Downloaded 1,980 times

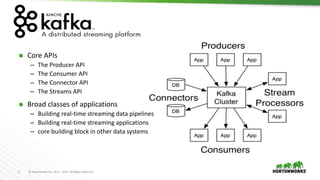
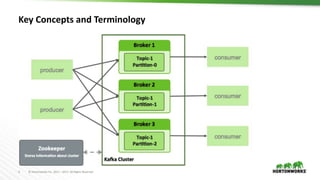
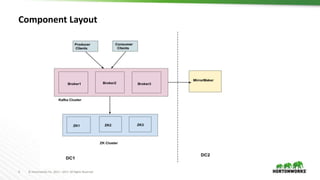
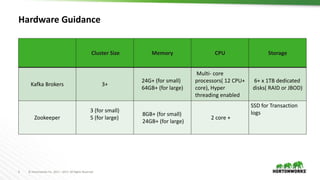




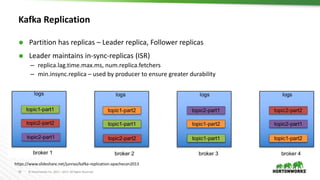

















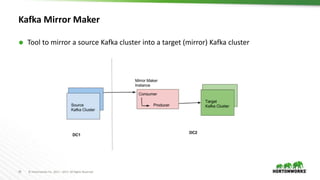
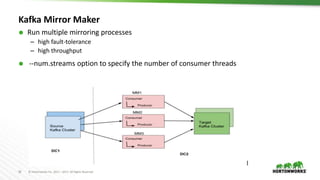




The document outlines best practices for configuring and optimizing Apache Kafka clusters, including hardware requirements, OS tuning, disk storage management, and monitoring metrics. It emphasizes the importance of replication, partition management, and producer/consumer performance tuning for ensuring reliability and efficiency in streaming data applications. Additionally, it provides guidance on managing cluster size, broker configurations, and the use of operational tools for monitoring and managing Kafka environments.











































































































