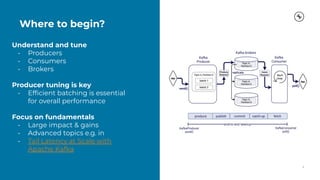
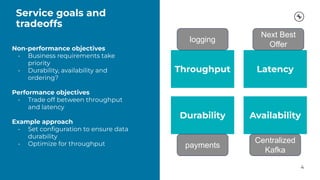
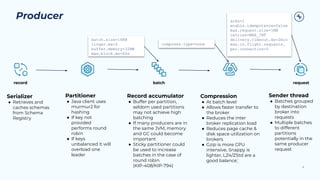
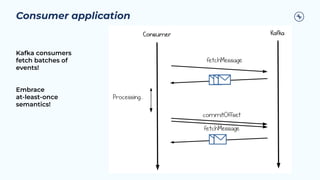
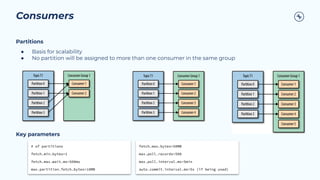
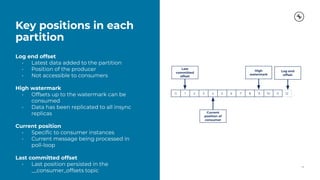
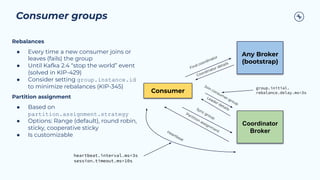
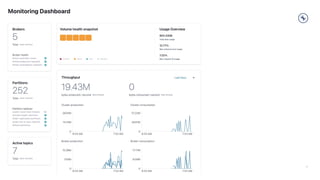
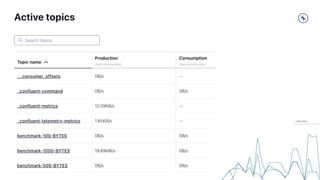
This document provides a guide on benchmarking and tuning Apache Kafka, focusing on producers, consumers, and brokers to enhance performance. Key topics include configuring producers for batching, understanding consumer group behavior, and optimizing client applications based on service goals like throughput and latency. It emphasizes the importance of monitoring, testing various parameters, and continually evaluating system performance to ensure efficient operation.









![Most significant producer performance metrics
Metric Meaning MBean
record-size-avg Avg record size kafka.producer:type=producer-metrics,client-id=([-.w]+)
batch-size-avg
Avg number of bytes sent per partition
per-request
kafka.producer:type=producer-metrics,client-id=([-.w]+)
bufferpool-wait-ratio
Faction of time an appender waits for
space allocation
kafka.producer:type=producer-metrics,client-id=([-.w]+)
compression-rate-avg
Avg compression rate for a topic.
Compressed / uncompressed batch size
kafka.producer:type=producer-topic-metrics,client-id=([-.w]+),to
pic=([-.w]+)
record-queue-time-avg
Avg time (ms) record batches spent in
the send buffer
kafka.producer:type=producer-metrics,client-id=([-.w]+)
request-latency-avg Avg request latency (ms) kafka.producer:type=producer-metrics,client-id=([-.w]+)
produce-throttle-time-avg
Avg time (ms) a request was throttled
by a broker
kafka.producer:type=producer-metrics,client-id=([-.w]+)
record-retry-rate
Avg per-second number of retried record
sends for a topic
kafka.producer:type=producer-topic-metrics,client-id=([-.w]+),to
pic=([-.w]+)
Overview Java metrics & librdkafka statistics](https://image.slidesharecdn.com/tokyoakmeetupspeedtest-share-220628114441-daeb878d/85/Tokyo-AK-Meetup-Speedtest-Share-pdf-13-320.jpg)

![Selected consumer performance metrics
Metric Meaning MBean
fetch-latency-avg Avg time taken for a fetch request kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-
.w]+)
fetch-size-avg Avg number of bytes fetched per request kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-
.w]+)
commit-latency-avg Avg time commit request kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.w
]+)
rebalance-latency-total Total time taken for group rebalances kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.
w]+)
fetch-throttle-time-avg Avg throttle time (ms) kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-
.w]+)
Overview Java metrics and librdkafka statistics](https://image.slidesharecdn.com/tokyoakmeetupspeedtest-share-220628114441-daeb878d/85/Tokyo-AK-Meetup-Speedtest-Share-pdf-19-320.jpg)




















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


