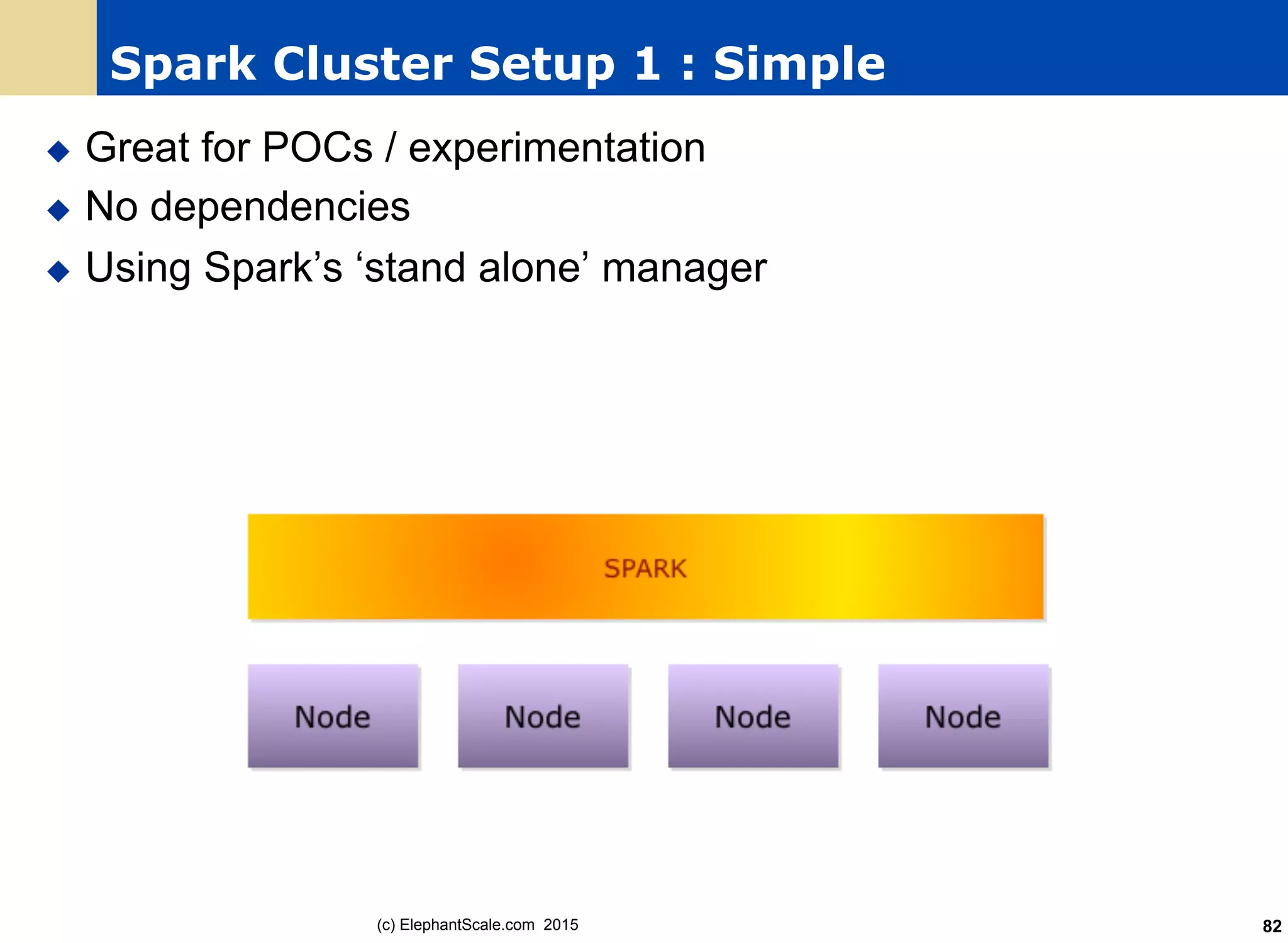
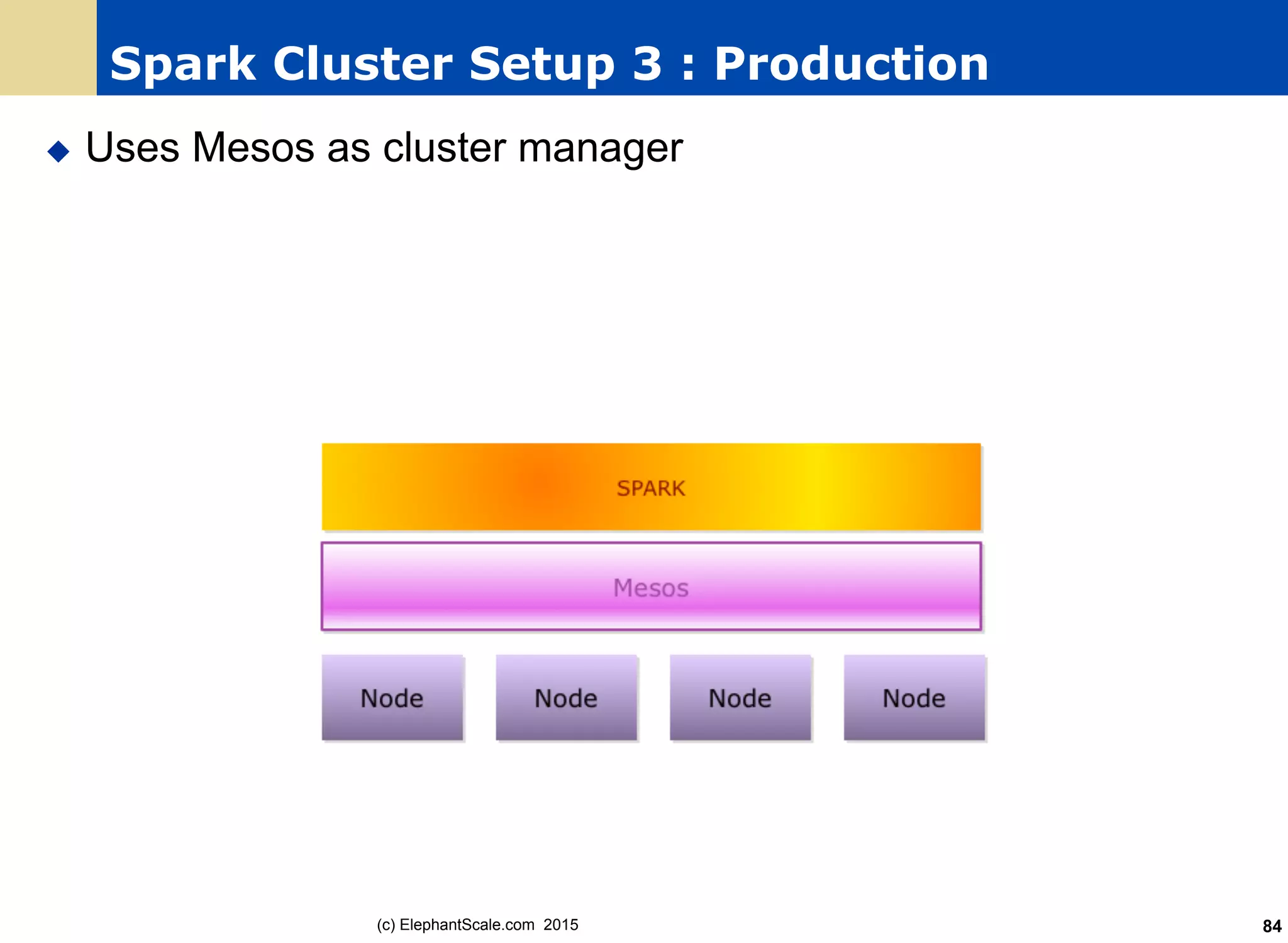
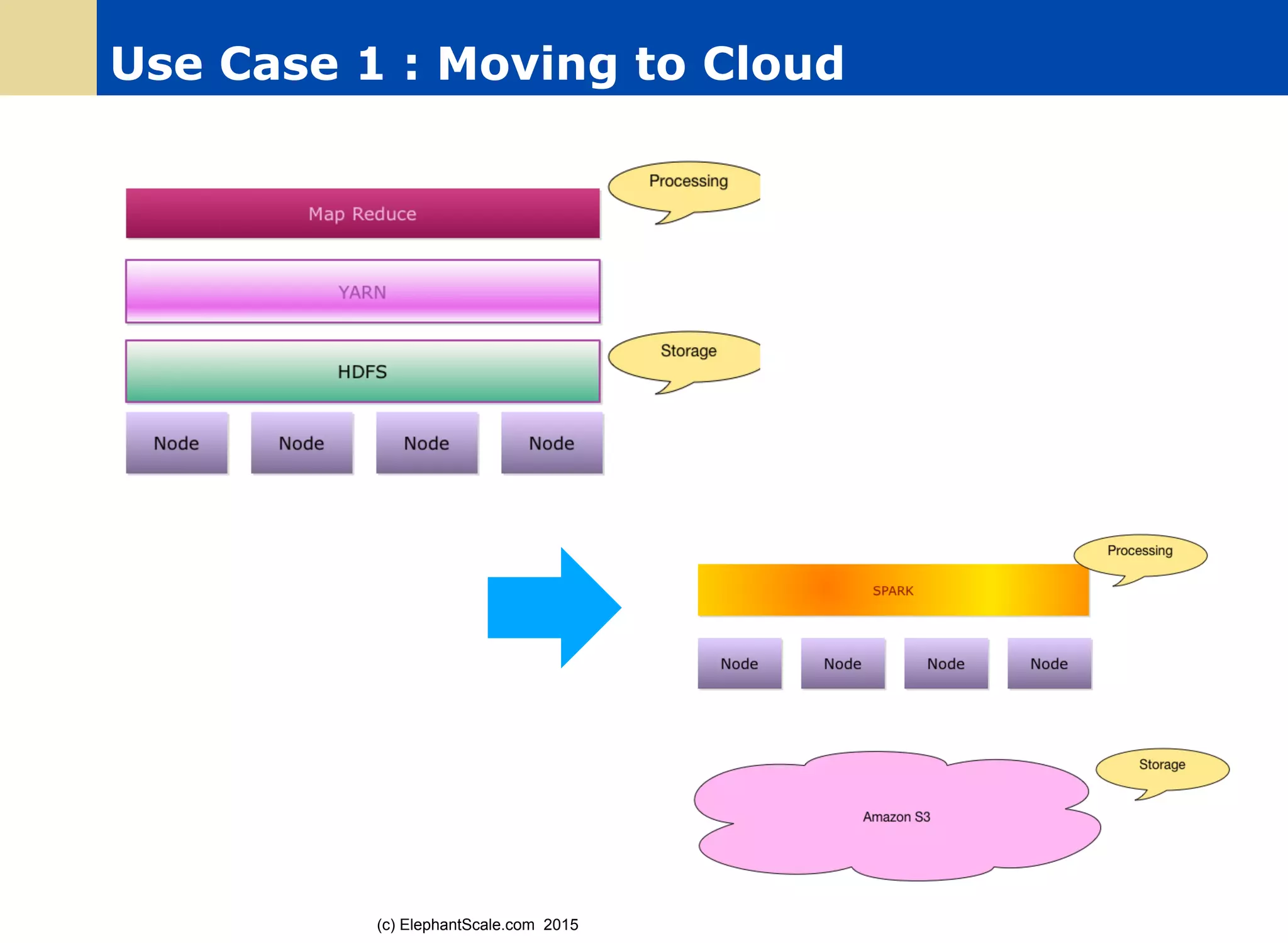
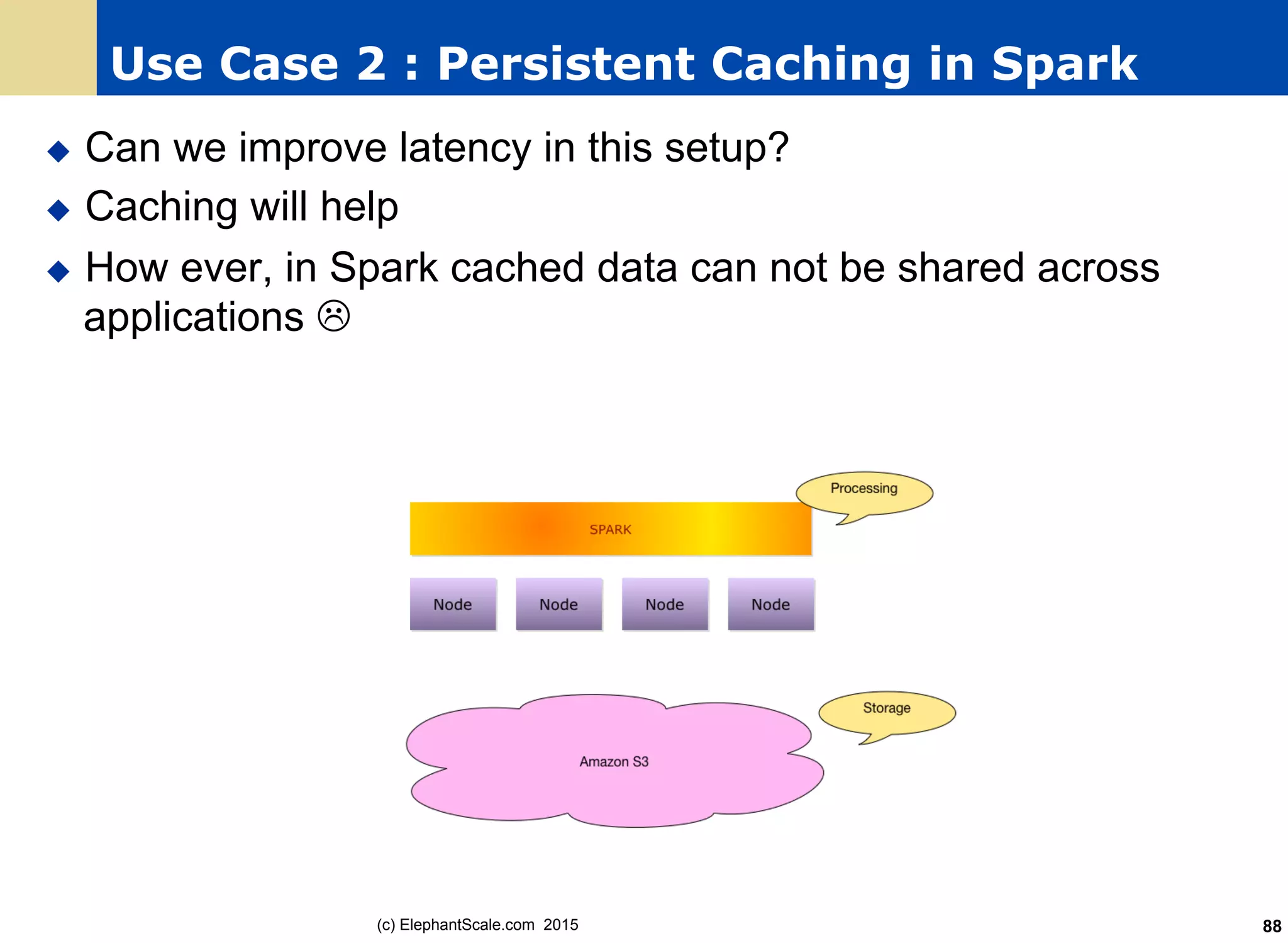
