Download as PDF, PPTX

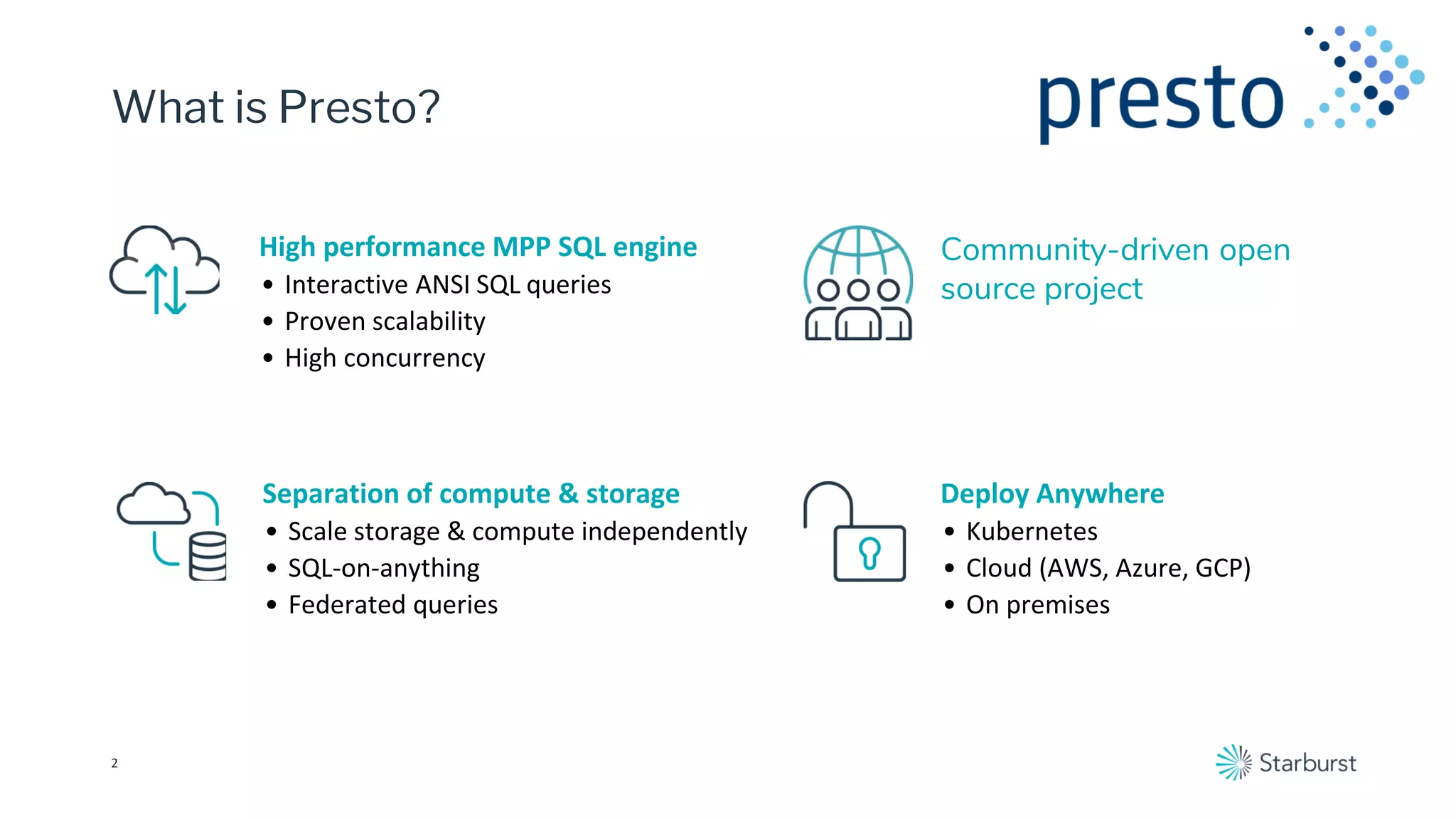


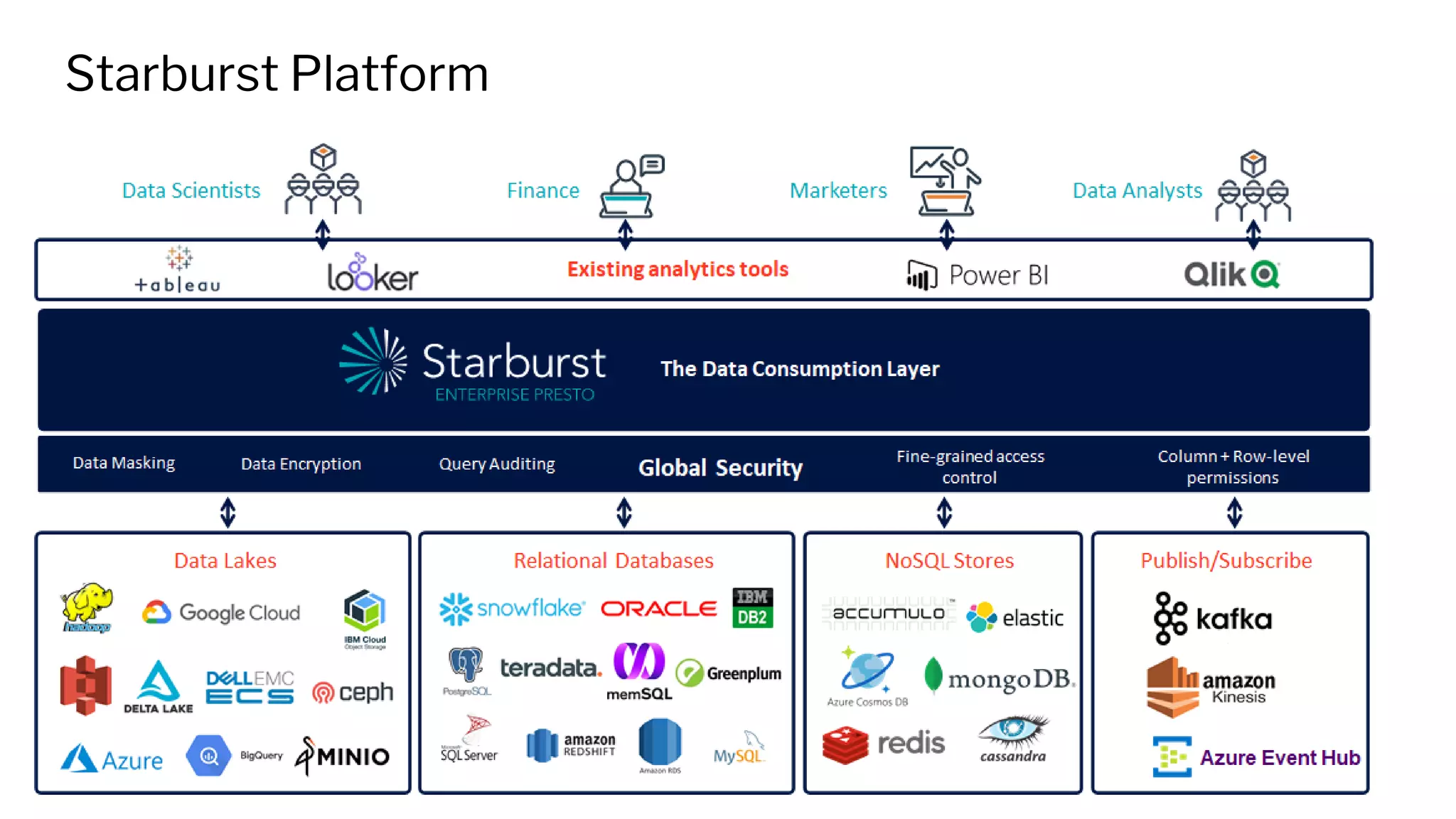

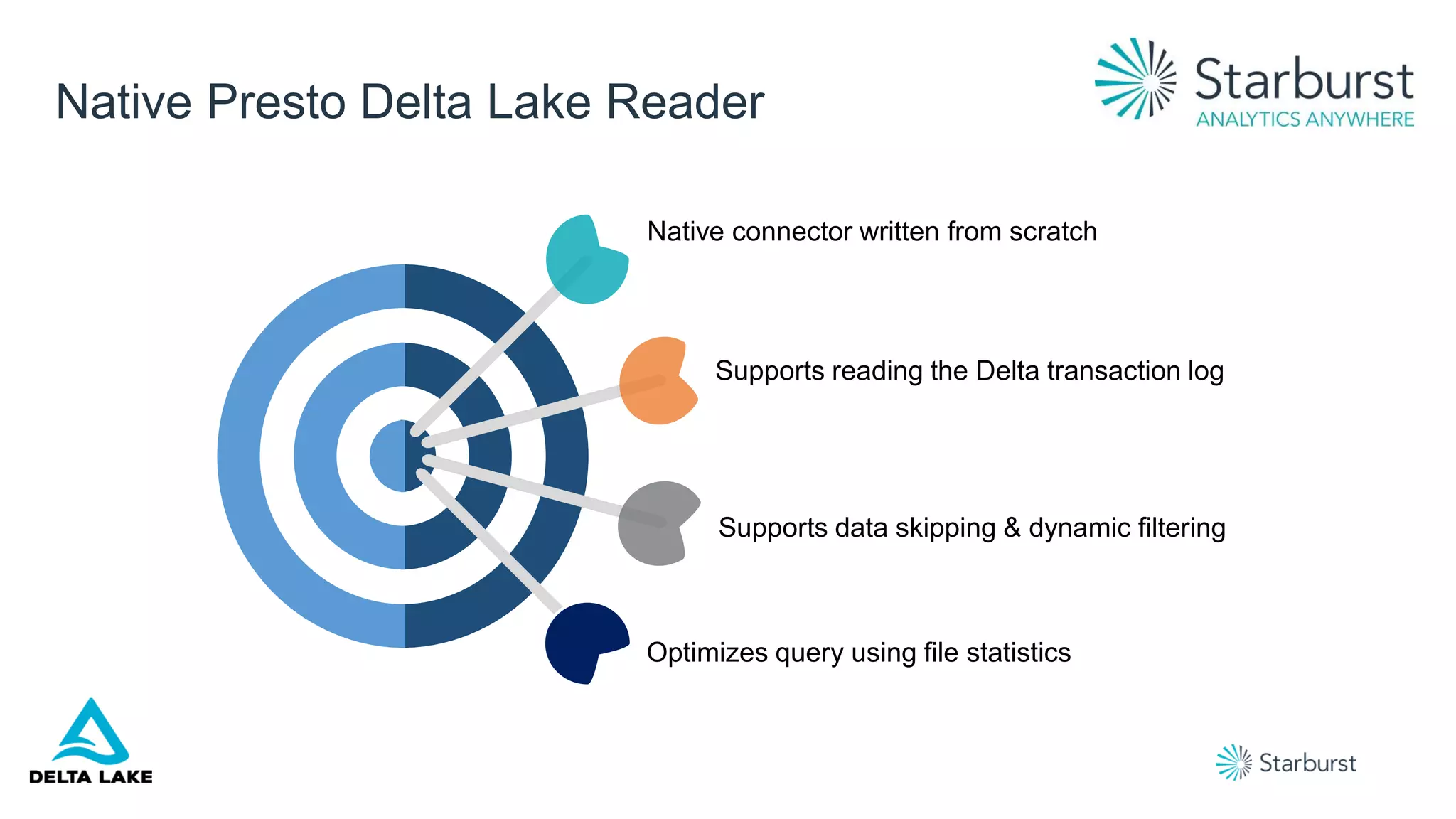
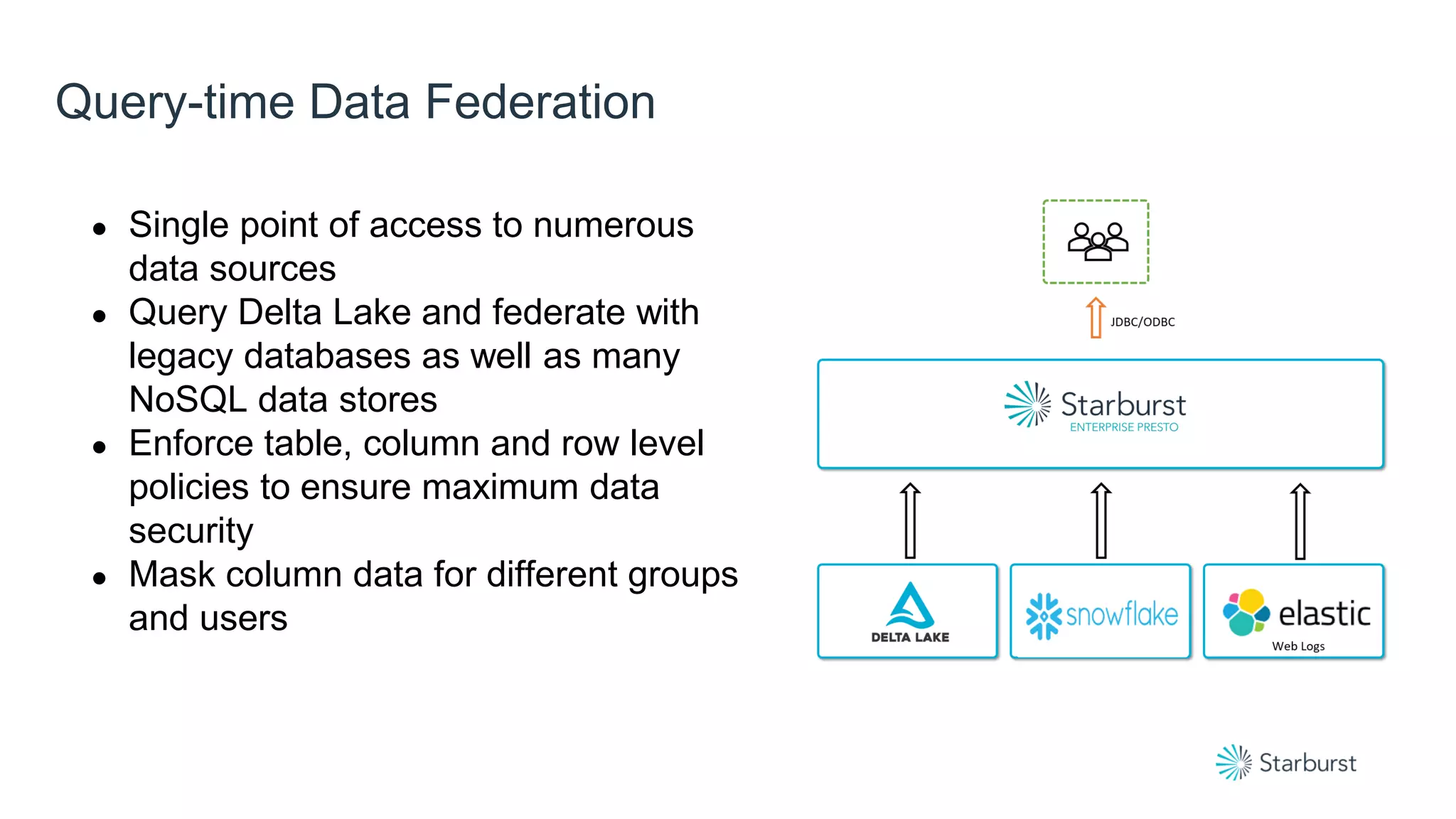



Presto is a high-performance, community-driven open-source SQL engine that enables interactive queries across various data sources, including cloud and on-premises environments. Starburst enhances Presto with enterprise-grade security, rapid insights, and support for a wide range of data types, benefiting numerous industries. The platform also integrates with Delta Lake to optimize data consumption and analytics, providing robust features like data federation and security policies.























































































