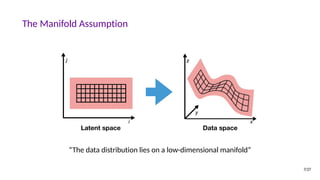
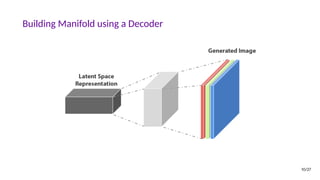
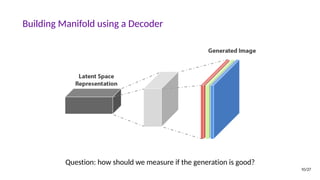
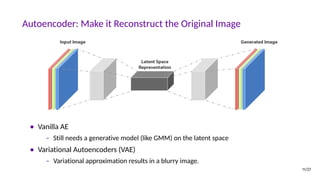
![Why Study Generative Models?
• Test of our ability to use high-dimensional, complicated probability distributions
• Simulate possible futures for planning or reinforcement learning
• Missing data, semi-supervised learning
• Multi-modal outputs
• Realistic generation tasks
[Goodfellow, NIPS 2016 Tutorial]
4/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-6-320.jpg)
![Latent Space Interpolation
[Berthelot et al. 2017, BEGAN]
8/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-11-320.jpg)
![Latent Space Arithmetic
[Radford et al. 2015, DCGAN]
9/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-12-320.jpg)
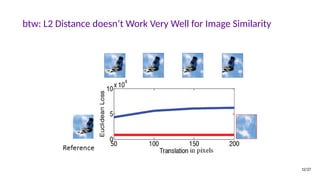
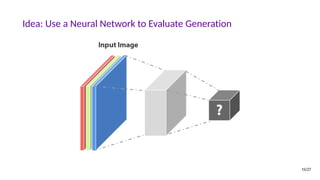
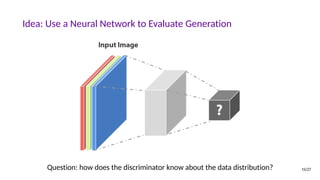
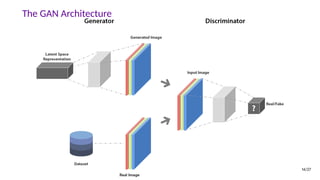
![The GAN Formula
min
G
max
D
[︁
Ex∼pdata log D(x) + Ez∼pz log (1 − D(G(z)))
]︁
(1)
• A minimax game between the generator and the discriminator.
• In practice, a non-saturating variant is often used for updating G:
max
G
Ez∼pz log D(G(z)) (2)
[Goodfellow et al. 2014, Generative Adversarial Nets]
15/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-20-320.jpg)
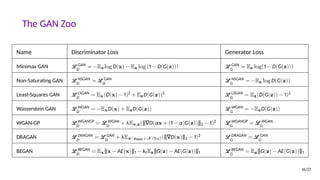


![Projection Discriminator
[Miyato & Koyama, 2018] 20/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-25-320.jpg)
![GANs with Encoder
features data
z G G(z)
xEE (x)
G(z), z
x, E (x)
D P (y)
[Donahue et al., 2017, Dumoulin et al., 2017]
21/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-26-320.jpg)
![Superresolution
bicubic SRResNet SRGAN original
(21.59dB/0.6423) (23.53dB/0.7832) (21.15dB/0.6868)
[Ledig et al., 2016]
22/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-27-320.jpg)
![Image-to-Image Translation
[Zhu et al., 2016] 23/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-28-320.jpg)
![WaveGAN and Speech Enhancement GAN
Phase shuffle n=1
-1 0 +1
[Donahue et al. 2018, Pascual et al. 2017]
24/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-29-320.jpg)
![Reasons to Love GANs
• GANs set up an arms race
• GANs can be used as a “learned loss function”
• GANs are “meta-supervisors”
• GANs are great data memorizers
• GANs are democratizing computer art
[Alexei A. Efros, CVPR 2018 Tutorial]
25/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-30-320.jpg)
![MSE and MAE do not Account for Multi-Modality
[Sønderby et al., 2017]
26/27](https://image.slidesharecdn.com/gan-tutorial-191104101530/85/A-Short-Introduction-to-Generative-Adversarial-Networks-31-320.jpg)


Generative adversarial networks (GANs) are a class of machine learning frameworks where two neural networks compete against each other. One network generates new data instances, while the other evaluates them for authenticity. This adversarial process allows the generating network to produce highly realistic samples matching the training data distribution. The document discusses the GAN framework, various algorithm variants like WGAN and BEGAN, training tricks, applications to image generation and translation tasks, and reasons why GANs are a promising area of research.








































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)

