Download as PDF, PPTX
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Learning deep mean field games for modeling large
population behavior"
or the intersection of machine learning and modeling collective processes](https://image.slidesharecdn.com/0323akuzawa-180323025543/85/DL-Learning-Deep-Mean-Field-Games-for-Modeling-Large-Population-Behavior-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Learning deep mean field games for modeling large
population behavior"
or the intersection of machine learning and modeling collective processes](https://image.slidesharecdn.com/0323akuzawa-180323025543/75/DL-Learning-Deep-Mean-Field-Games-for-Modeling-Large-Population-Behavior-1-2048.jpg)





![( ) Multi Agent Reinforcement Learning (MARL)
• Mean Field Multi-Agent Reinforcement Learning (Yang+ 2018)
• MARL
ØMARL j : !"
#
$, & = (#
$, & + *+,-~/(,-|&,,)[4"
#
($5
)]
Ø(#
$, & , 7($5
|&, $) &
Ø
•](https://image.slidesharecdn.com/0323akuzawa-180323025543/85/DL-Learning-Deep-Mean-Field-Games-for-Modeling-Large-Population-Behavior-11-320.jpg)

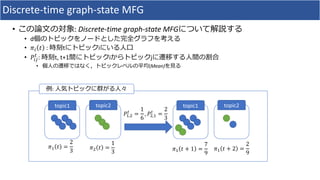
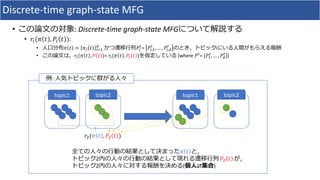
![Discrete-time graph-state MFG
• MFG
• !"
#
= max
()
*
[," -#
, /"
#
+ ∑2 /"2
#
!2
#34
] (backward Hamilton-Jacobi-Bellman equation, HJB)
• -"
#34
= ∑2 /2"
#
-2
#
(forward Fokker-Planck equation)
• !"
6
: t i ( )
• -7
, !8
, ," -#
, /"
#
Dynamic Programing Trajectory -#
, !#
#97
8
• ," -#
, /"
#
•
ØHJB: Nash-Maximizer /"
#](https://image.slidesharecdn.com/0323akuzawa-180323025543/85/DL-Learning-Deep-Mean-Field-Games-for-Modeling-Large-Population-Behavior-15-320.jpg)



![Inference on MFG via MDP optimization
•
1. ( ⇄ )
2.
3.
• MFG MDP
Øsingle-agent RL V∗
(%&
) = max
,
[. %&
, 0 + V∗
%&23
]
Ø ⇄
ØMDP](https://image.slidesharecdn.com/0323akuzawa-180323025543/85/DL-Learning-Deep-Mean-Field-Games-for-Modeling-Large-Population-Behavior-19-320.jpg)

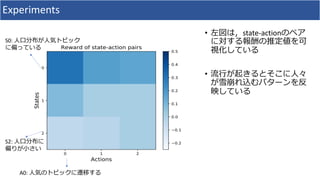
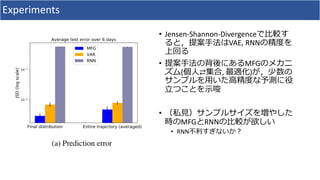
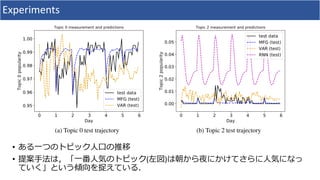
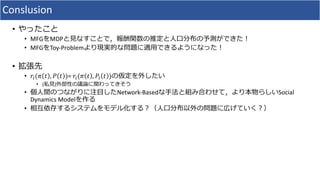




1. The document discusses using deep learning and mean field games to model collective behavior in large populations. 2. It proposes modeling collective behavior as a discrete-time graph-state mean field game and inferring the mean field game via Markov decision process optimization. 3. Experiments on modeling Twitter topics over time using this approach showed it outperformed vector autoregression and RNN baselines.



































































