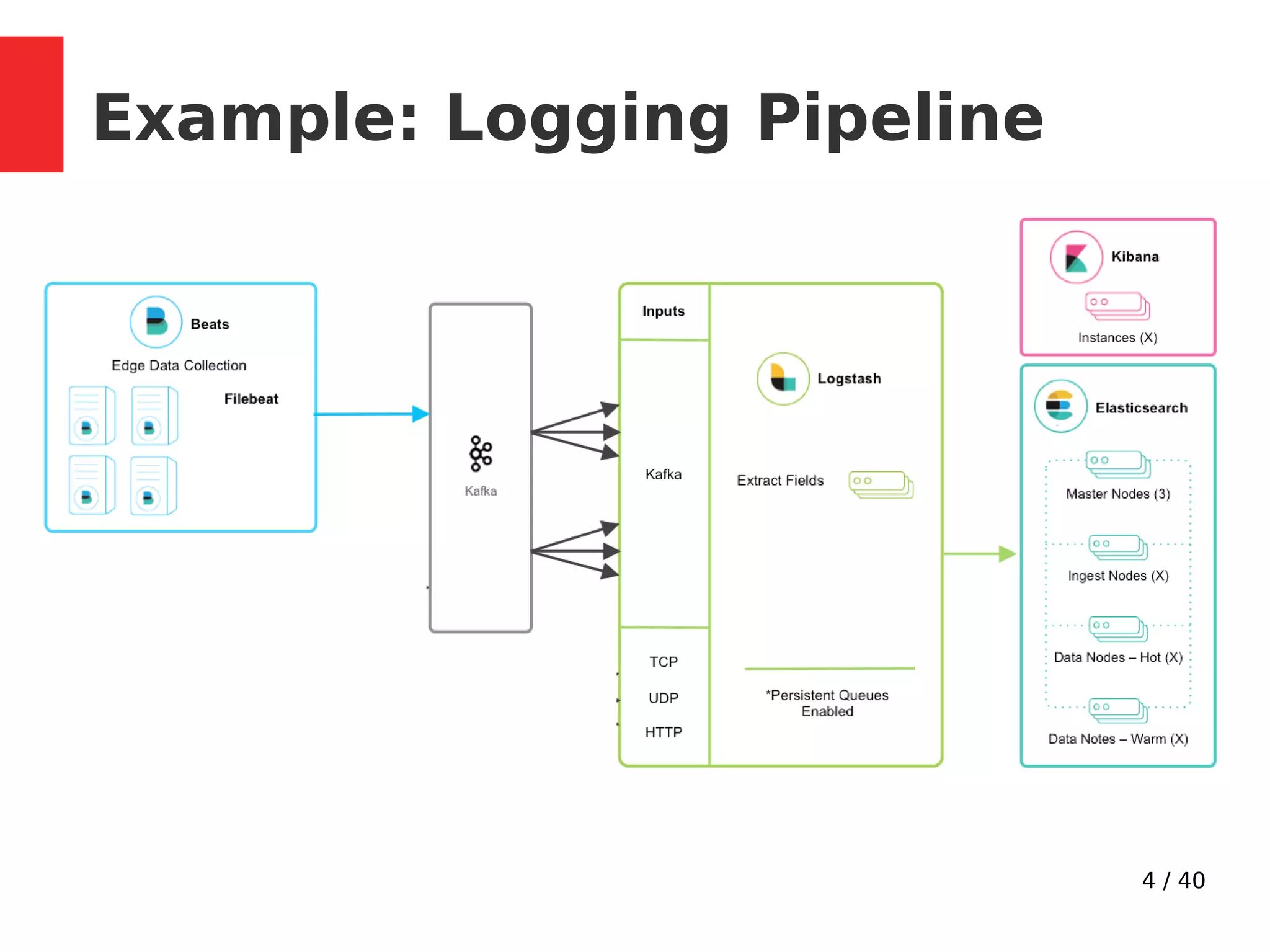
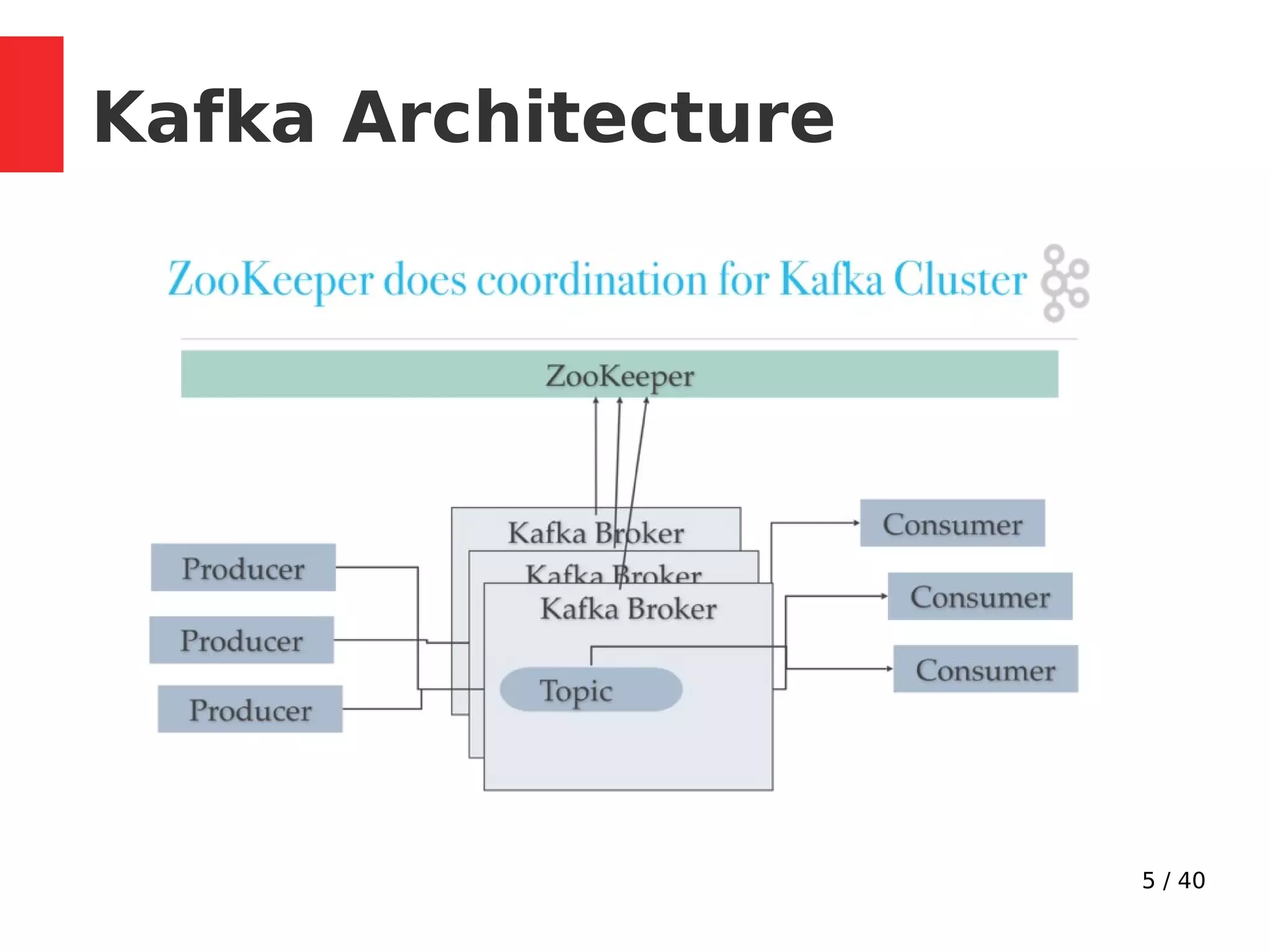
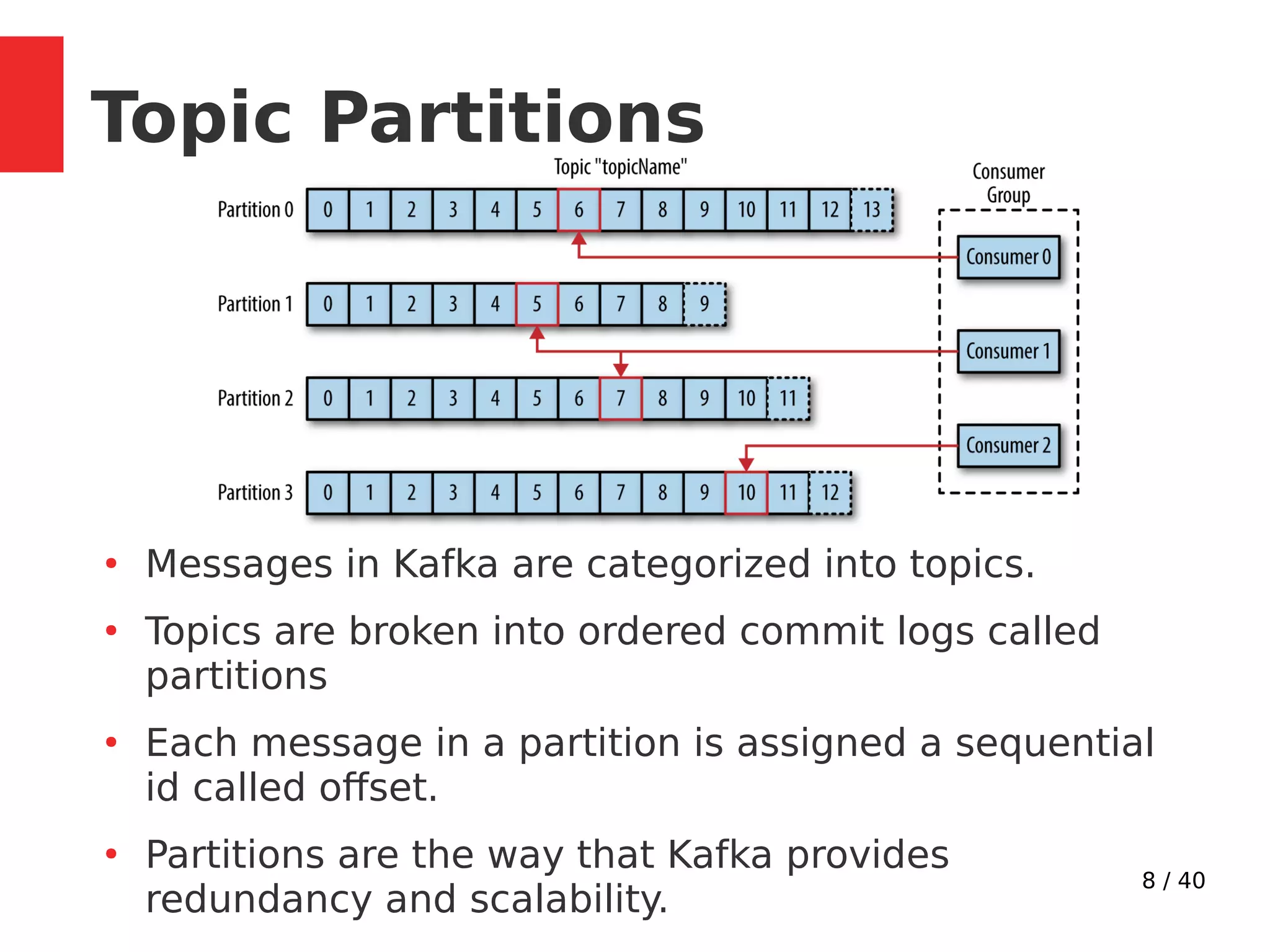
This document provides an overview of Apache Kafka. It describes Kafka as a distributed publish-subscribe messaging system with a distributed commit log that provides high-throughput and low-latency processing of streaming data. The document covers Kafka concepts like topics, partitions, producers, consumers, replication, and reliability guarantees. It also discusses Kafka architecture, performance optimizations, configuration parameters for durability and reliability, and use cases for activity tracking, messaging, metrics, and stream processing.










