






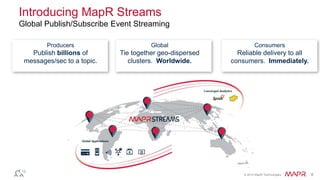
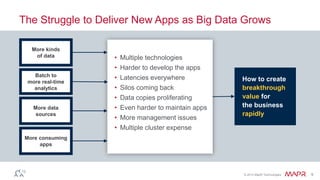
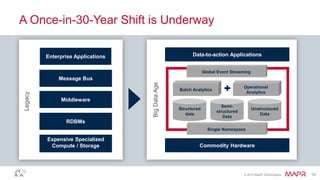
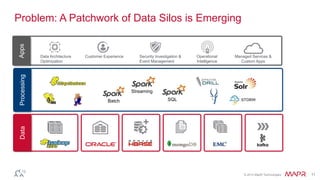

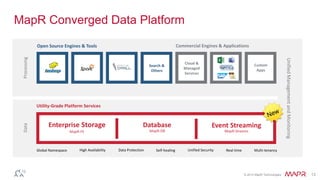
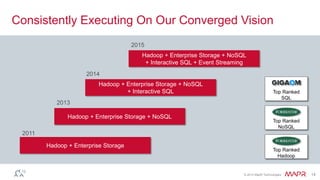
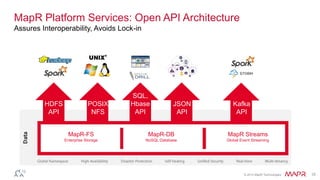



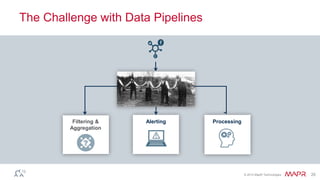
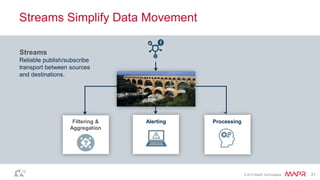
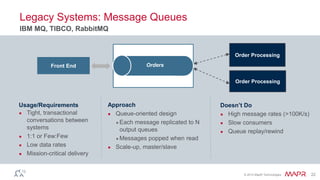
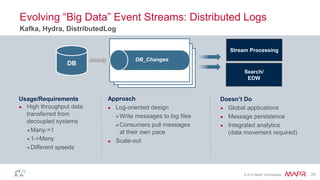



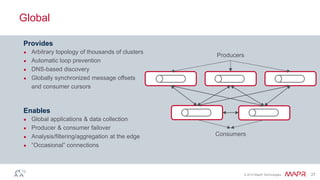
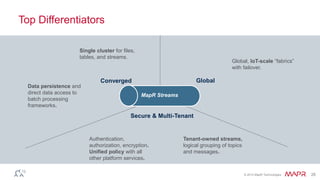






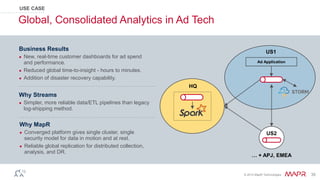



The document discusses MapR Streams, a global publish/subscribe event streaming system. It provides converged, continuous, and global capabilities. MapR Streams allows producers to publish billions of messages per second to topics, and guarantees immediate and reliable delivery to consumers. It also enables tying together geo-dispersed clusters globally. The document demonstrates MapR Streams capabilities with a live demo and discusses use cases for event streaming across various industries.
















































































