Download as PDF, PPTX













![Coming in Spark 1.6
Dataset API: typed interface over DataFrames / Tungsten
• Common ask from developerswho saw DataFrames
case class Person(name: String, age: Int)
val dataframe = read.json(“people.json”)
val ds: Dataset[Person] = dataframe.as[Person]
ds.filter(p => p.name.startsWith(“M”))
.groupBy(“name”)
.avg(“age”)](https://image.slidesharecdn.com/europe2015-151028150748-lva1-app6891/75/Spark-Summit-EU-2015-Matei-Zaharia-keynote-19-2048.jpg)



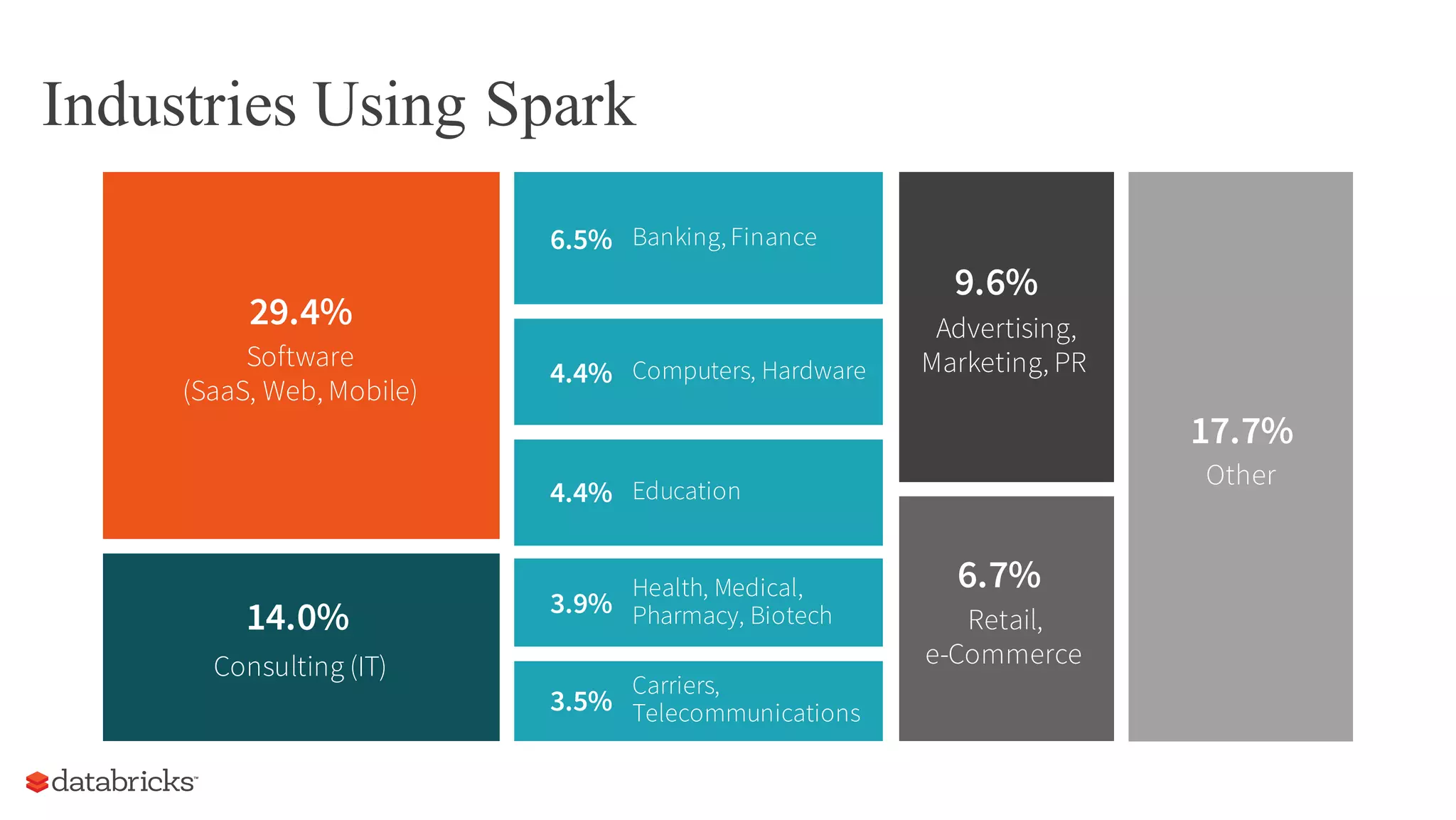
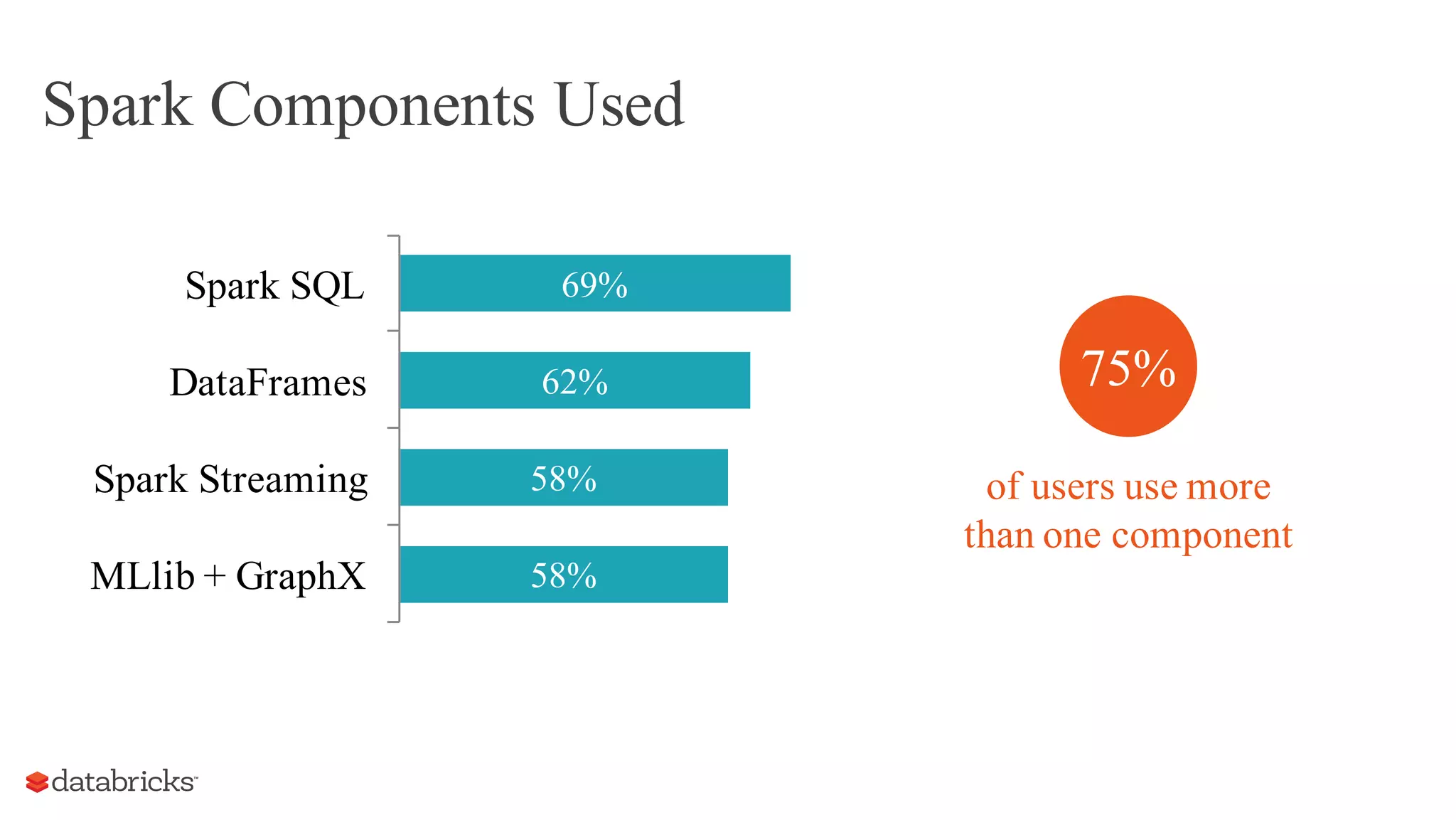