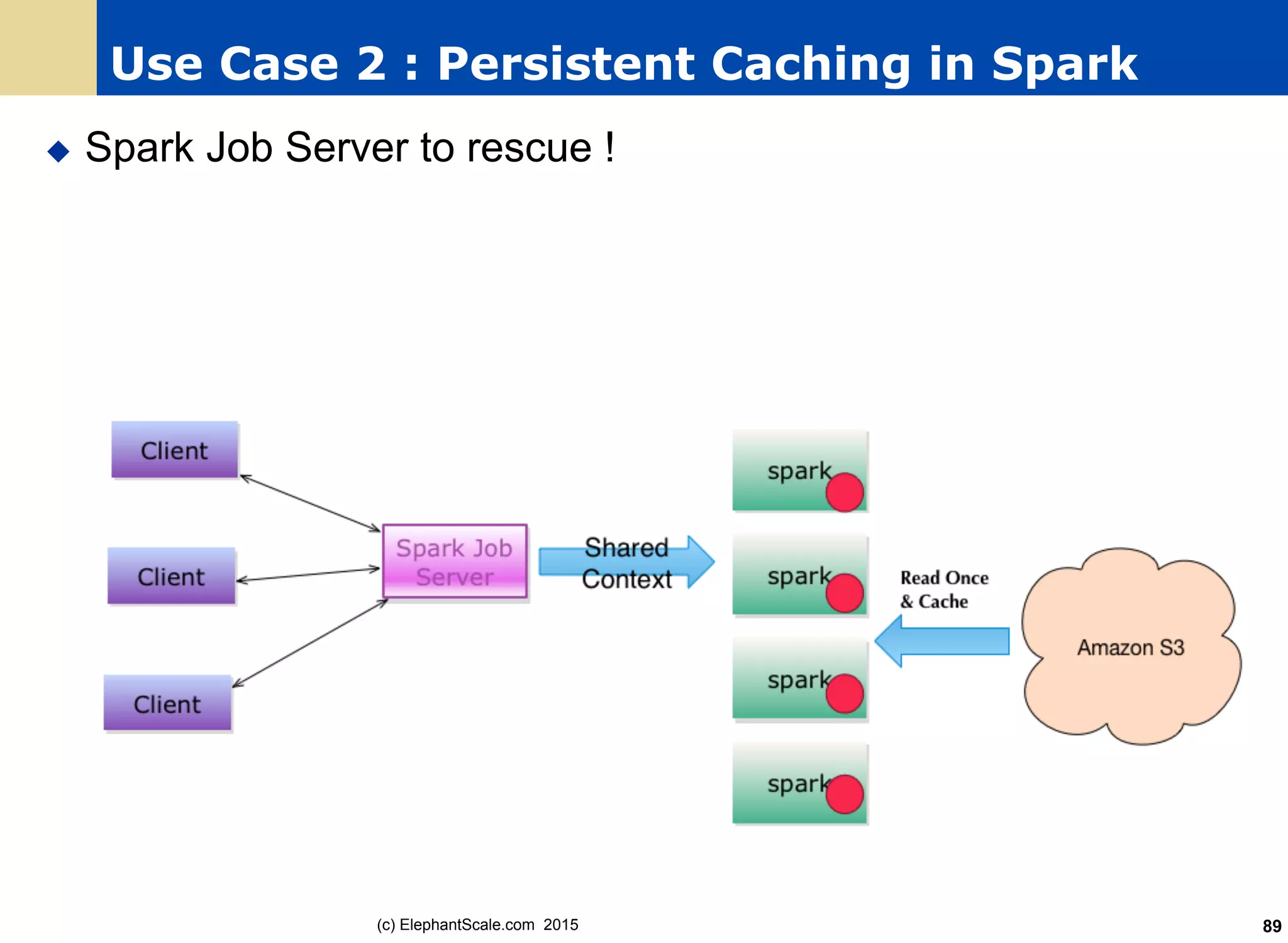
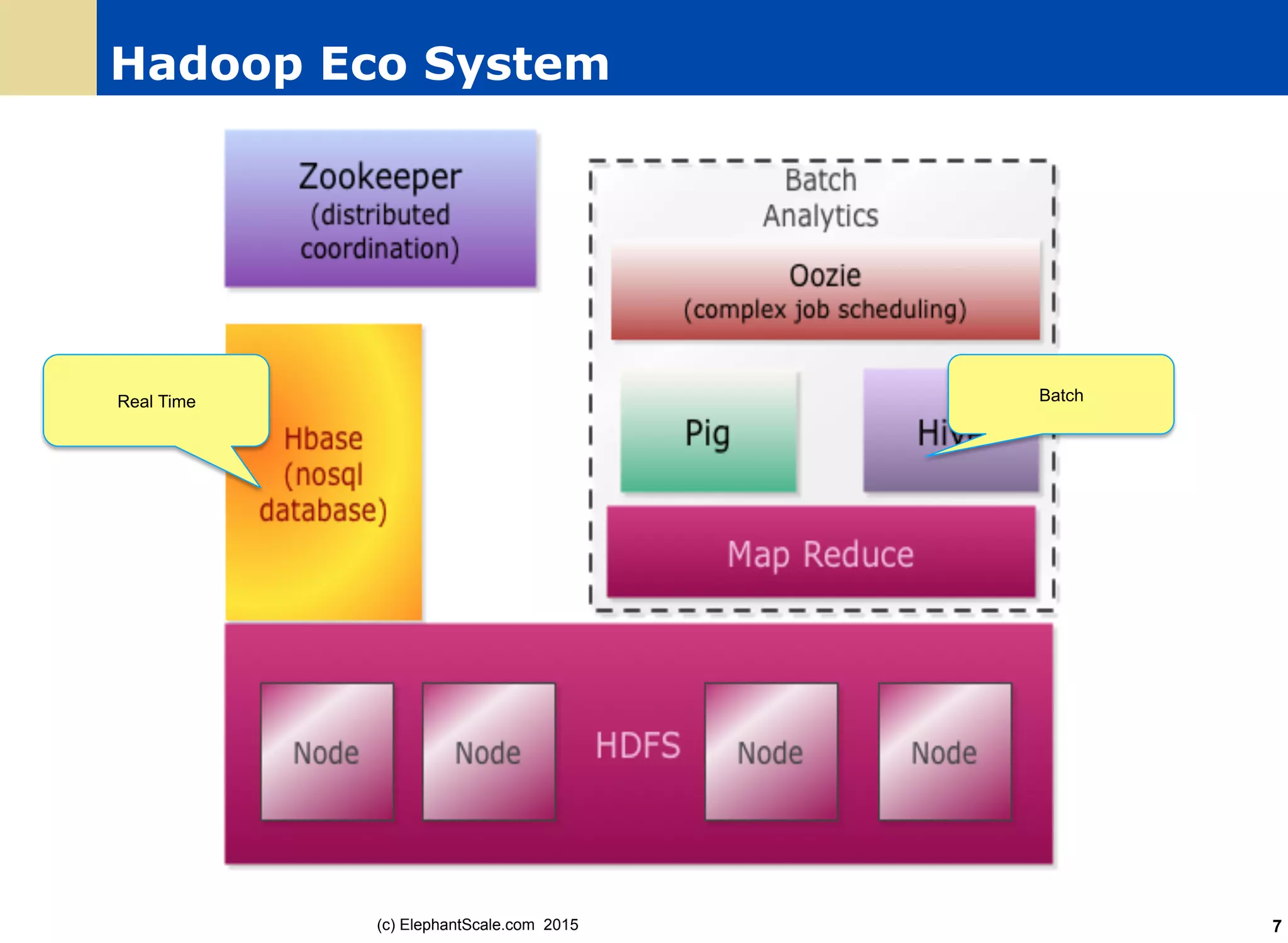
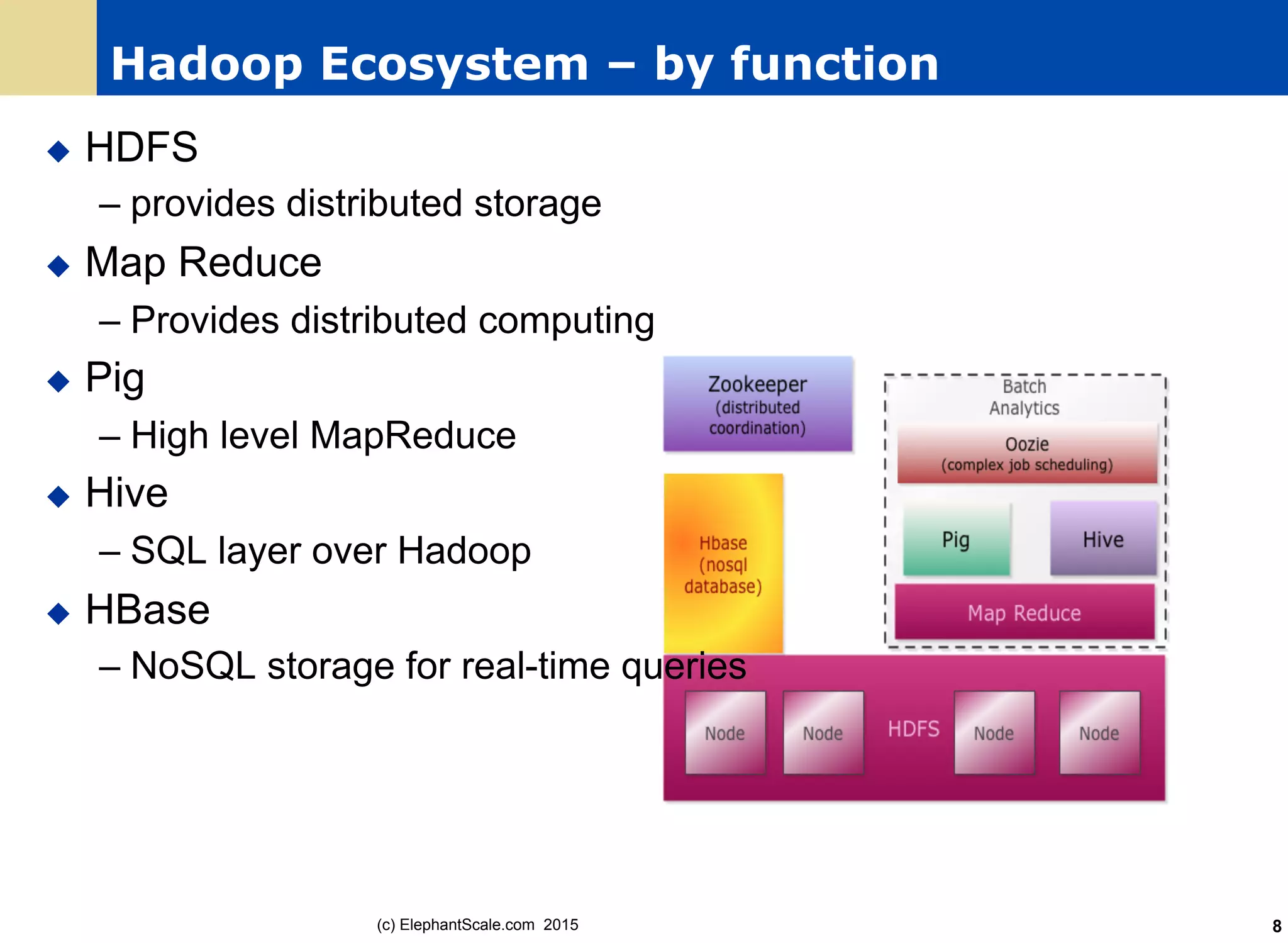
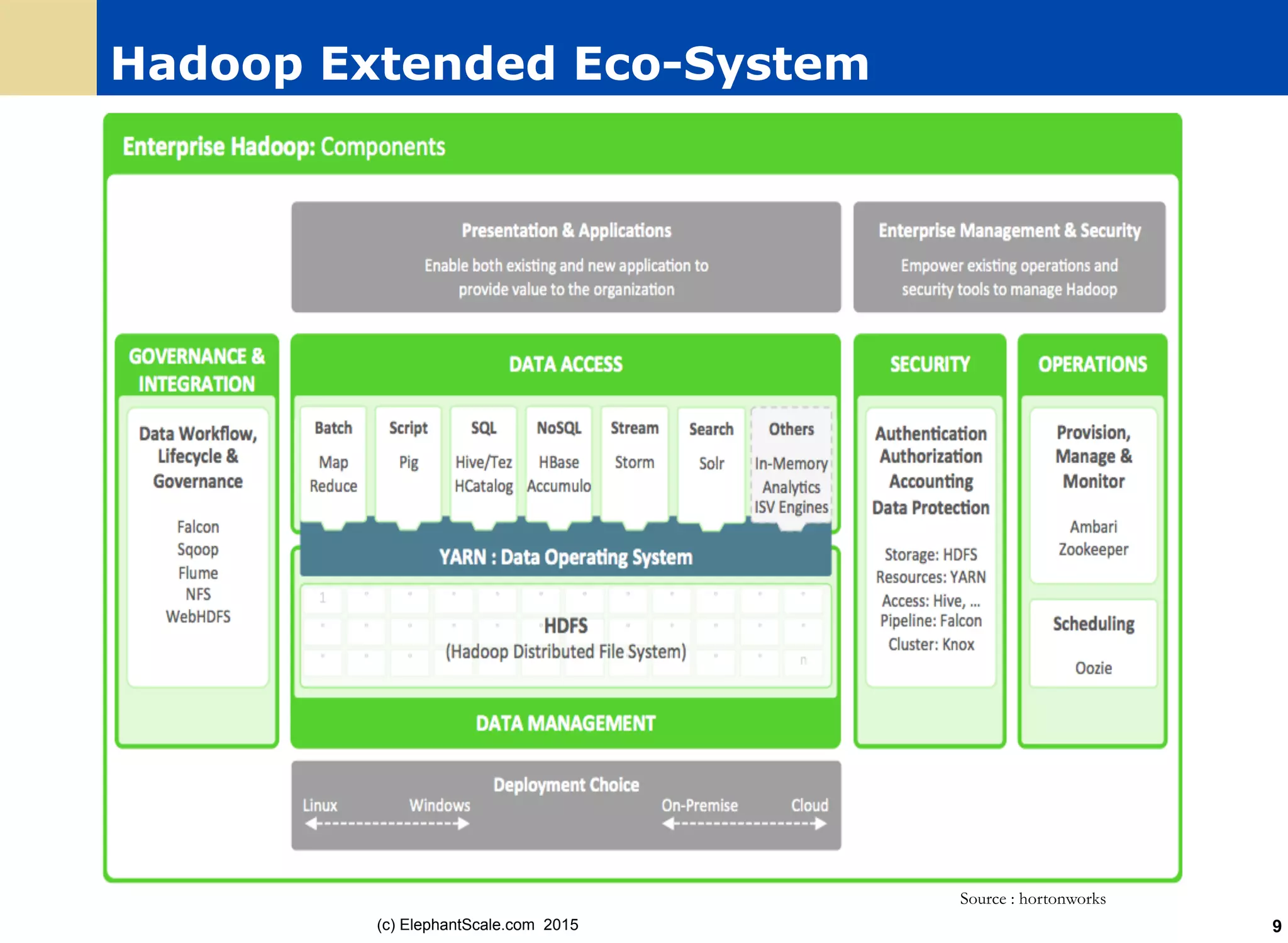
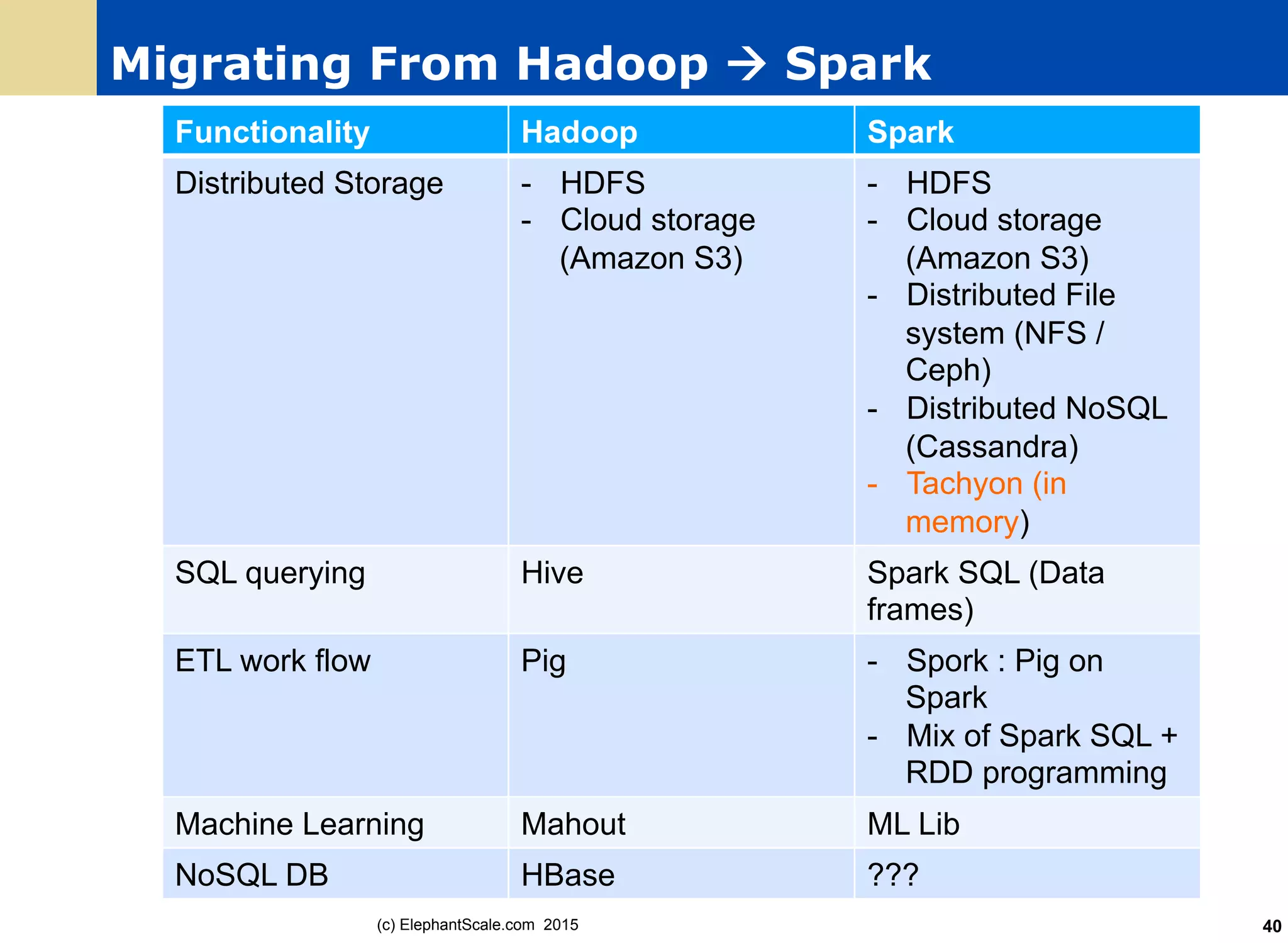
