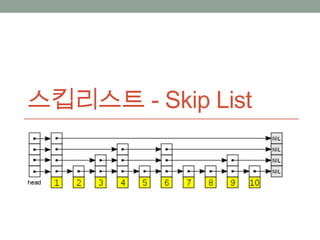
스킵리스트: 확률적 자료구조크기의확률분포를 유지하기!노드 중 ½은 포인터 1개를 가짐노드 중 ¼은 포인터 2개를 가짐노드 중 1/2i은 포인터 i개를 가짐규칙적인 패턴을 유지할 필요가 없어짐하지만 여전히 높은 확률로 Log N시간에 동작함struct Node<T> { T key; Node<T> *forward[];};
매개변수 pi개의 포인터를가진 노드가r 개라면pr개의 노드는i+1개의 포인터를 가짐앞의 예제에서는 p = ½ p = ½일 때 가장 속도가 빠르다!적당한 속도와 메모리 효율을 위해 p = ¼ 를 권장포인터의 최대 개수는 log1𝑝𝑁개가 적당대부분의 구현에서는 최대 개수를 20개 정도로 고정함
노드 제거하기같은 방식으로BackLook배열을 유지하면서 탐색제거하면서 앞뒤의 포인터를 이어줌어차피 랜덤이므로 노드 크기의 분포 유지엔 영향이 없음
15.
최악의 경우 O(N)이 되지만모든 노드의 크기가 같아지면 보통 리스트와 동일하게 됨.하지만 길이 100짜리 리스트가 그렇게 될 확률은?동전을 100번 던졌을 때 전부 앞면만 나올 확률로또1등먹을 확률!검색시간이 기대값(Log N)의 3배 이상 걸릴 확률은 엄청나게 낮다!
스킵리스트는 병렬프로그래밍에 유리함락이길어질 확률은 매우 빠르게 작아지기 때문에 불규칙한 락 때문에 모든 스레드가 멈춰버릴 확률이 적다.락을 포인터/노드별로로컬하게 걸 수 있어서 충돌의 위험이 더욱 작다.하지만 Persistent하게 만들기는 트리보다 어렵다.
20.
언제 스킵리스트를 쓸까?멀티스레드에서자주 수정할 컨테이너가 필요할 때순차적으로 탐색할 필요가 많은 경우 예 : 타임라인상의 이벤트 관리정렬할 필요가 없을 땐 해쉬테이블을 쓰는 것이 좋음cache miss/fragmentation 등으로 인해 B-Tree보다 느리게 동작하는 경우도 있으므로 신중한 결정이 필요함
21.
스킵리스트의 변형들Indexed SkipList엣지마다 길이를 저장해서 인덱스 접근이 가능Deterministic Skip List최악의 경우에도Log시간이지만 패턴 유지를 위한 비용이 필요함1-2 skip list바로 아래 레벨의 노드2개 이상을 지나가지 않도록 유지 2-3 tree 에 대응1-2-3 skip list
22.
스킵리스트 구현들Redis (BSD)스킵리스트를이용한 key-value 저장 서버 (ANSI C)JAVA 1.6의 ConcurrentSkipListMap, Set스킵리스트를 이용해 구현한 멀티스레드를 지원하는 map과 setSkipdb (BSD)B-Tree대신 스킵리스트를 사용해서 구현한 버클리DB 방식의 DBQt의 Qmap (GPL, LGPL)Qt Framework중 GUI와 관계없는 기능을 모은 QtCore모듈에 있음STL map과 유사한 방식으로 사용 가능
23.
ReferencePugh, William (June1990). "Skip lists: a probabilistic alternative to balanced trees".Pugh, William (July 1989). “A Skip List Cookbook” Herlihy et. al. “A Probably Correct Concurrent Skip List”Fraser and Harris (2004). “Concurrent Programming Without Locks”Wikipedia : Skip List

![스킵리스트는 젊다!1960198019701990Treap[Aragon &Seidel]R Tree[Guttman] AVL Tree[Avdelson-Velskii &Landis]RB TreeB Tree[Bayer]Splay Tree[Sleator& Tarjan]Skip List](https://image.slidesharecdn.com/skiplist-110614065807-phpapp01/85/Skip-List-3-320.jpg)




![스킵리스트: 확률적 자료구조크기의 확률분포를 유지하기!노드 중 ½은 포인터 1개를 가짐노드 중 ¼은 포인터 2개를 가짐노드 중 1/2i은 포인터 i개를 가짐규칙적인 패턴을 유지할 필요가 없어짐하지만 여전히 높은 확률로 Log N시간에 동작함struct Node<T> { T key; Node<T> *forward[];};](https://image.slidesharecdn.com/skiplist-110614065807-phpapp01/85/Skip-List-8-320.jpg)





























![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[NDC 16] 당신은 사랑 받기 위해 태어난 사람: 3년차 게임 디자이너의 자존감 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc16-160426032009-thumbnail.jpg?width=640&height=640&fit=bounds)




![[1B4]안드로이드 동시성_프로그래밍](https://cdn.slidesharecdn.com/ss_thumbnails/1b4-140928080341-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[데브루키]노대영_알고리즘 스터디](https://cdn.slidesharecdn.com/ss_thumbnails/devrookiealgorithm-180926091907-thumbnail.jpg?width=640&height=640&fit=bounds)

![[TAOCP] 2.5 동적인 저장소 할당](https://cdn.slidesharecdn.com/ss_thumbnails/taocp2-5-110603152000-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2CAMPUS] Algorithm tips - ALGOS](https://cdn.slidesharecdn.com/ss_thumbnails/algospart1-d2-170223060957-thumbnail.jpg?width=640&height=640&fit=bounds)






![[SOPT] 데이터 구조 및 알고리즘 스터디 - #01 : 개요, 점근적 복잡도, 배열, 연결리스트](https://cdn.slidesharecdn.com/ss_thumbnails/1-150824001021-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 campus]Key-value store 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/d2campuskeyvaluestore-150822042537-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)