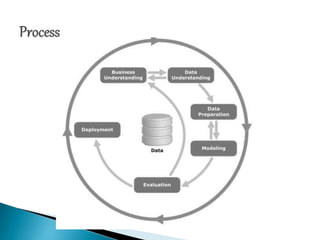
The document outlines a project aimed at creating a predictive model to classify borrowers as defaulters or non-defaulters using historical loan data from Lending Club, employing various machine learning algorithms and the CRISP-DM methodology. It details the data collection process, cleaning techniques, feature selection, and model evaluation metrics, focusing on minimizing false negatives to protect investor interests. The project involves using tools such as Python and various libraries to preprocess the data and develop the final classification model.


























































![ai it hw mst prac[1] - Read-Offnly.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiithwmstprac1-read-only-250118093323-c97d352c-thumbnail.jpg?width=640&height=640&fit=bounds)
























