Download as PDF, PPTX




![Example - Join multiple sources
SELECT
country,
approx_percentile(date_diff('year', birthdate, now()), array[0.25, 0.5, 0.75])
FROM
elasticsearch.default."movies: overview:space~ +fiction" movies
JOIN hive.default.views USING (movie_id)
JOIN mysql.default.users USING (user_id)
GROUP BY ROLLUP(country)
Per country age distribution of people that watched space fiction movies](https://image.slidesharecdn.com/5presto-191108231248/85/Presto-Query-Anything-Data-Engineer-s-perspective-5-320.jpg)



![Recent Improvements (last ~10 months)
● FETCH FIRST … WITH TIES syntax
● OFFSET syntax
● COMMENT ON <table> IS …
● [LEFT/RIGHT/FULL] JOIN LATERAL (…) ON
● IGNORE NULLS for window functions
● .* for ROW expressions
● Pass-through security (client provided
credentials)
● Impersonation for Hive Metastore
● Kerberos security improvements
● Support for Hadoop KMS
● Role-based security
● Secure query results in client API
● Current user security mode for views
● Support for Azure Data Lake
● Hive Bucketing V2
● Docker image
● Spill-to-disk improvements
● CLI output formats
● Syntax highlighting in CLI
● UUID type and functions
● format(), combinations() functions
● ORC bloom filters (non-legacy)
● Connector-provided view definitions
● Elasticsearch Connector
● Google Sheets Connector
● Amazon Kinesis Connector
● Apache Phoenix Connector
● LZ4/ZSTD support for ORC/Parquet
● More type mappings for various connectors
● Performance improvements for GCS and S3
● Performance improvements for UNNEST
… and more! https://prestosql.io/docs/current/release.htm](https://image.slidesharecdn.com/5presto-191108231248/85/Presto-Query-Anything-Data-Engineer-s-perspective-10-320.jpg)





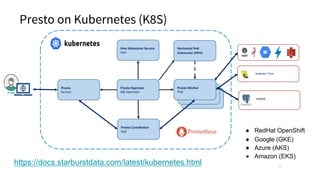



The document discusses Presto, a community-driven open-source SQL query engine that allows for high-performance data analysis without vendor lock-in. Key features include cost-based optimization, multi-threaded execution, and seamless querying across various data sources. Additionally, it highlights community contributions, recent improvements, and how Starburst enhances Presto with enterprise solutions and orchestration capabilities.























































































