Download as PDF, PPTX


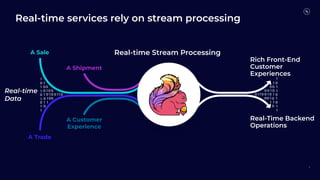


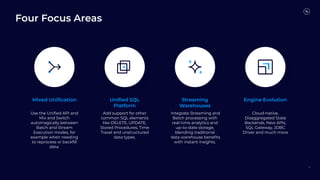


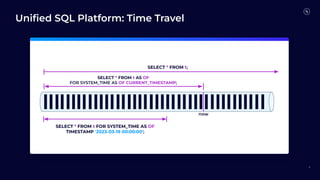


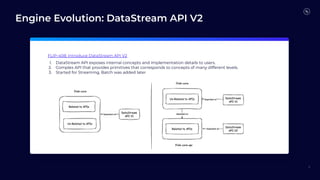





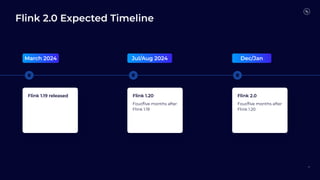



Flink 2.0 focuses on unified stream and batch processing capabilities with enhancements in language and API support, including fault tolerance, improved SQL functions, and dynamic table management. Future developments will revolve around mixed unification, a unified SQL platform, streaming warehouses, and engine evolution for better performance and usability. The timeline indicates Flink 1.19's release in March 2024, followed by subsequent versions with incremental improvements.






















































































