Downloaded 942 times






















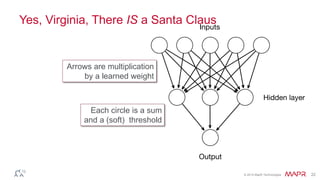
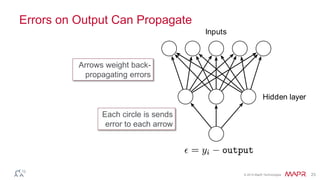





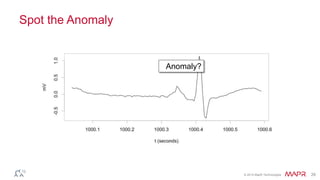
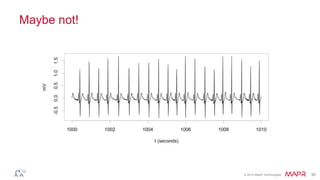
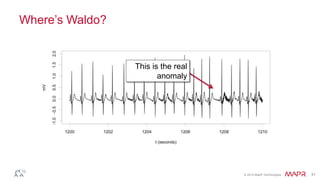

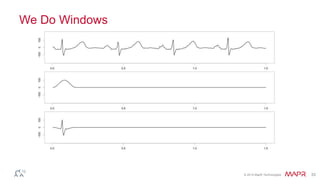
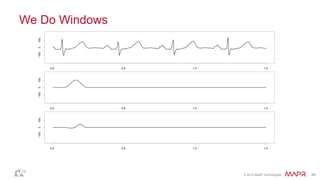
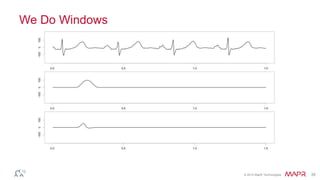
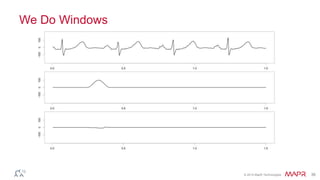
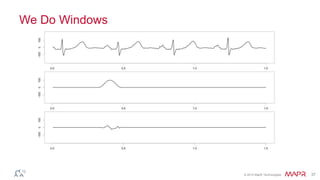
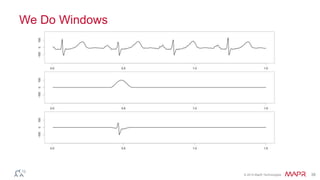
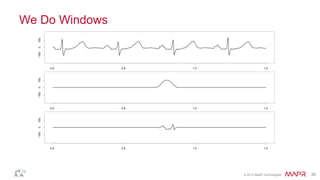
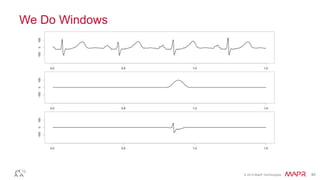
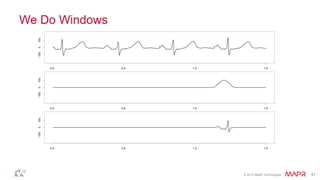

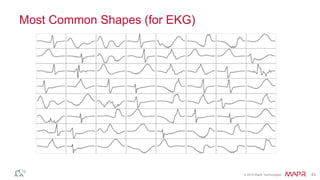
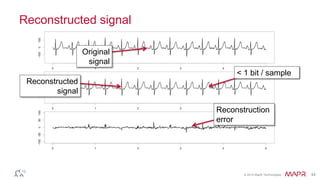
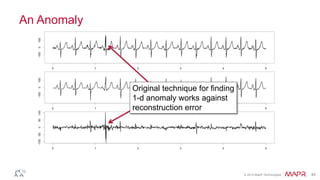
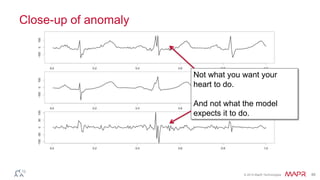
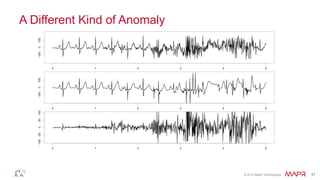


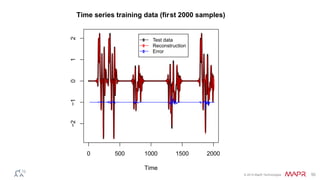
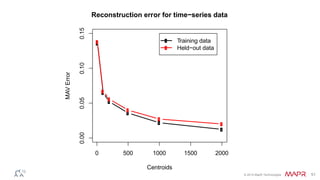

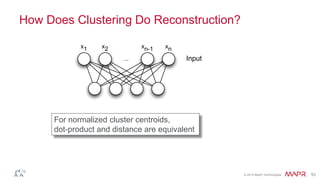
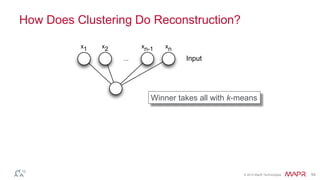
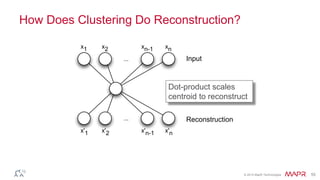
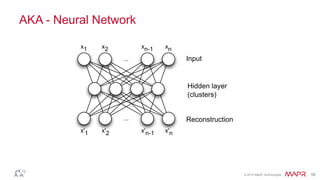
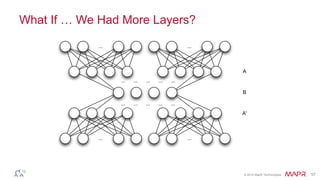






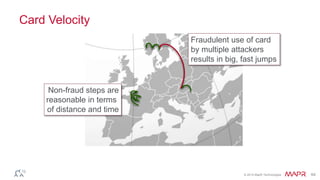



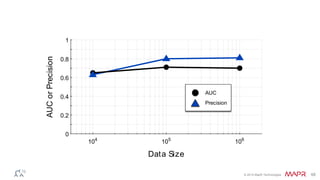








This document summarizes a presentation on deep learning and fraud detection. The presentation explores the state of the art in deep learning and fraud detection, provides guidance on getting results, and includes experiments. The agenda includes discussing motivation for advanced modeling in fraud detection, explaining neural networks and deep learning, and exploring sample fraud detection features and challenges. Examples of applying clustering and autoencoders to time series anomaly detection and card velocity fraud detection are also summarized.




































































































