Downloaded 58 times







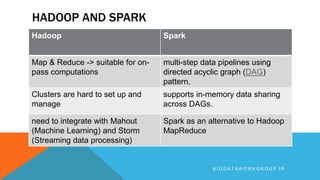



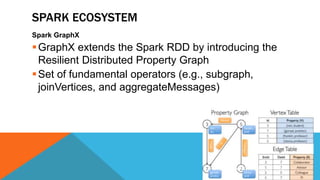


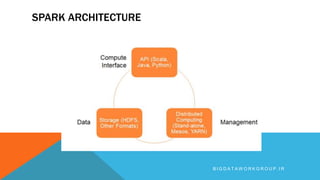

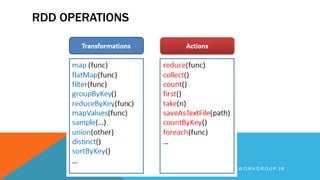



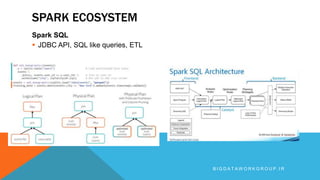


Apache Spark is an open source big data processing framework that is faster than Hadoop, easier to use, and supports more types of analytics. It provides high-level APIs, can run computations directly in memory for faster performance, and supports a variety of data processing workloads including SQL queries, streaming data, machine learning, and graph processing. Spark also has a large ecosystem of additional libraries and tools that expand its capabilities.



































