![15 / 40
●
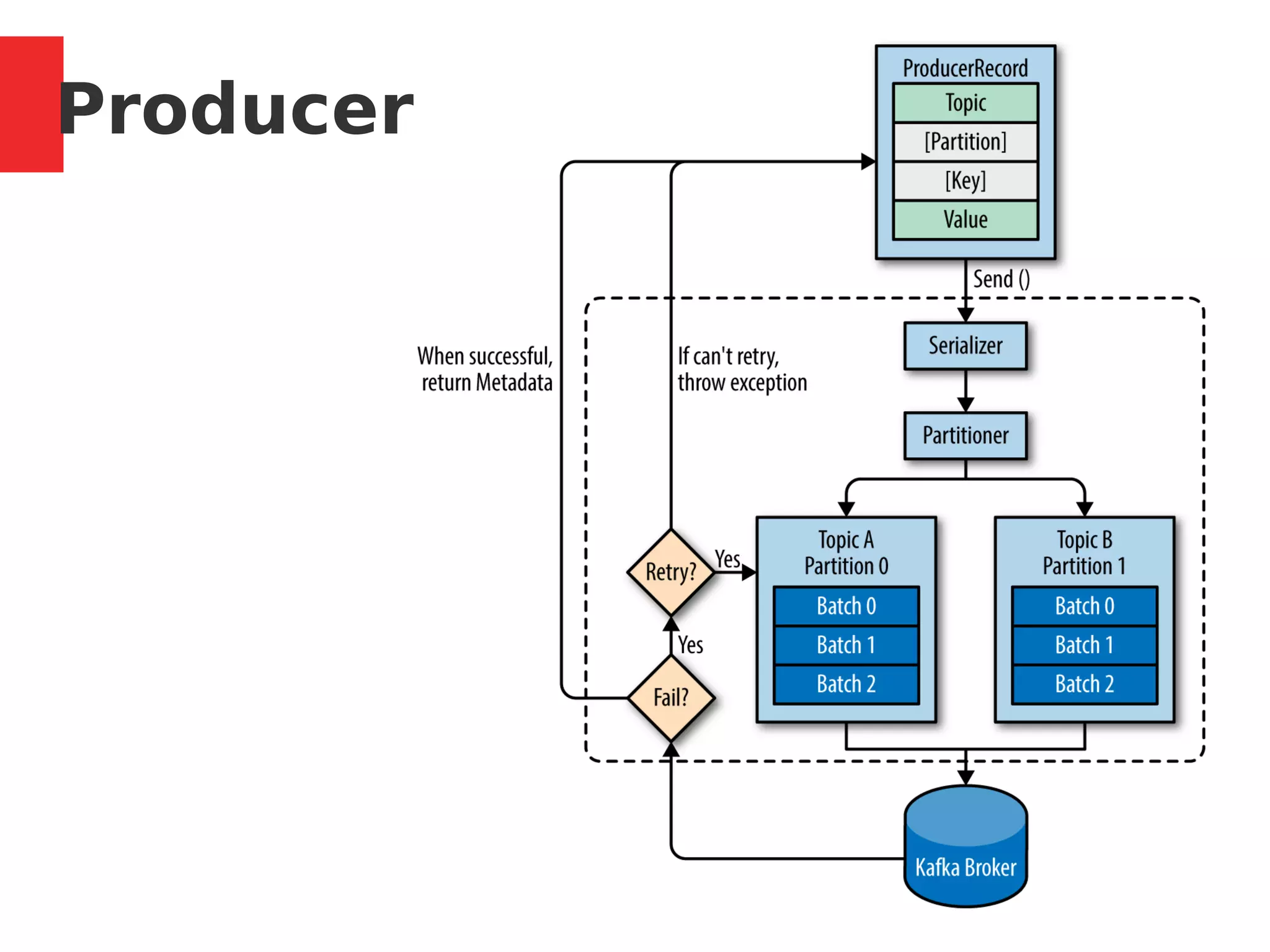
Default Partitioner: Round-robin, used if Key not
specified.
●
Hashing partitioner is used if key is provided,
hashing over all partitions, not just available ones.
●
Define custome partitioner
●
Returns RecordMetadata: [topic, partition, offset]
●
max.in.flight.requests.per.connection: how many
messages to send without receiving responses
●
When a producer firsts connect, it issues a Metadata
request, with the topics you are publishing to, and
the broker replies with which broker has which
partition.
