
Downloaded 173 times

































![[~] $ Questions_?](https://image.slidesharecdn.com/sr-170427000436/75/Speech-Recognition-System-45-2048.jpg)
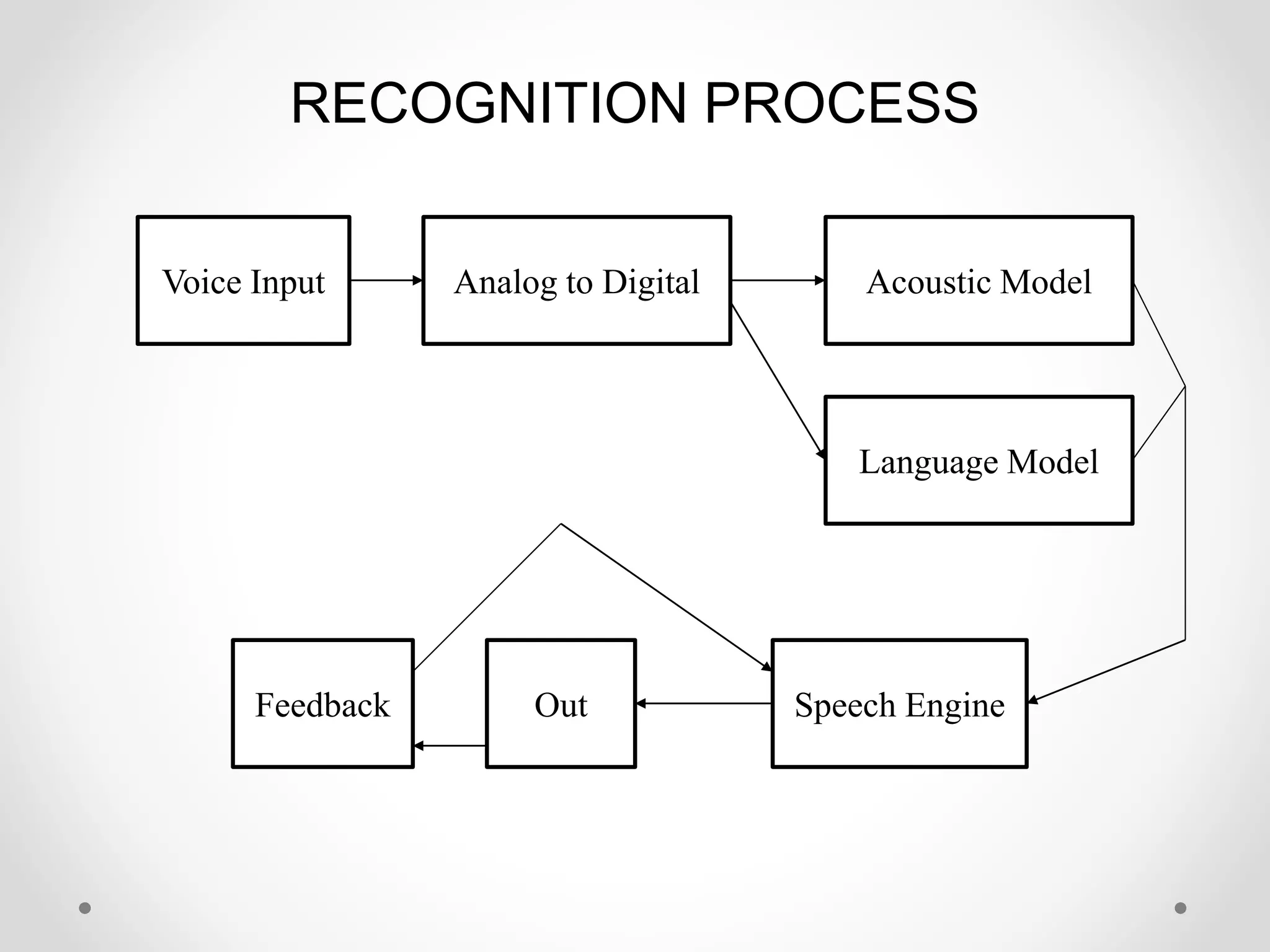
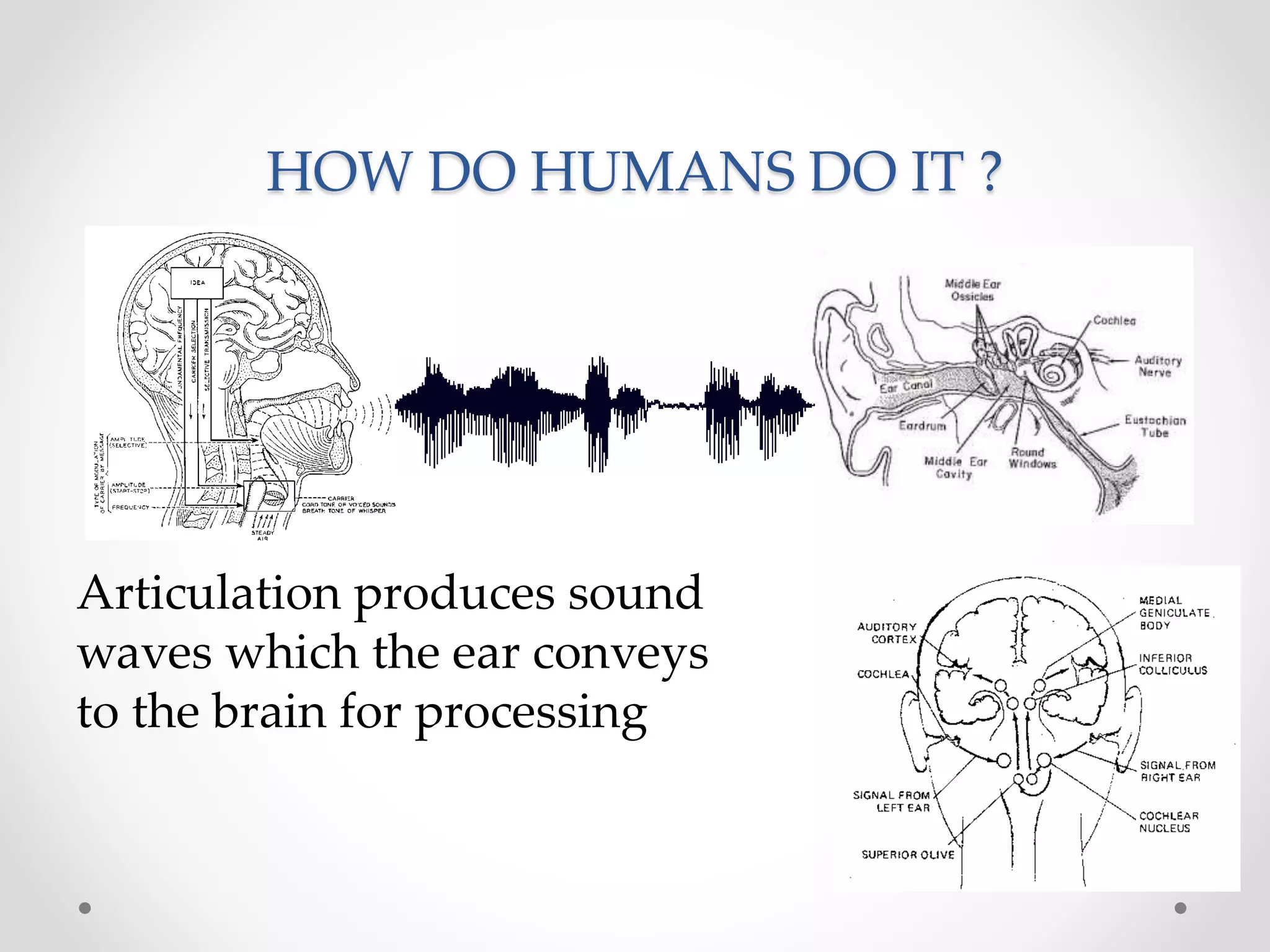
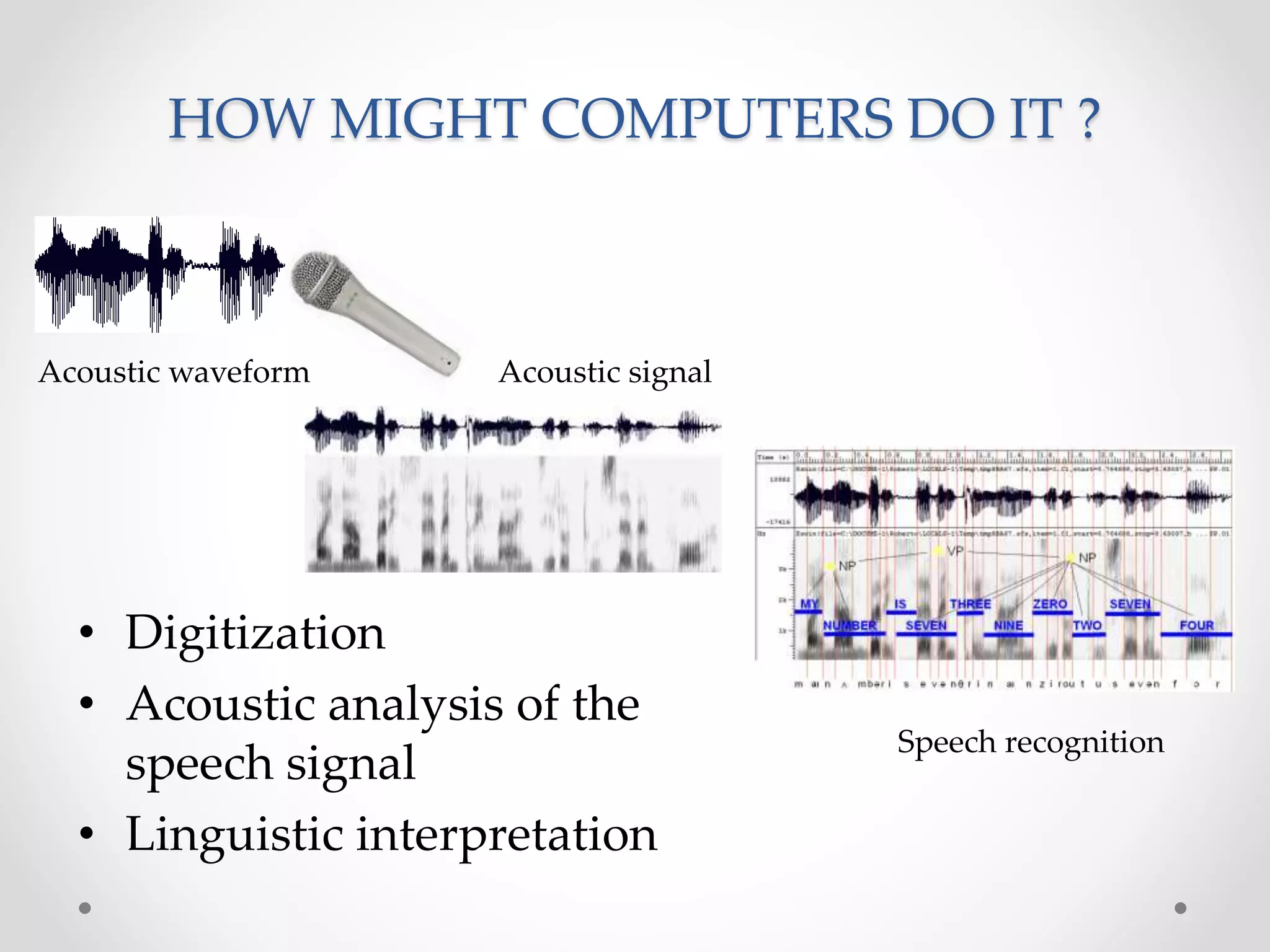
