Downloaded 21 times





![© 2019 dA Platform6
FLINK’S POWERFUL ABSTRACTIONS
Process Function (events, state, time)
DataStream API (streams, windows)
SQL / Table API (dynamic tables)
Stream- & Batch
Data Processing
High-level
Analytics API
Stateful Event-
Driven Applications
val stats = stream
.keyBy("sensor")
.timeWindow(Time.seconds(5))
.sum((a, b) -> a.add(b))
def processElement(event: MyEvent, ctx: Context, out: Collector[Result]) = {
// work with event and state
(event, state.value) match { … }
out.collect(…) // emit events
state.update(…) // modify state
// schedule a timer callback
ctx.timerService.registerEventTimeTimer(event.timestamp + 500)
}
Layered abstractions to
navigate simple to complex use cases](https://image.slidesharecdn.com/flinksqlinaction-190202191728/85/Webinar-Flink-SQL-in-Action-Fabian-Hueske-6-320.jpg)




![© 2019 dA Platform15
SQL Feature Set in Flink 1.7.0
STREAMING ONLY
• OVER / WINDOW
‒ UNBOUNDED / BOUNDED PRECEDING
• INNER JOIN with time-versioned
• MATCH_RECOGNIZE
‒ Pattern Matching/CEP (SQL:2016)
BATCH ONLY
• UNION / INTERSECT / EXCEPT
• ORDER BY
STREAMING & BATCH
• SELECT FROM WHERE
• GROUP BY [HAVING]
‒ Non-windowed
‒ TUMBLE, HOP, SESSION windows
• JOIN
‒ Time-Windowed INNER + OUTER JOIN
‒ Non-windowed INNER + OUTER JOIN
• User-Defined Functions
‒ Scalar
‒ Aggregation
‒ Table-valued](https://image.slidesharecdn.com/flinksqlinaction-190202191728/85/Webinar-Flink-SQL-in-Action-Fabian-Hueske-15-320.jpg)











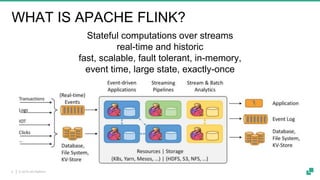
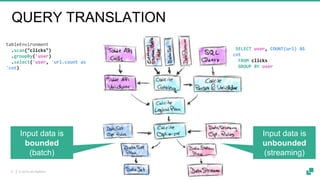
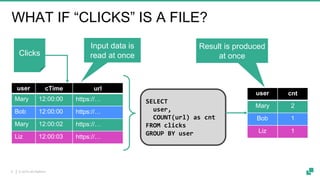
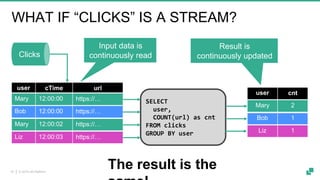
Apache Flink is a powerful streaming platform that supports stateful computations over both real-time and historical data, enabling fast, scalable, and fault-tolerant analytics. Its unified APIs allow for seamless processing of batch and streaming data using ANSI SQL syntax, making it easier for users to perform complex queries on both data types. The platform is widely used in production by major companies and supports a variety of applications, including data pipelines, real-time analytics, and interactive query capabilities.























































































