Downloaded 58 times






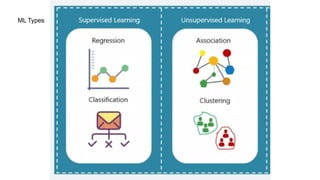



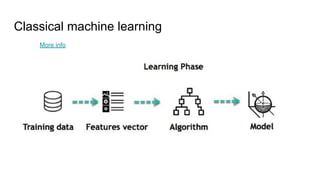
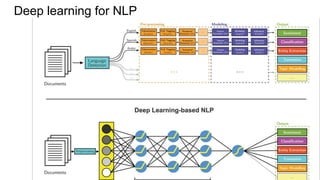


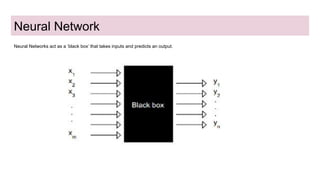
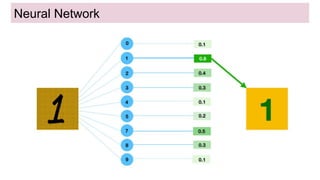
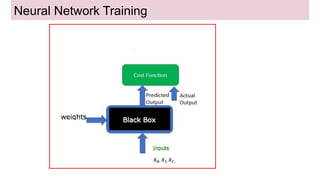
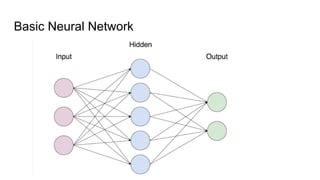
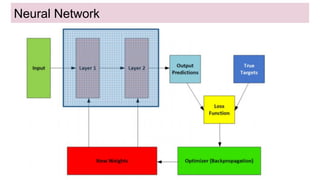
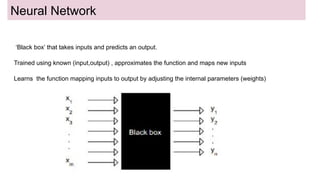
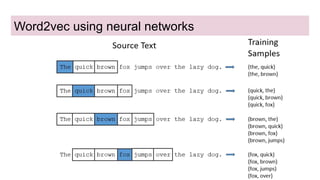
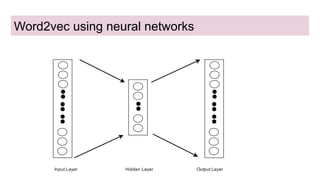
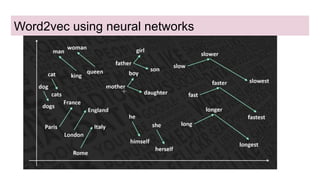
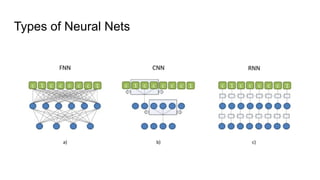


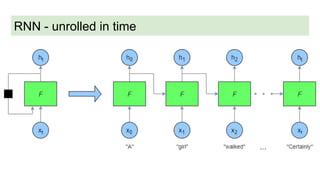
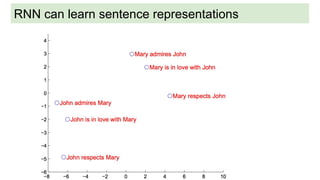
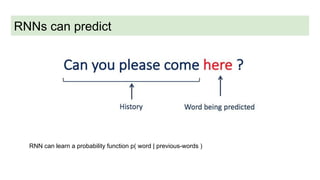
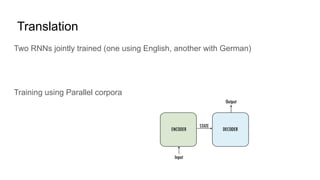


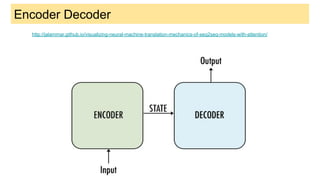
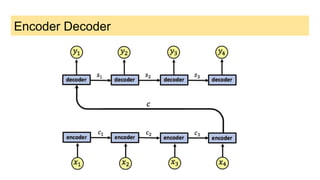
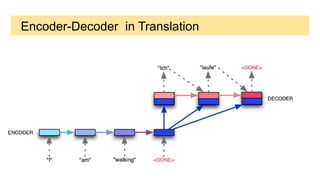



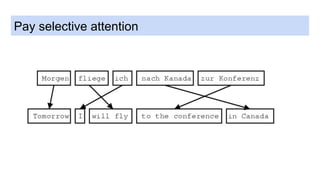

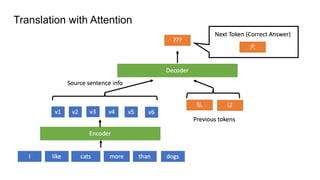
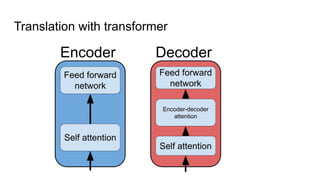

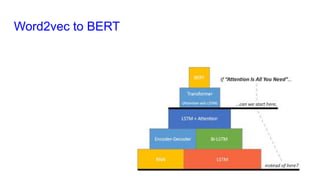

This document provides an overview of deep learning basics for natural language processing (NLP). It discusses the differences between classical machine learning and deep learning, and describes several deep learning models commonly used in NLP, including neural networks, recurrent neural networks (RNNs), encoder-decoder models, and attention models. It also provides examples of how these models can be applied to tasks like machine translation, where two RNNs are jointly trained on parallel text corpora in different languages to learn a translation model.























































