Producer](https://image.slidesharecdn.com/kafkainaction-171217094712/75/Kafka-in-action-Tech-Talk-Paytm-15-2048.jpg)
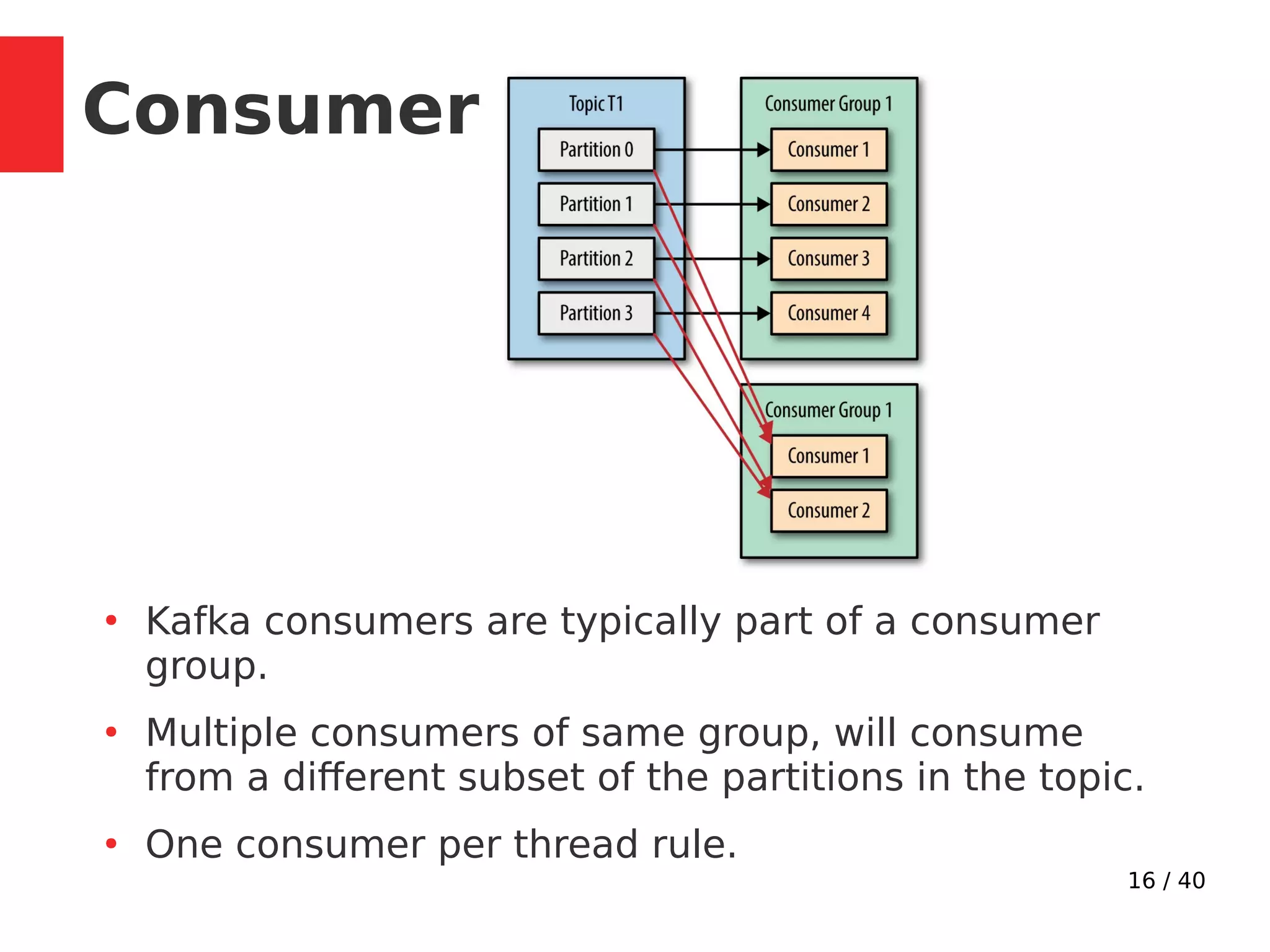
![17 / 40
●
Consumer keep track of consumed messages by
saving offset position in kafka.
●
__consumer_offsets topic: [partition key: groupId,
topic and partition number] > offset
●
When consumers are added or leave, partitions are
re-allocated. Moving partition ownership from one
consumer to another is called a rebalance.
●
Rebalances provide the consumer group with high
availability and scalability.
Consumer](https://image.slidesharecdn.com/kafkainaction-171217094712/75/Kafka-in-action-Tech-Talk-Paytm-17-2048.jpg)







































![[오픈소스컨설팅] 서비스 메쉬(Service mesh)](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsultingservicemesh-210531074807-thumbnail.jpg?width=640&height=640&fit=bounds)
















