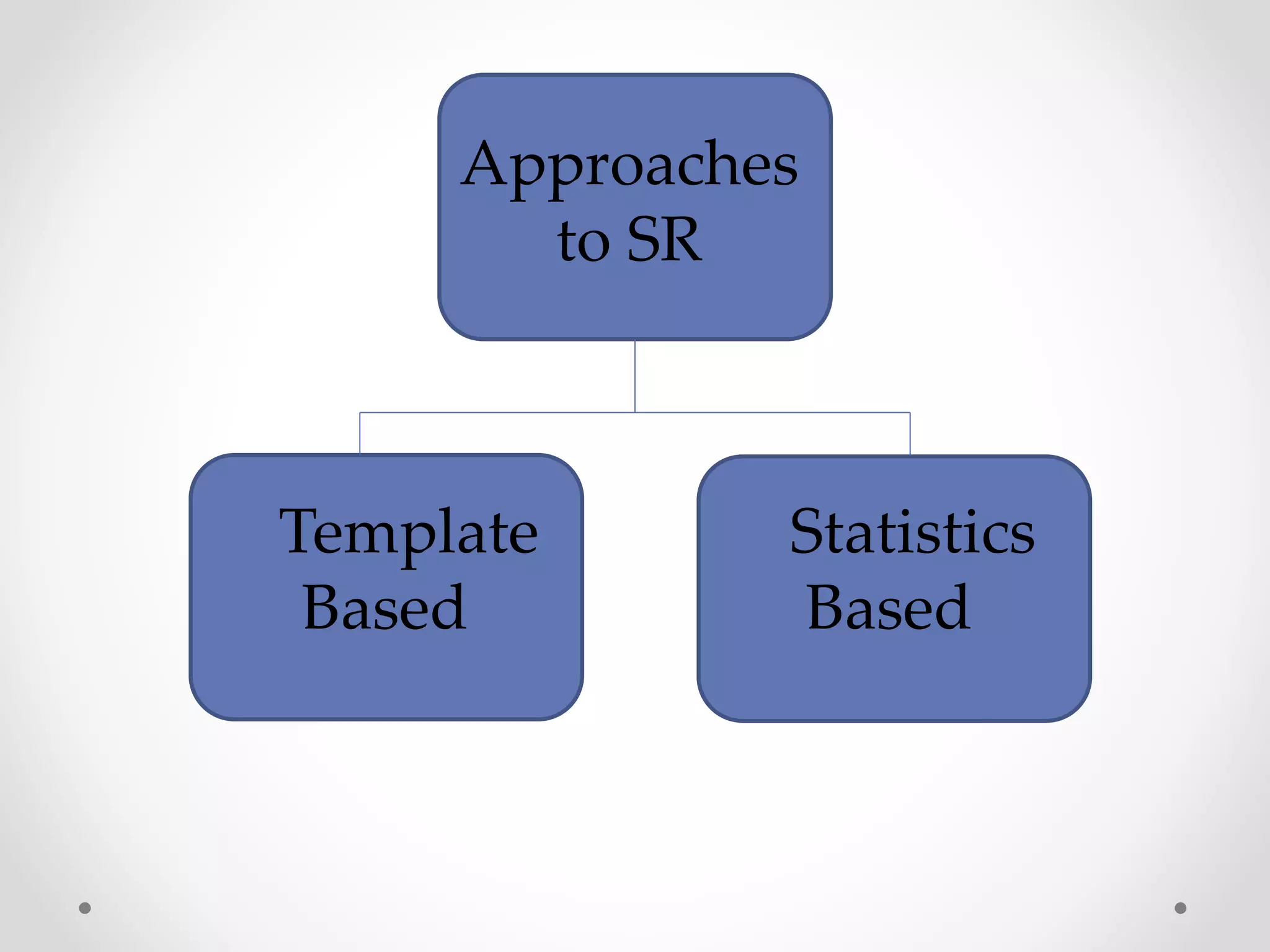
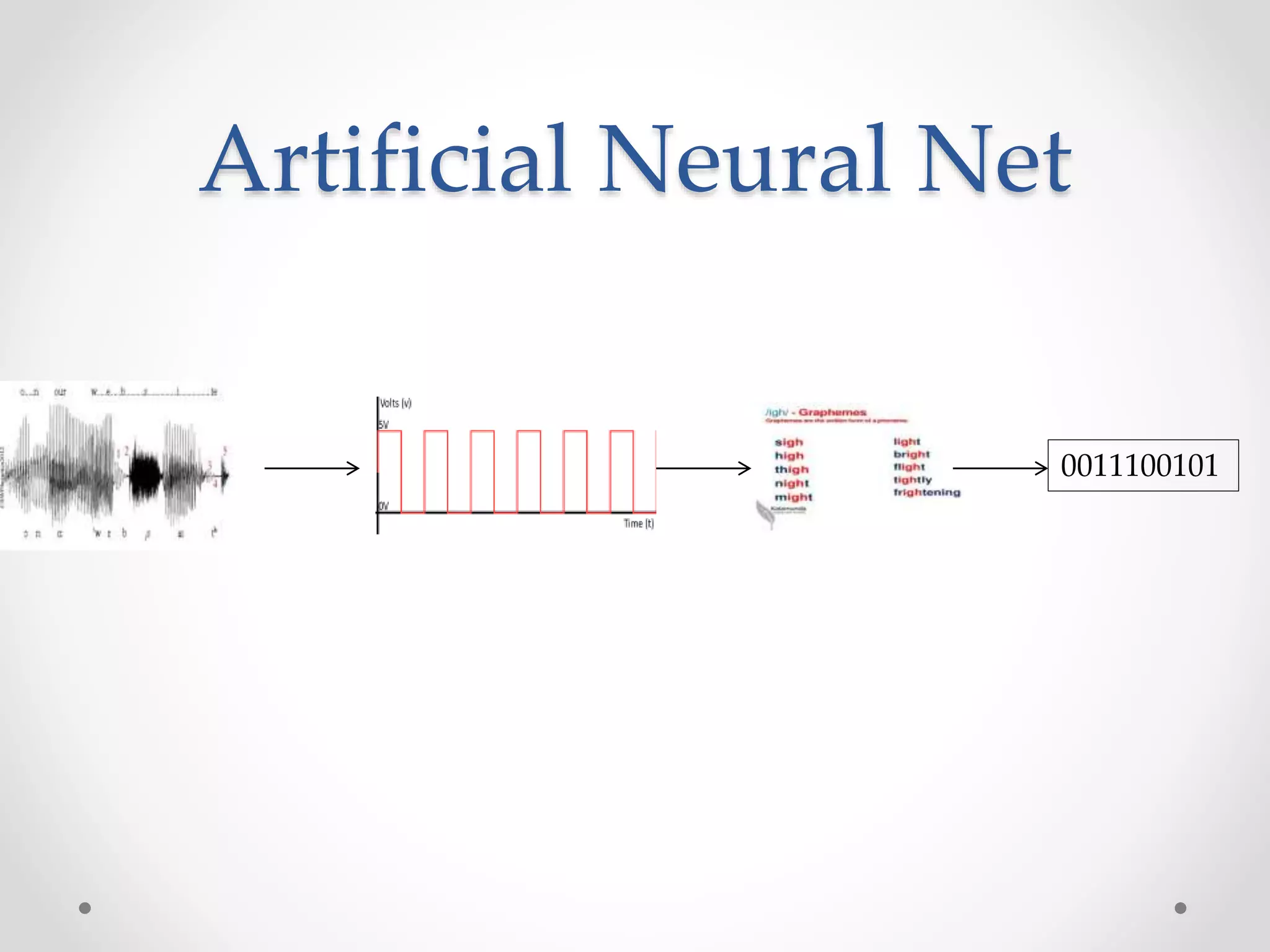
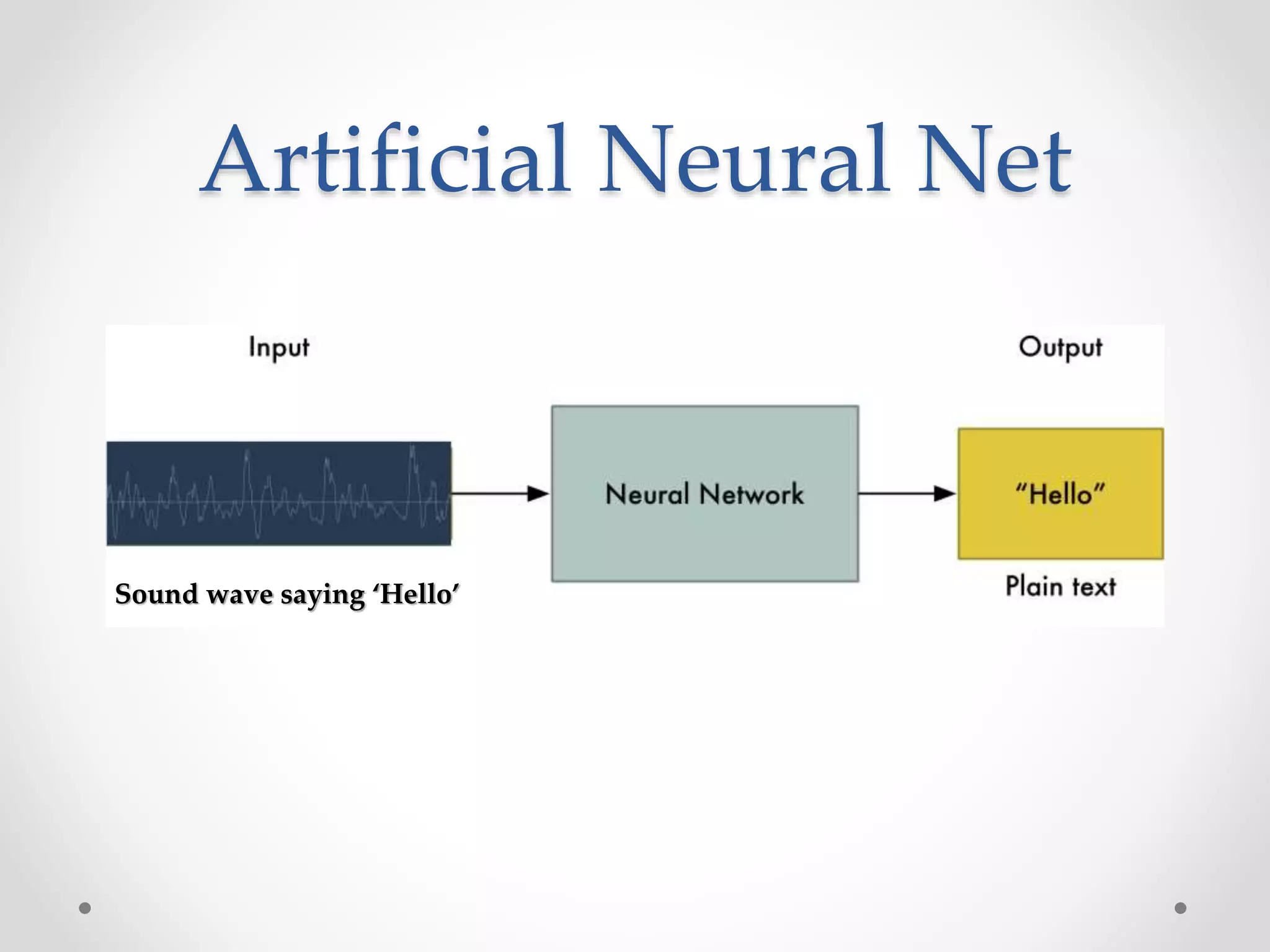
