Downloaded 82 times


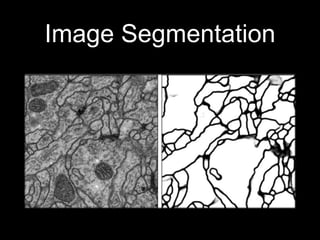



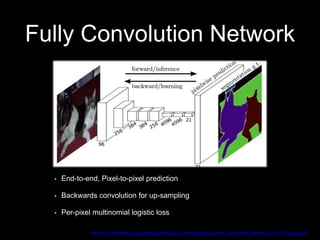

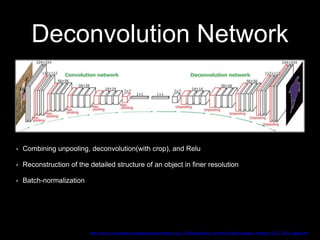



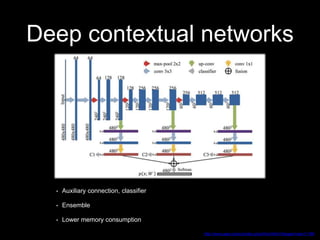

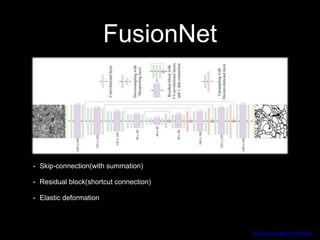

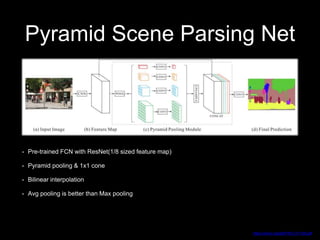




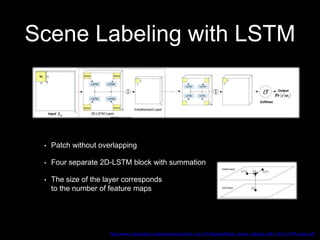









This document discusses different deep learning approaches for image segmentation. It covers using convolutional neural networks (CNNs), recurrent neural networks (RNNs), and generative adversarial networks (GANs). For CNNs, it describes fully convolutional networks, deconvolution networks, U-Net, and other models. For RNNs, it discusses multi-dimensional RNNs, scene labeling with LSTMs, turned and pyramid RNNs, and grid LSTMs. It also reviews Pix2Pix and other GAN-based models for image segmentation tasks.
![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)









![Review : Multi-Domain Image Completion for Random Missing Input Data [cdm]](https://cdn.slidesharecdn.com/ss_thumbnails/multi-domainimagecompletionforrandommissinginputdata-reviewcdm-200821161134-thumbnail.jpg?width=640&height=640&fit=bounds)

![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)











































![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)





























