Download as PDF, PPTX








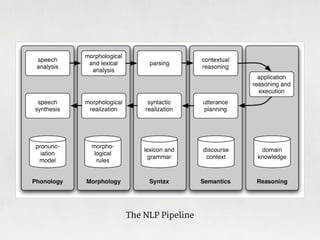

















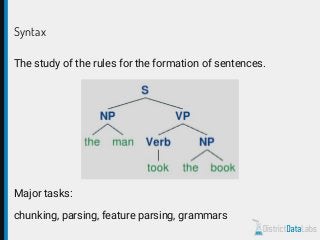




















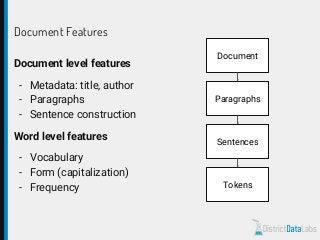
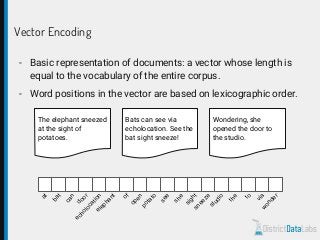
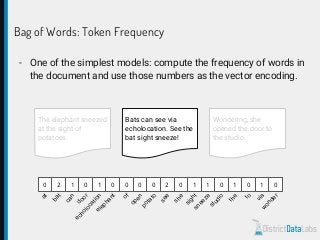
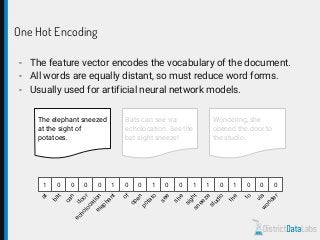
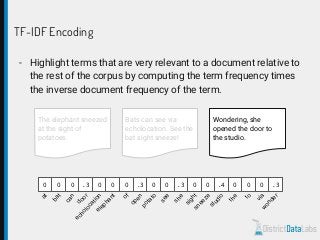



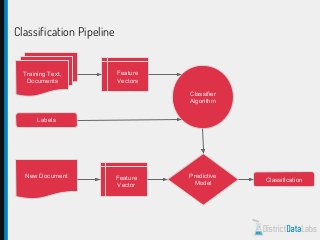
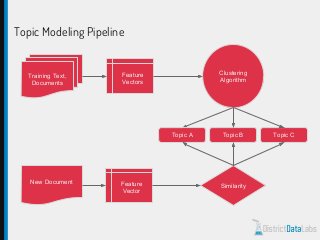






The document provides an overview of natural language processing (NLP) using Python, discussing the evolution of language study and the distinction between formal and natural languages. It addresses various NLP techniques, applications, and the Natural Language Toolkit (NLTK), emphasizing the importance of machine learning for flexibility in language understanding. Key tasks in NLP include classification, parsing, and feature extraction, with a focus on transforming raw language data for practical applications.























































































