Download as PDF, PPTX





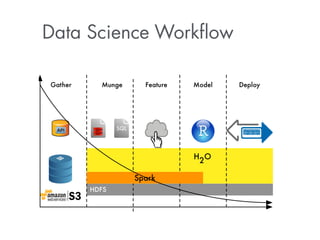



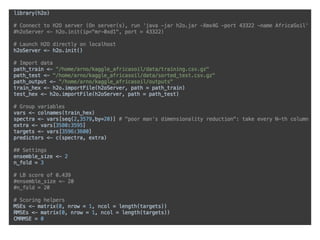


![Use hashing trick to reduce dimensionality N:
!
naive: input[key_to_idx(key)] = 1 //one-hot encoding
hash: input[hash_fun(key) % M] += 1, where M << N
E.g, M=1000 —> much faster training, rapid convergence!
Note:
Hashing trick is also used by winners of Kaggle
challenge, and the 4-th ranked submission uses an
Ensemble of Deep Learning models with some
feature engineering (drop rare categories etc)](https://image.slidesharecdn.com/h2odeeplearningarnocandel100914-141010010434-conversion-gate01/85/How-to-win-data-science-competitions-with-Deep-Learning-25-320.jpg)




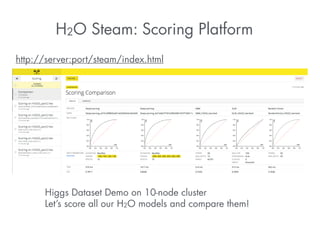
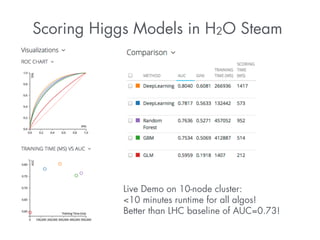






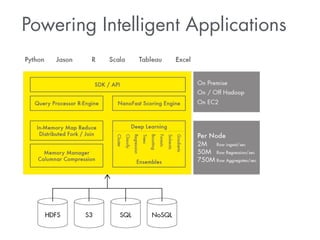
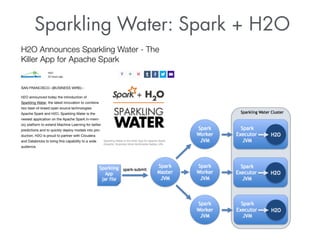
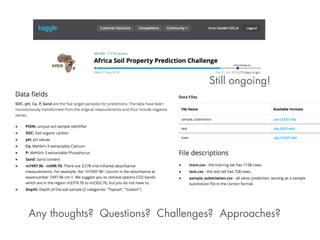
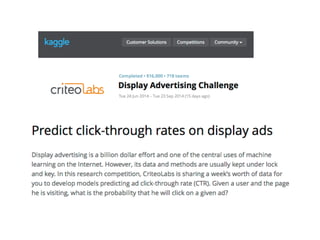
This document summarizes a presentation about how to win data science competitions using deep learning with H2O. It discusses H2O's architecture and capabilities for deep learning. It then demonstrates live modeling on Kaggle competitions, providing step-by-step explanations of building and evaluating deep learning models on three different datasets - an African soil properties prediction challenge, a display advertising challenge, and a Higgs boson machine learning challenge. It concludes with tips and tricks for deep learning with H2O and an invitation to the H2O World conference.























































