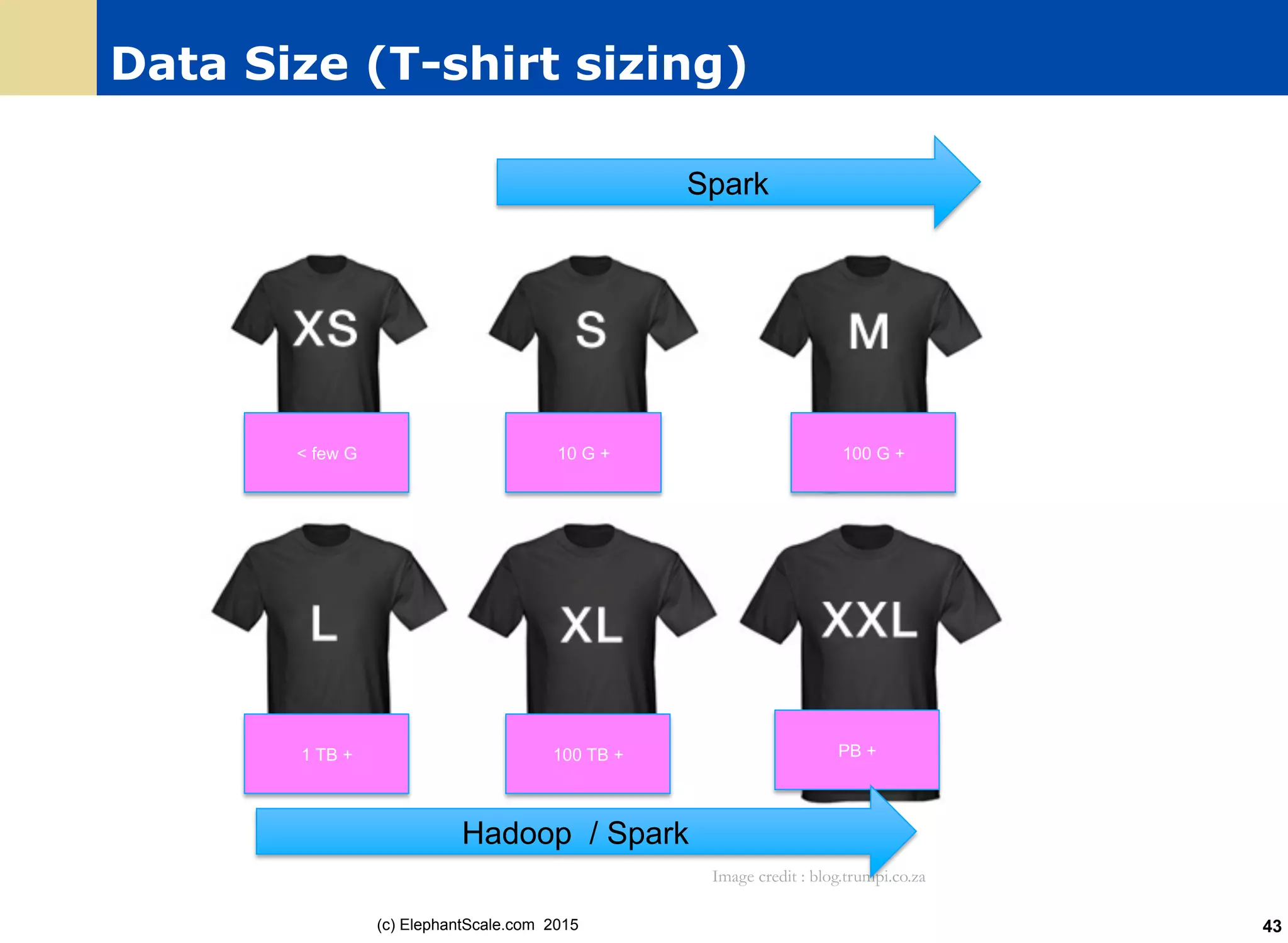
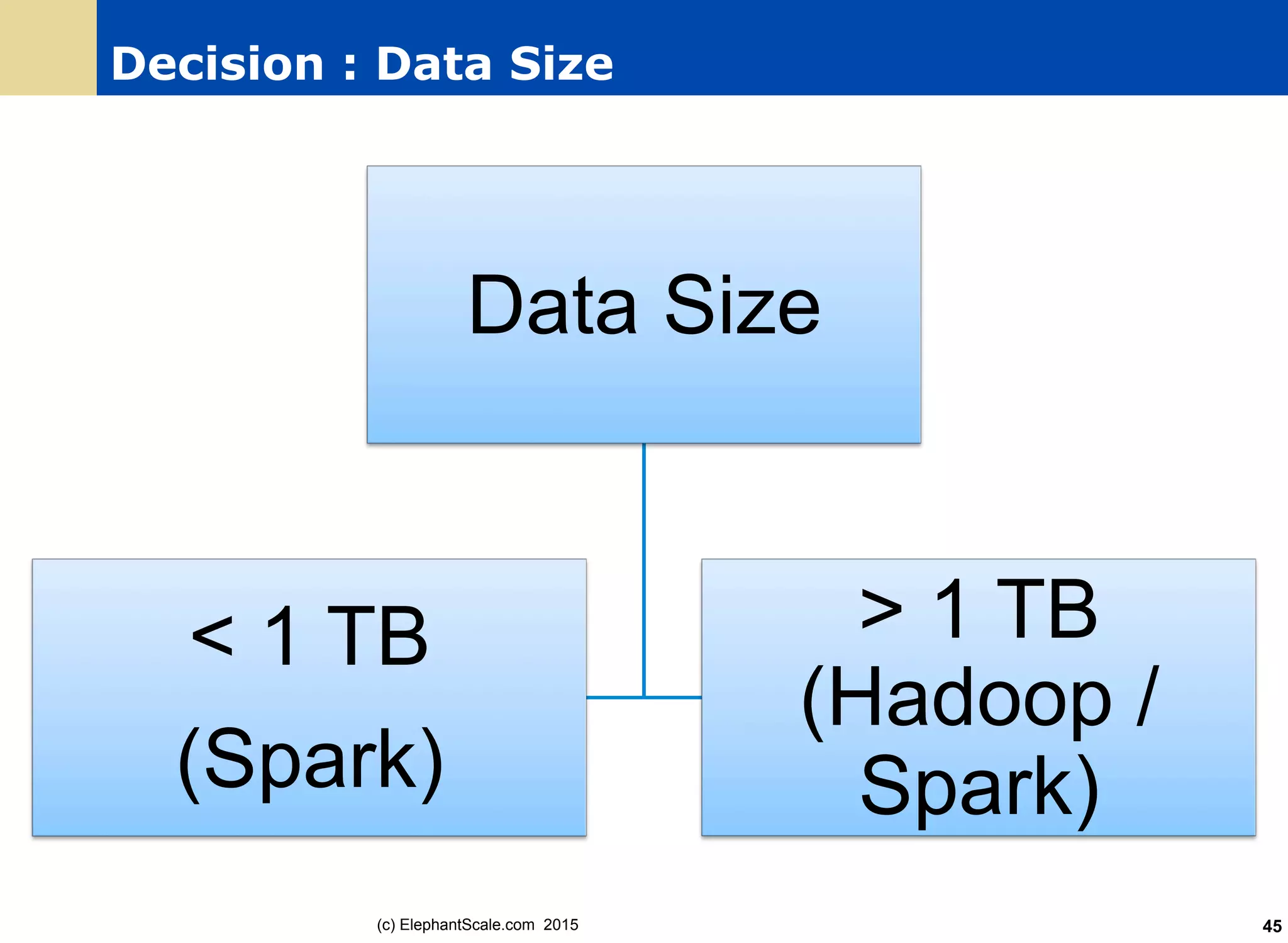
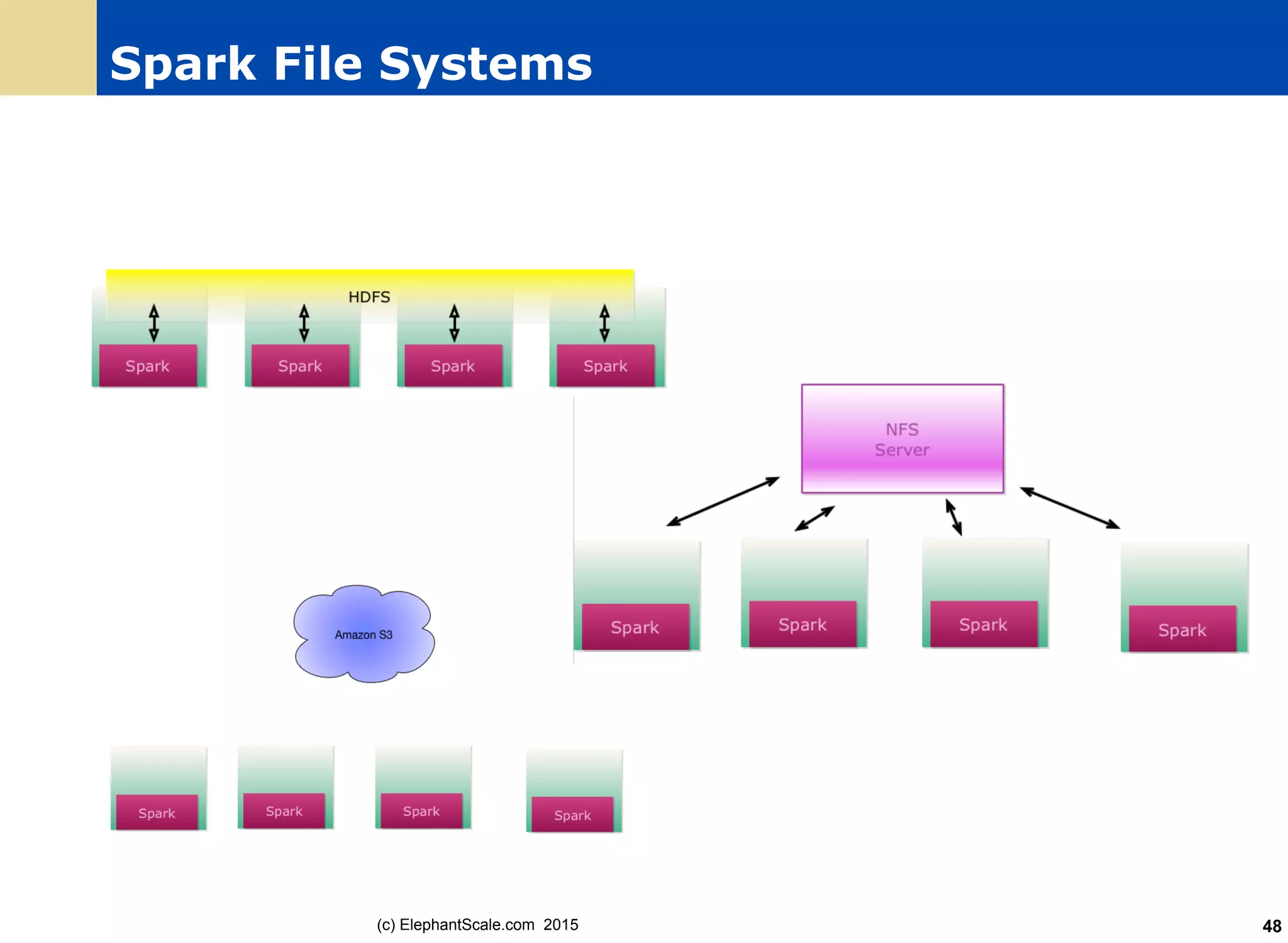
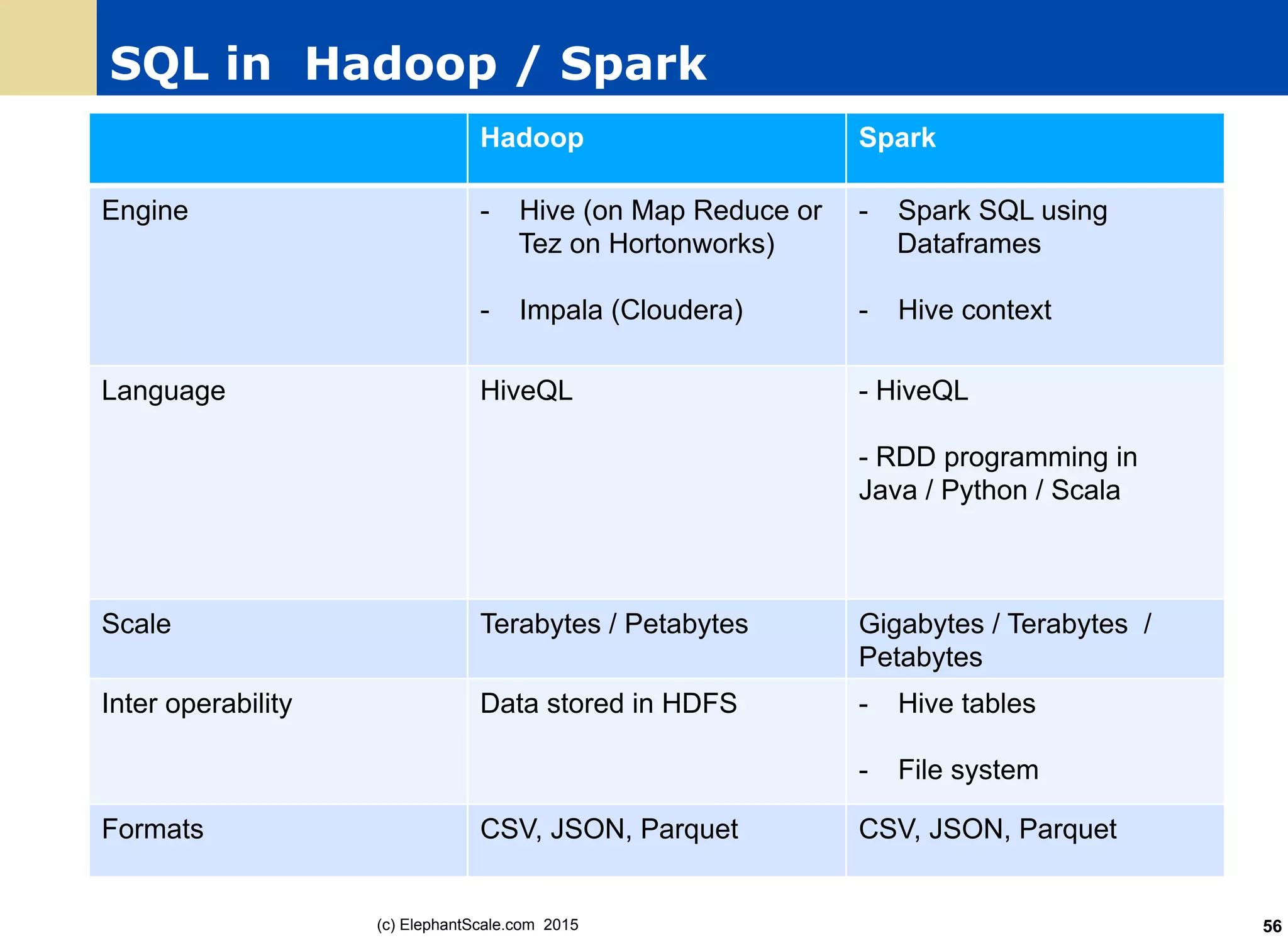
The document discusses the transition from Hadoop to Spark, detailing their capabilities, use cases, and differences. It highlights Spark's advantages over Hadoop, including faster processing, ease of use, and support for various programming models. Additionally, it outlines considerations for migrating to Spark, such as data size and file systems.






