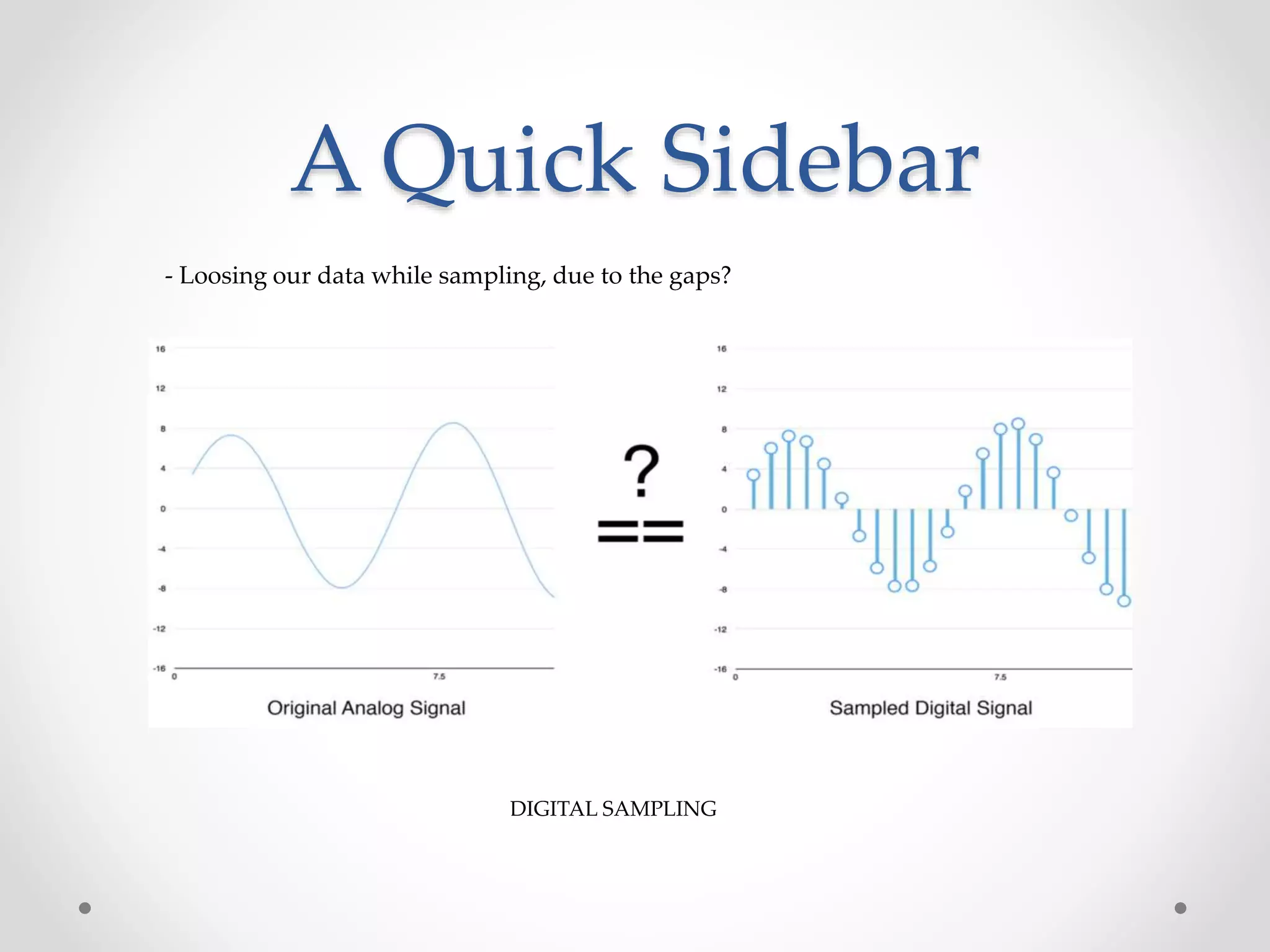
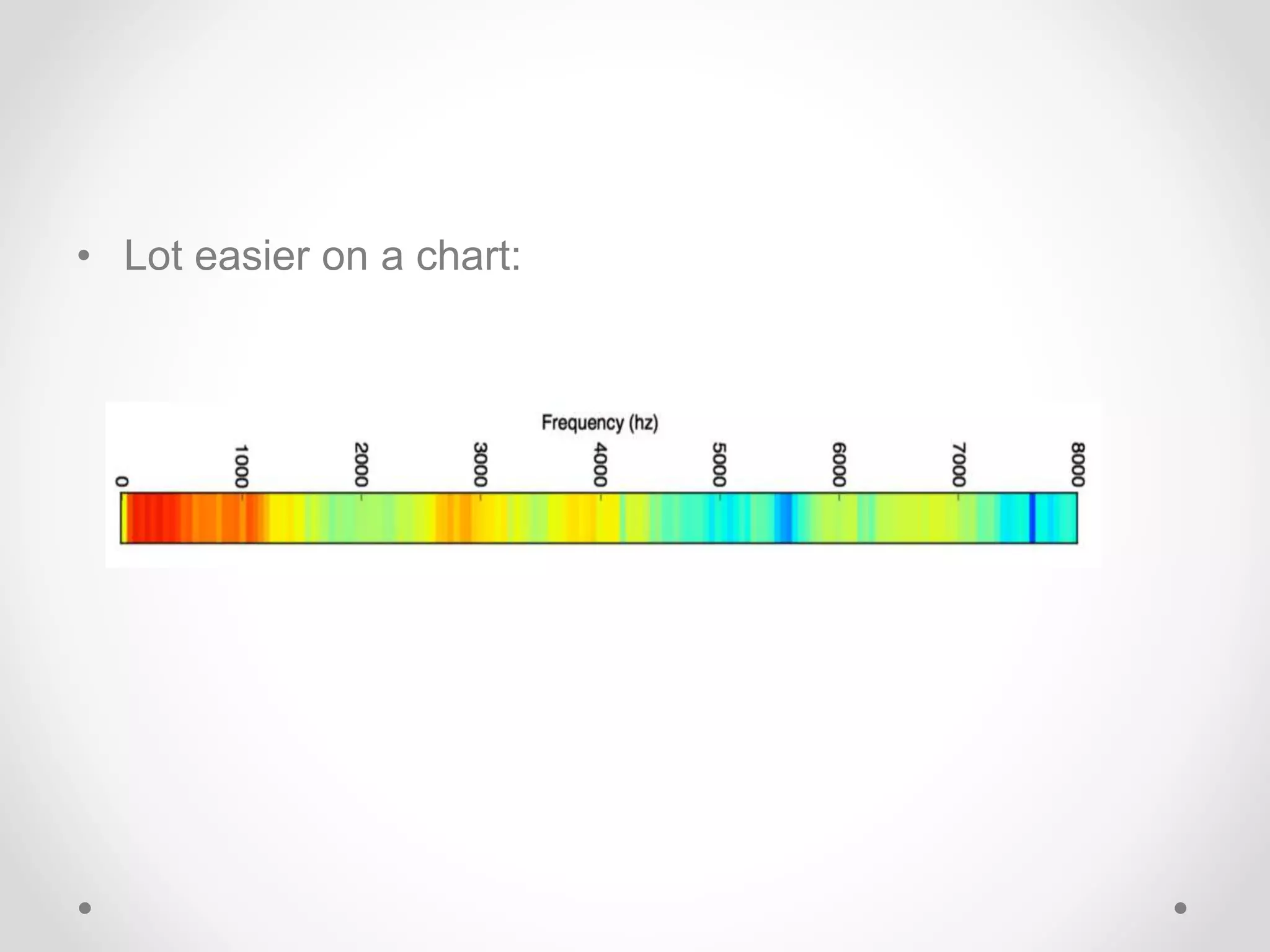
Speech recognition is a technology that translates spoken language into text, with applications ranging from medical transcription to home automation. The recognition process involves voice input digitization, phonetic breakdown, statistical modeling, and matching to produce accurate text outputs. Over the decades, advancements in hardware and algorithms have significantly improved the accuracy and capabilities of speech recognition systems, culminating in their integration into everyday devices like smartphones and smart home technologies.



































































