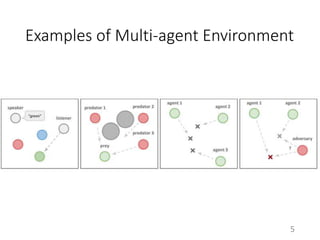
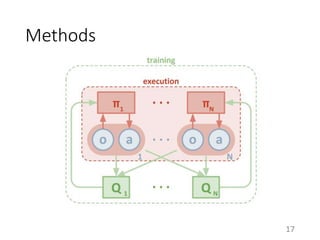
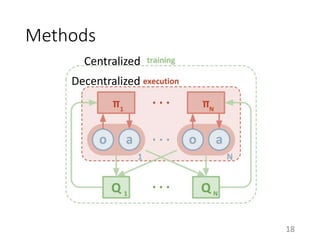
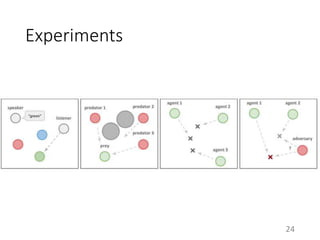
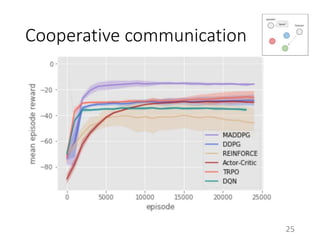
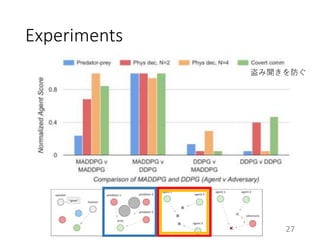
This document proposes a multi-agent actor-critic method for mixed cooperative-competitive environments. The method extends traditional actor-critic by having the critic use extra information about other agents' policies while keeping the actor decentralized by using only local information. This allows agents to learn cooperative behaviors while still handling competitive scenarios. The method is evaluated on cooperative communication tasks where it successfully learns the desired policies, unlike traditional reinforcement learning approaches.




















![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Grandmaster level in StarCraft II using multi-agent reinforcement lear...](https://cdn.slidesharecdn.com/ss_thumbnails/alphastarfinal-191227002114-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)
