![Creating a DataFrame From JSON
{"name": "John", "age": 35 }
{"name": "Jane", "age": 40 }
{"name": "Mike", "age": 20 }
{"name": "Sue", "age": 52 }
(c)
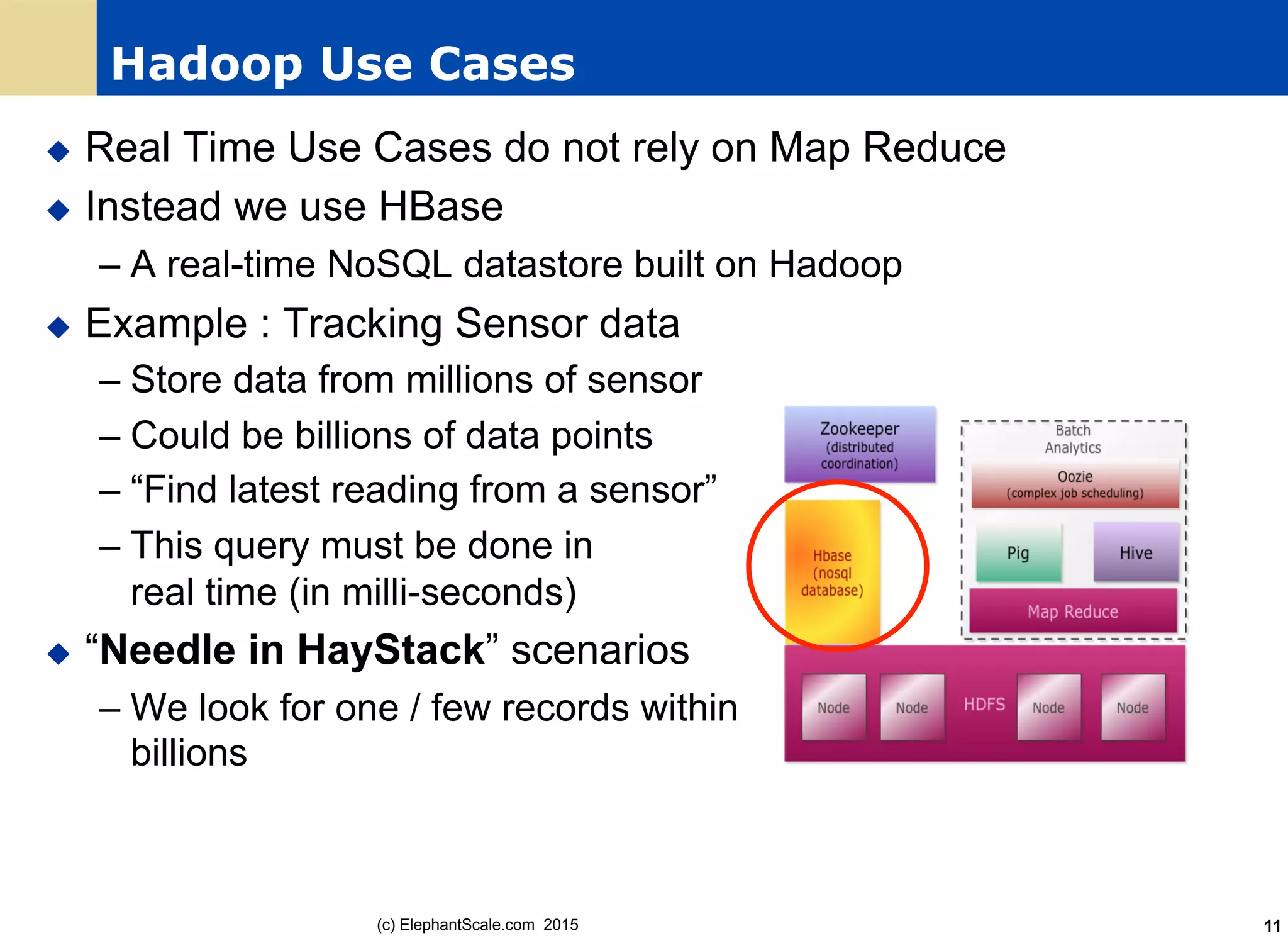
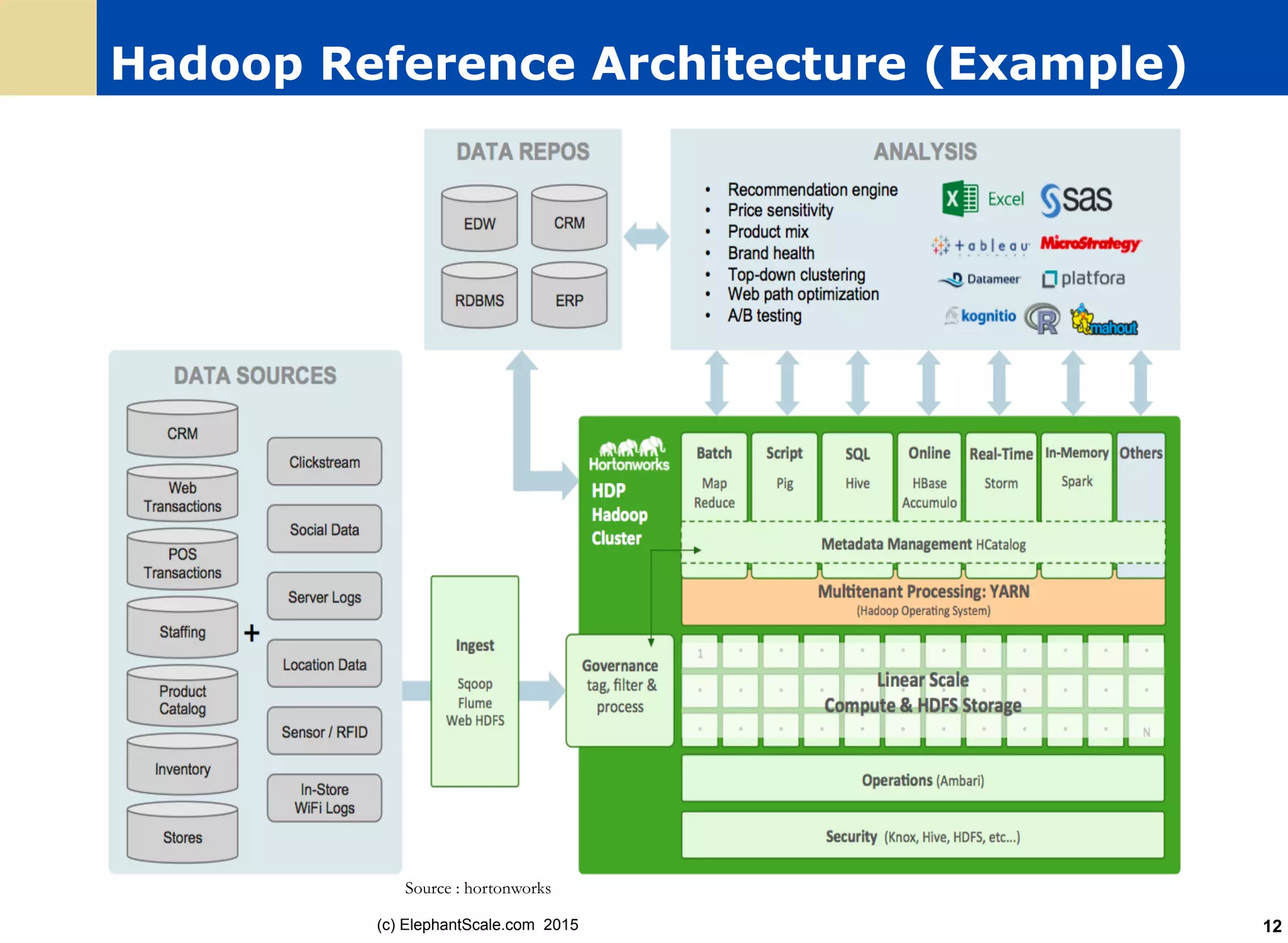
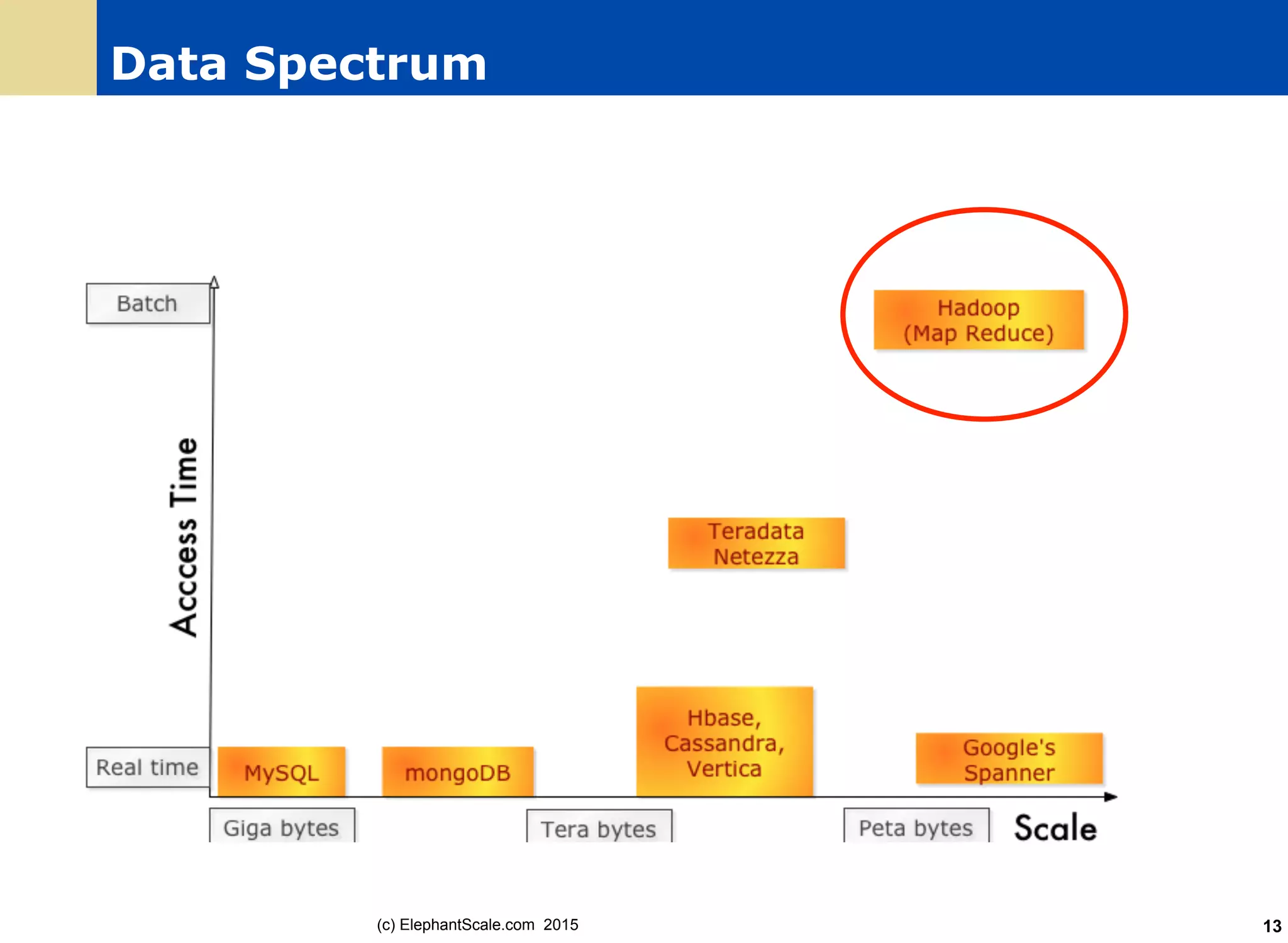
