Download as PDF, PPTX



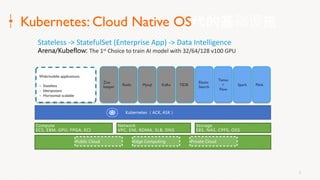

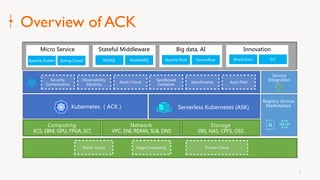


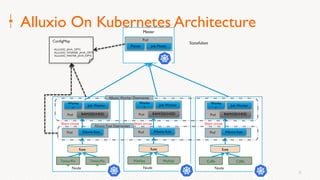
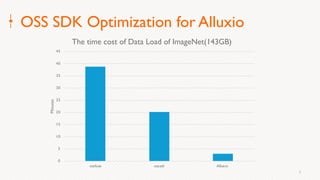


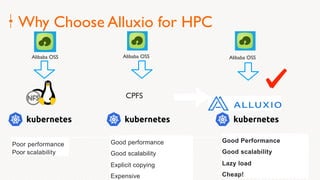
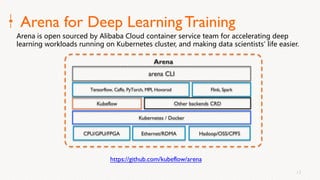

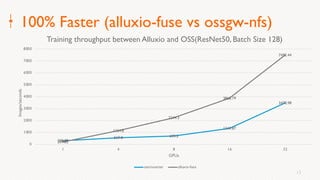
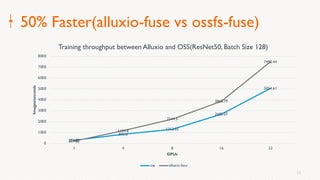
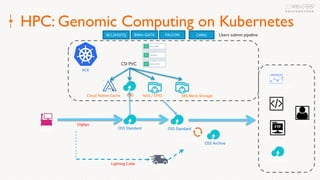
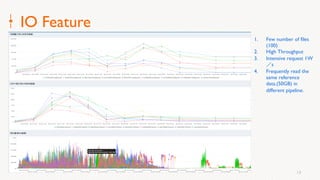
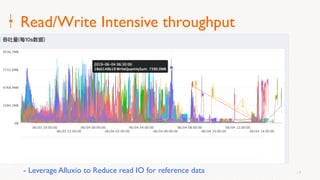











Eric Li, Senior Architect of Alibaba Cloud, presented on using Alluxio on Kubernetes. He discussed: 1. The challenges of deploying Alluxio on Kubernetes, including how to deploy it in a Kubernetes-native way, how applications can access data without changes, and how to achieve best Alluxio performance. 2. Optimizations made to Alluxio including a Helm chart for one-click installation, optimizations to the OSS SDK for data loading speed, and using fuse and short-circuiting for performance. 3. Best practices for using Alluxio on Kubernetes for different workloads like deep learning and genomic computing.























































