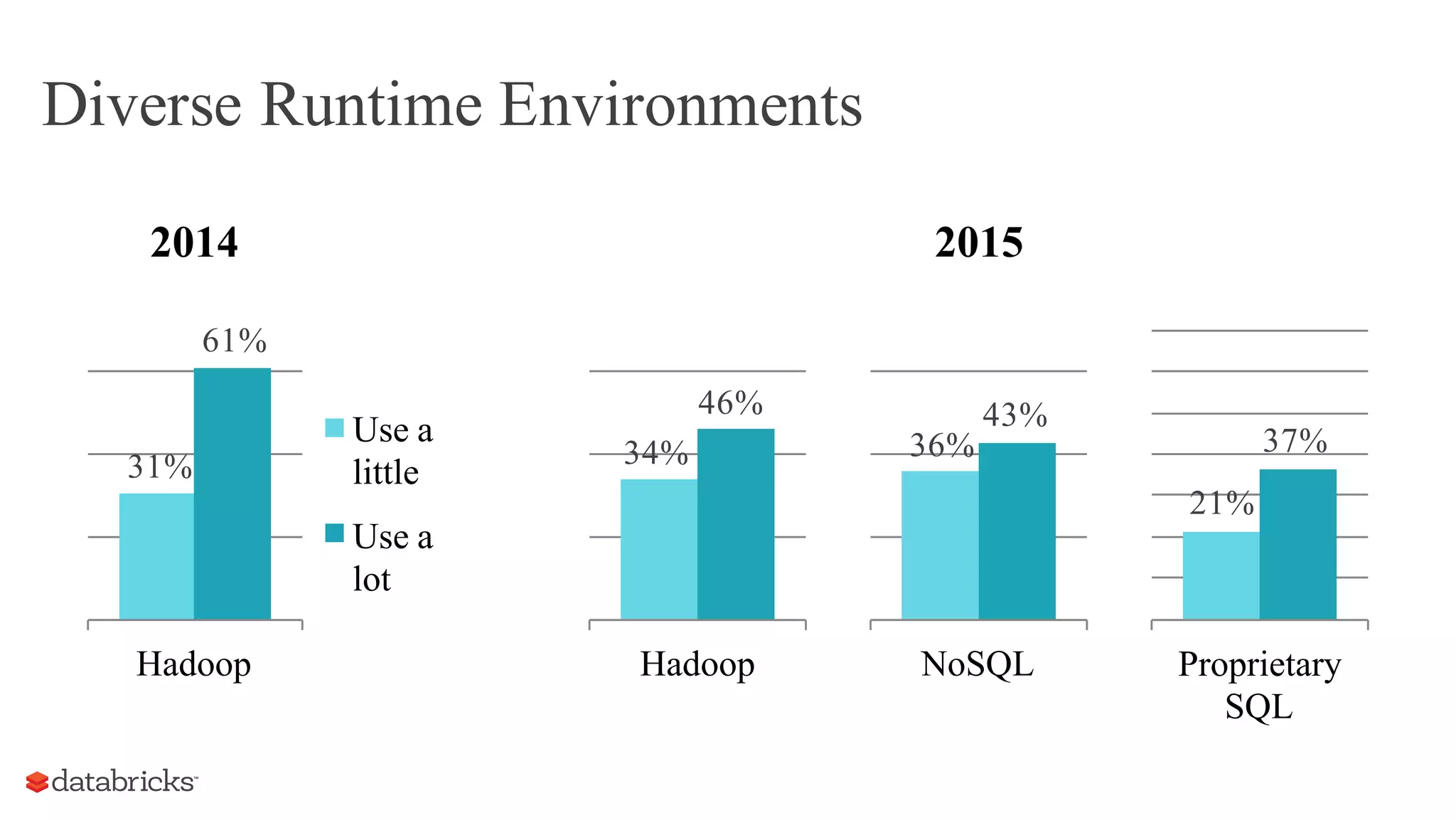
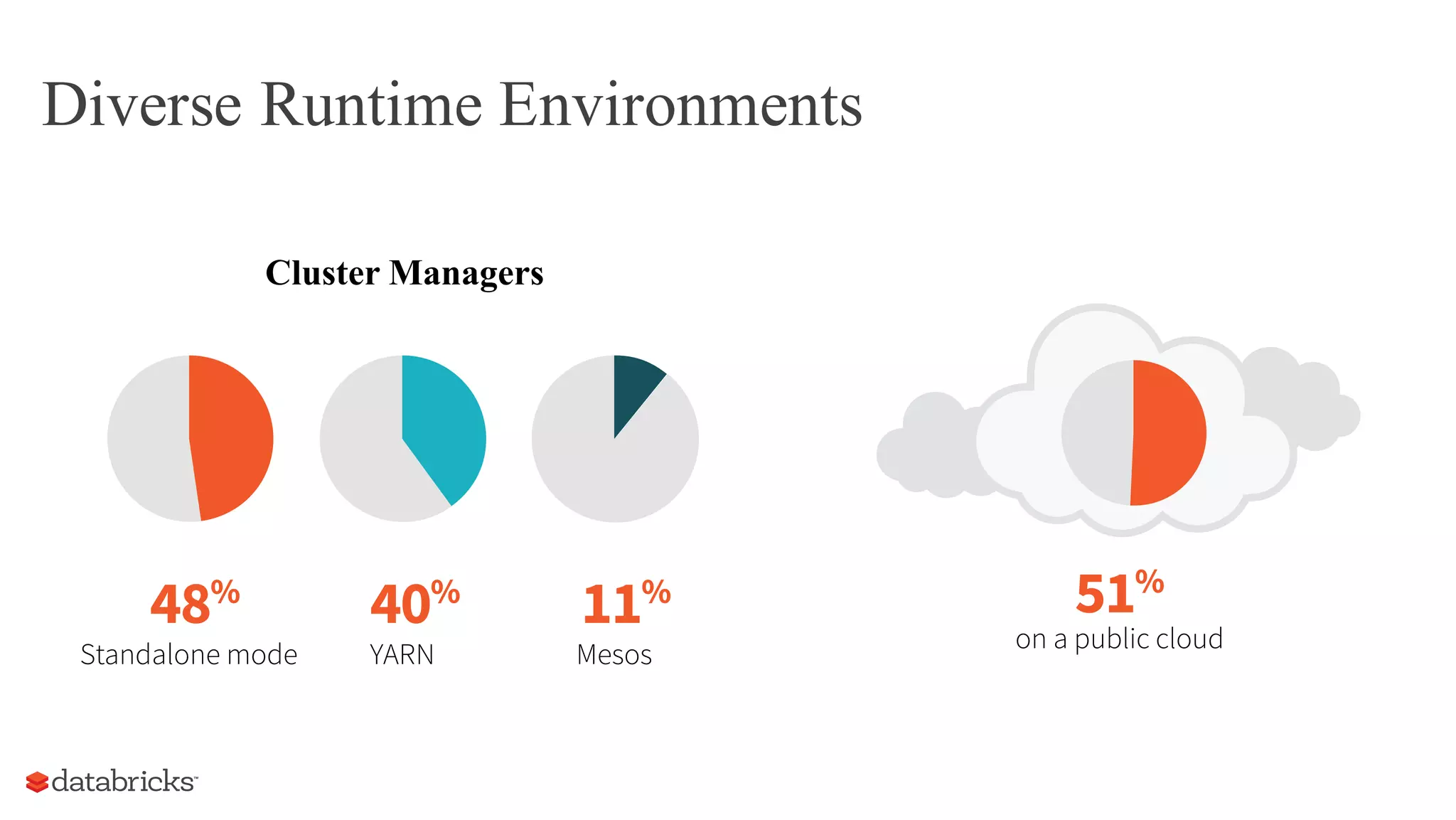
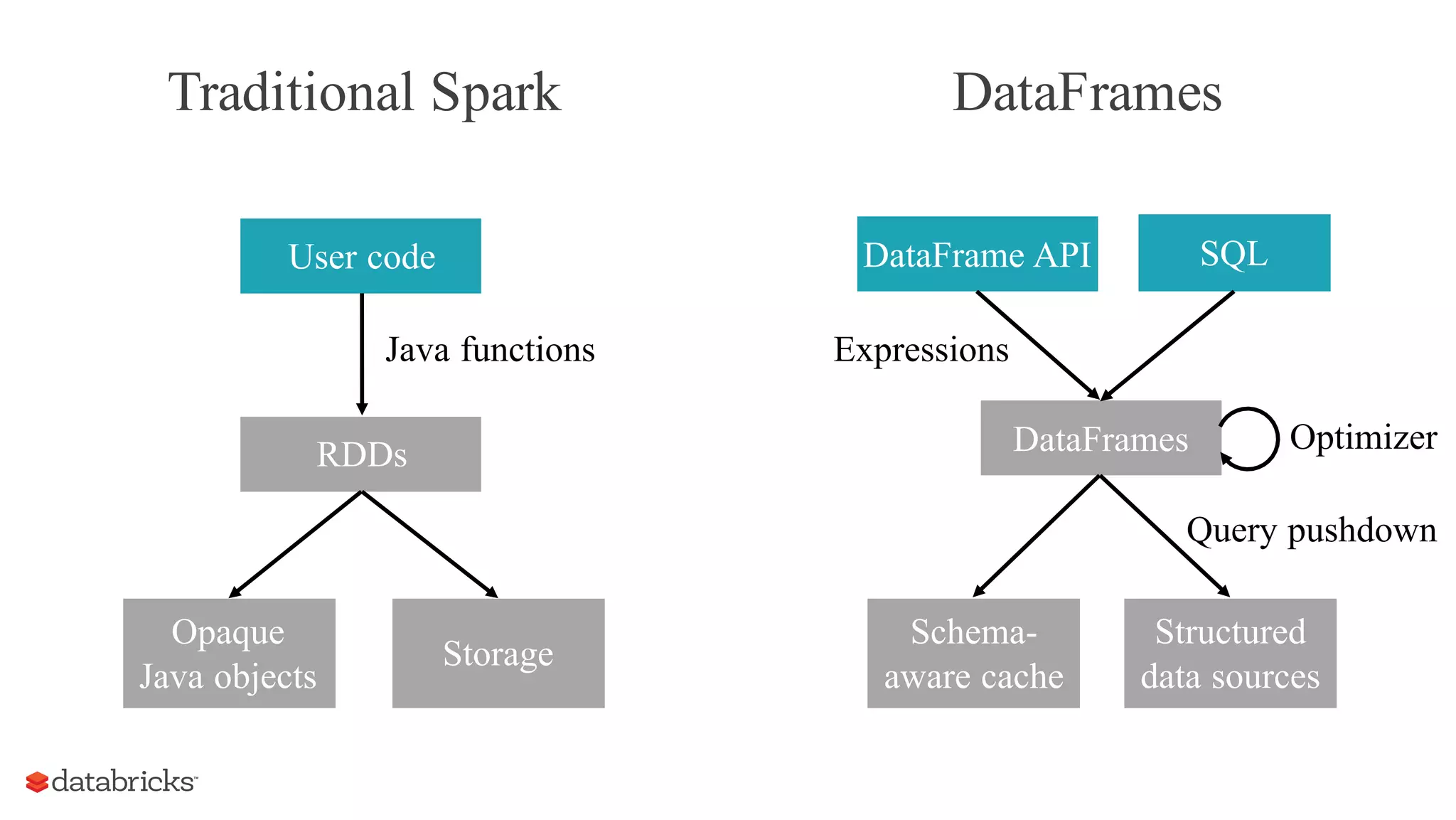
The document discusses the evolution of Spark in 2015, highlighting its rise as a major open-source project in big data, with significant industry adoption and community growth. Key trends include diverse applications, increased runtime environments, and a broader user base across various industries. The year also saw advancements in Spark components, particularly the introduction of dataframes, which enhanced optimization and usability.




































![[Sneak Preview] Apache Spark: Preparing for the next wave of Reactive Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/coll-report-typesafe-apache-spark-slide-share-150127023731-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

























