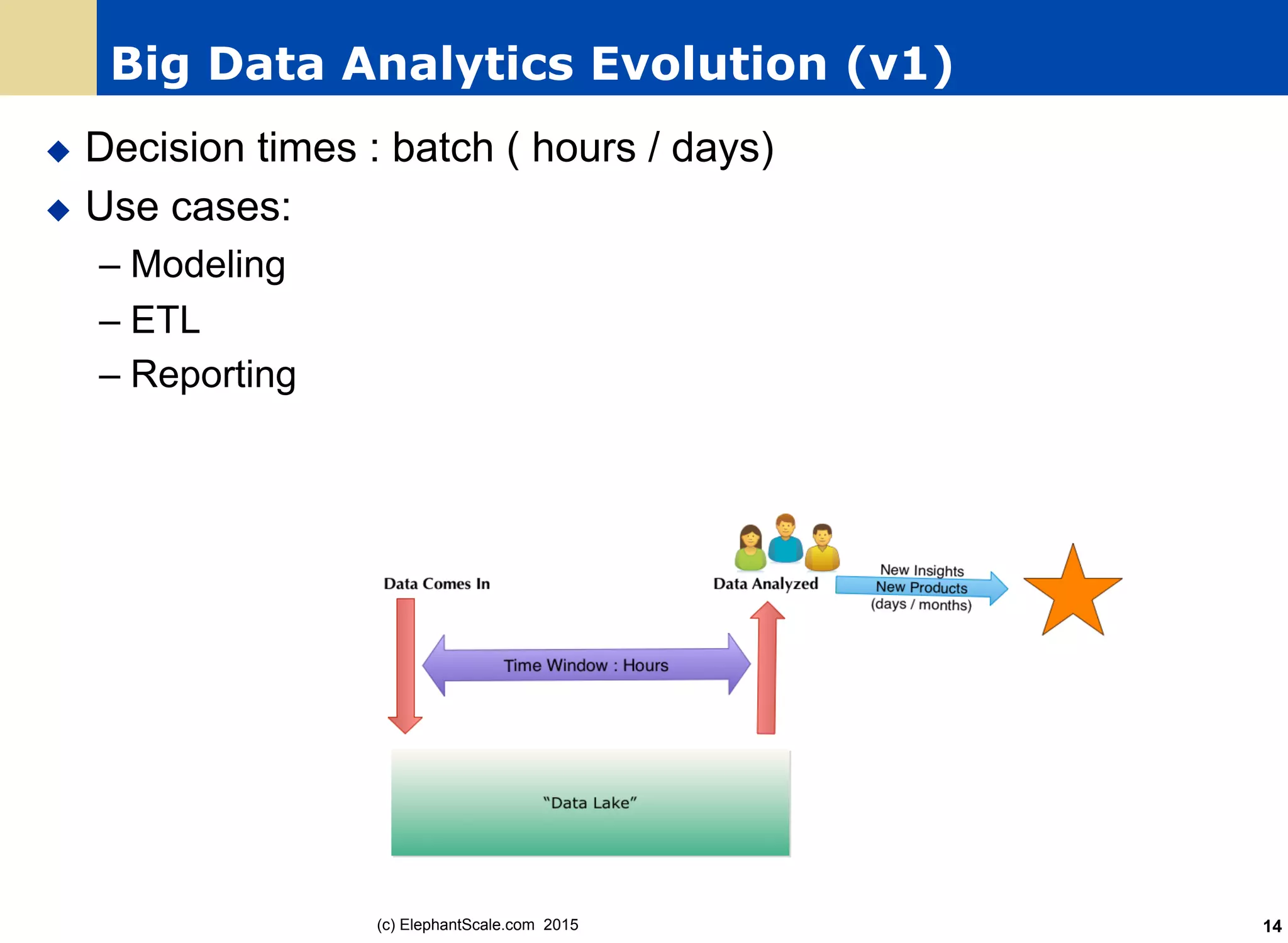
Elephant
Scale.co
m 201559 Session 6: Spark SQL
scala> val peopleDF = sqlContext.read.json("people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.printSchema()
root
|-- age: long(nullable = true)
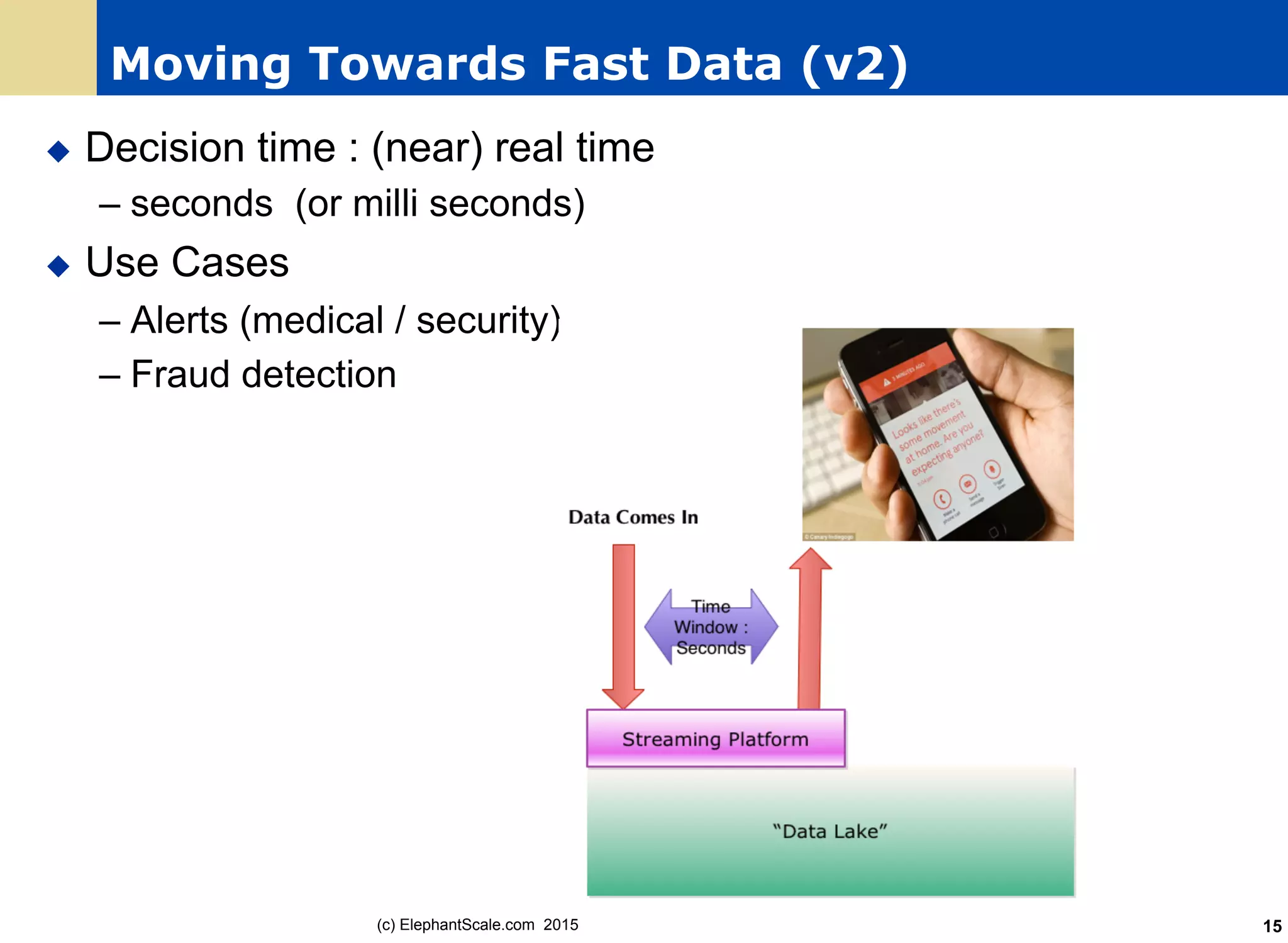
|-- name: string (nullable = true)
