Download to read offline






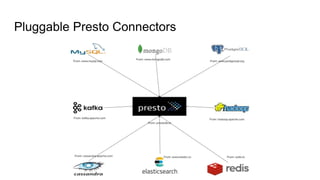

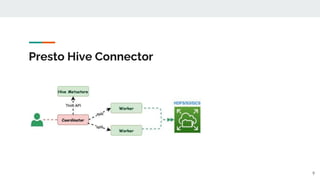
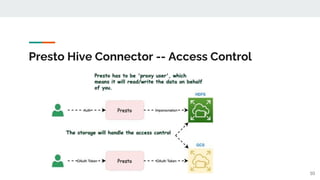

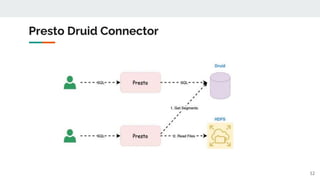
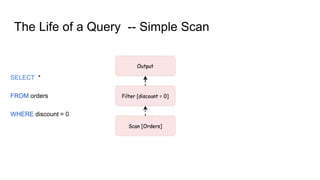





This document outlines a technical talk on Presto, a distributed SQL query engine that provides ANSI SQL access to various data sources like Hadoop and Kafka. It highlights Presto's scalable architecture, flexible connectors, and performance benefits, along with its use cases and query lifecycle. The document also discusses community engagement and resources for further learning about Presto.


































































