Downloaded 64 times




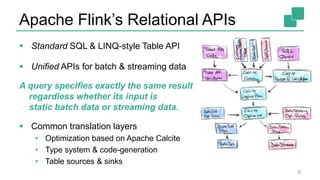

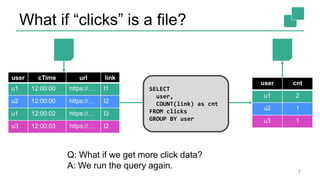


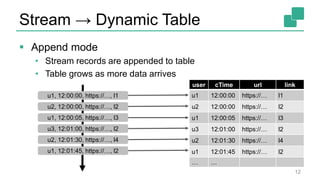
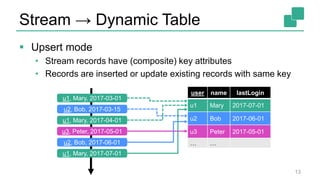
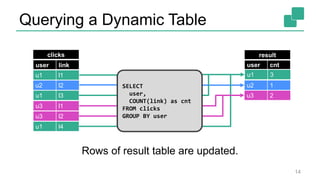

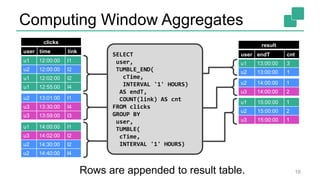

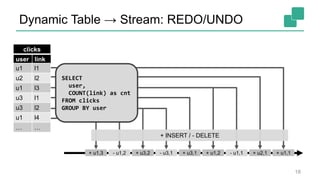
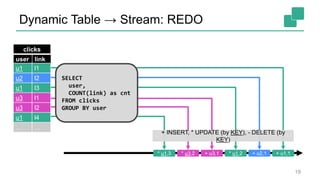



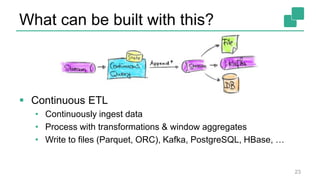






Fabian Hueske presented on stream analytics using SQL on Apache Flink. Flink provides a scalable platform for stream processing that is fast, accurate, and reliable. Its relational APIs allow querying both batch and streaming data using standard SQL or a LINQ-style Table API. Queries on streaming data produce continuously updating results. Windows can be used to compute aggregates over tumbling time intervals. The dynamic tables representing streaming data can be converted to output streams encoding updates as insertions and deletions. While not all queries can be supported, techniques like limiting state size allow bounding computational resources. Use cases like continuous ETL, dashboards, and event-driven architectures were discussed.











































































