





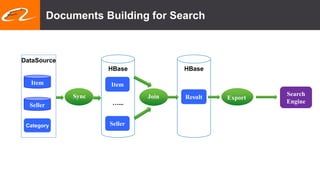

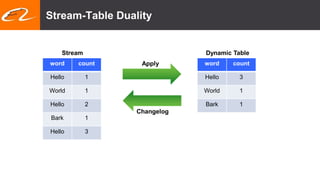
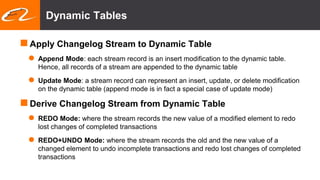
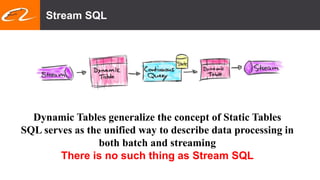

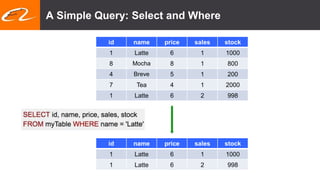





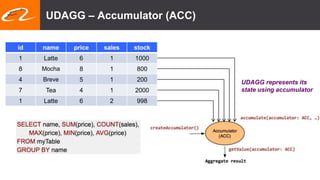

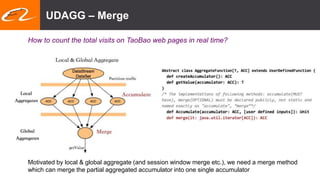
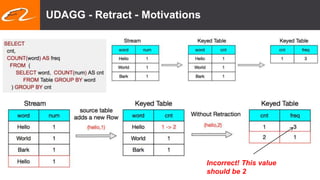
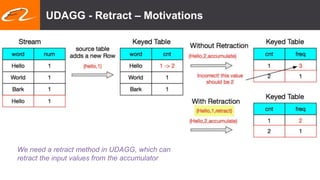
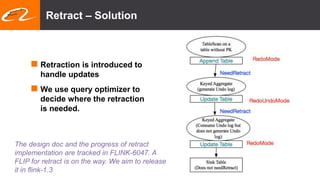







This document summarizes recent improvements to Flink SQL and Table API by Blink, Alibaba's distribution of Flink. Key improvements include support for stream-stream joins, user-defined functions, table functions and aggregate functions, retractable streams, and over/group aggregates. Blink aims to make Flink work well at large scale for Alibaba's search and recommendation systems. Many of the improvements will be included in upcoming Flink releases.























































