scala> peopleDF.show()
+---+----+
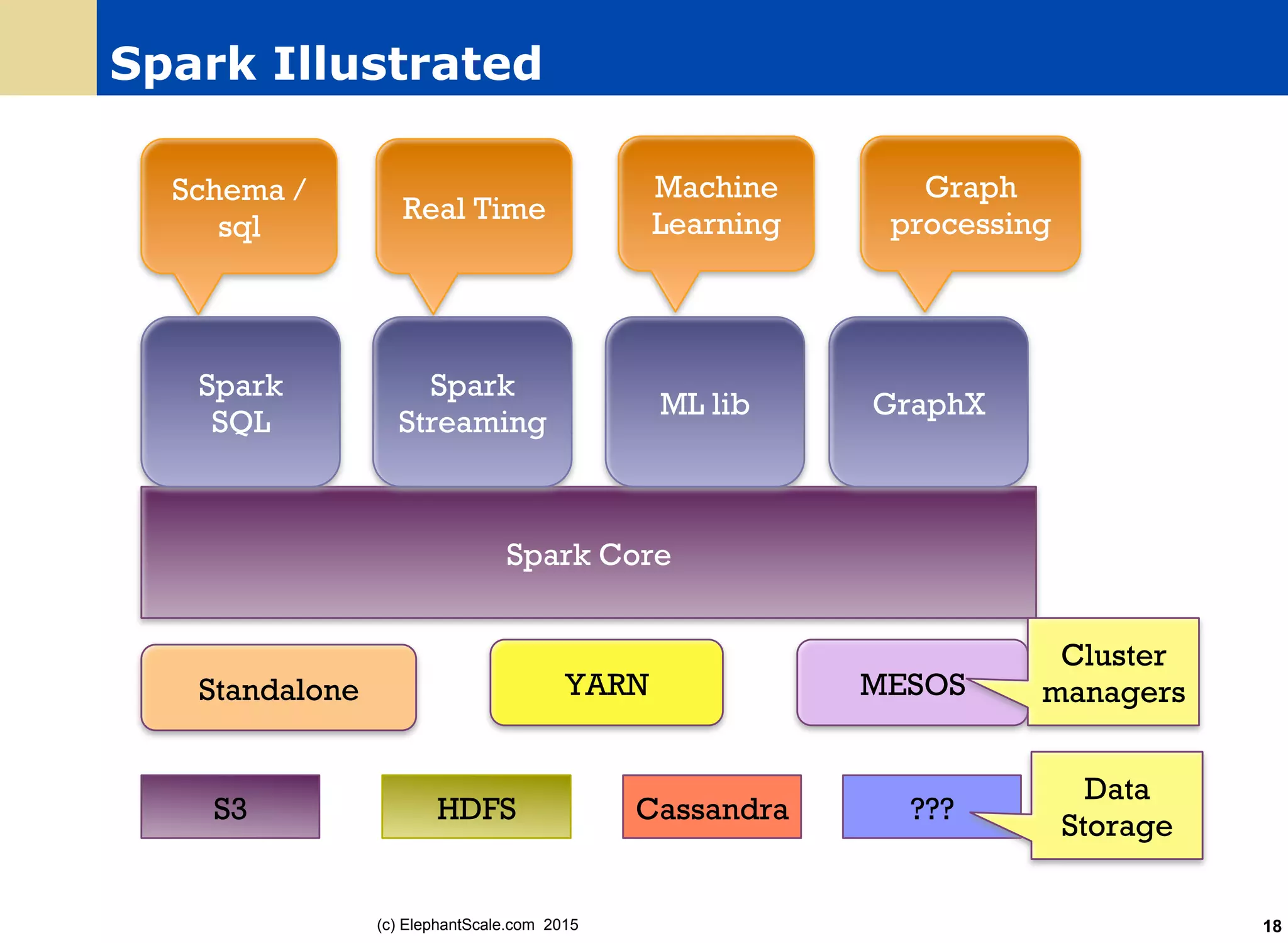
|age|name|
+---+----+
| 35|John|
| 40|Jane|
| 20|Mike|
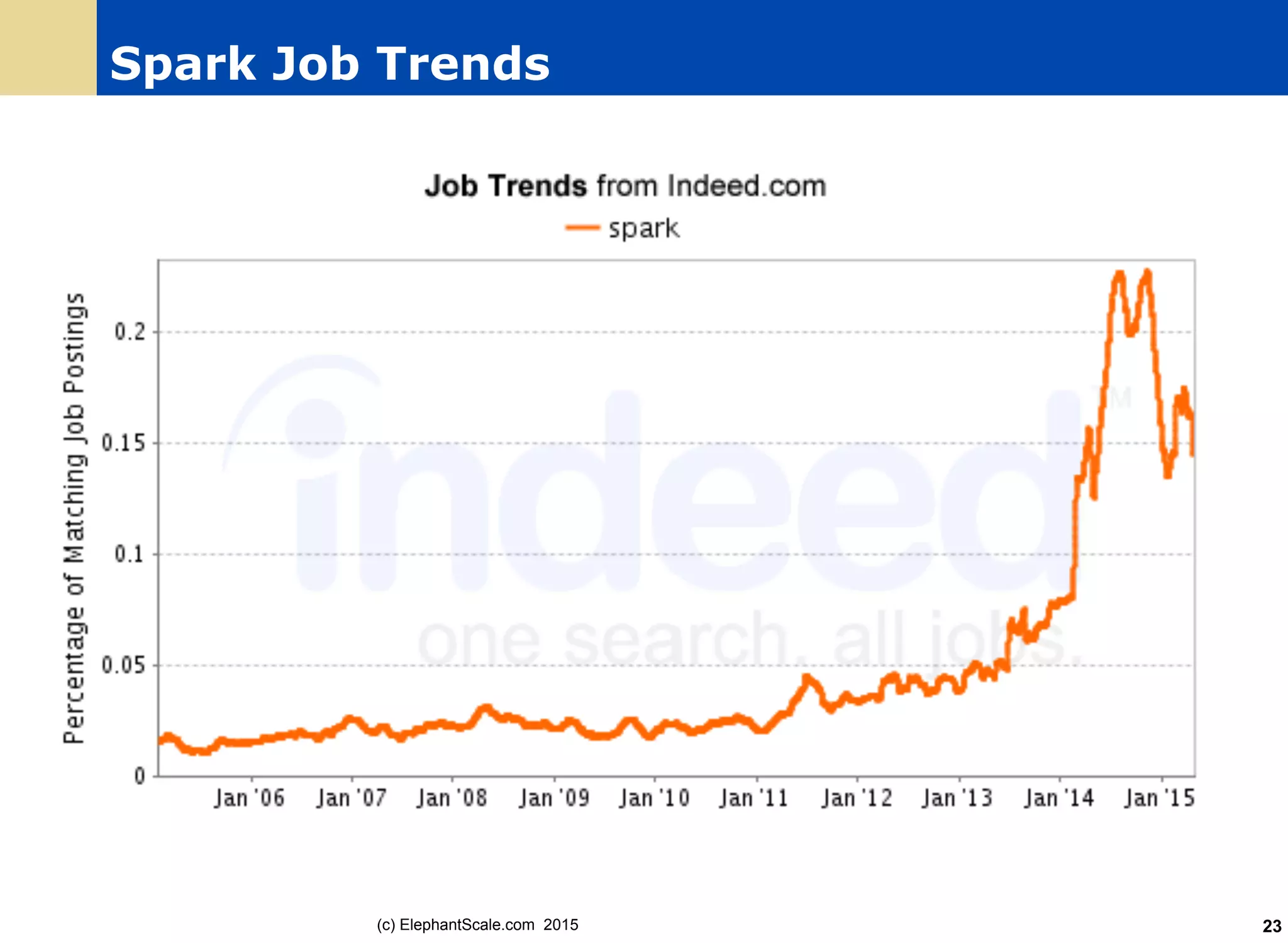
| 52| Sue|
+---+----+](https://image.slidesharecdn.com/hadooptosparkv2-151110202812-lva1-app6892/75/Hadoop-to-spark_v2-59-2048.jpg)