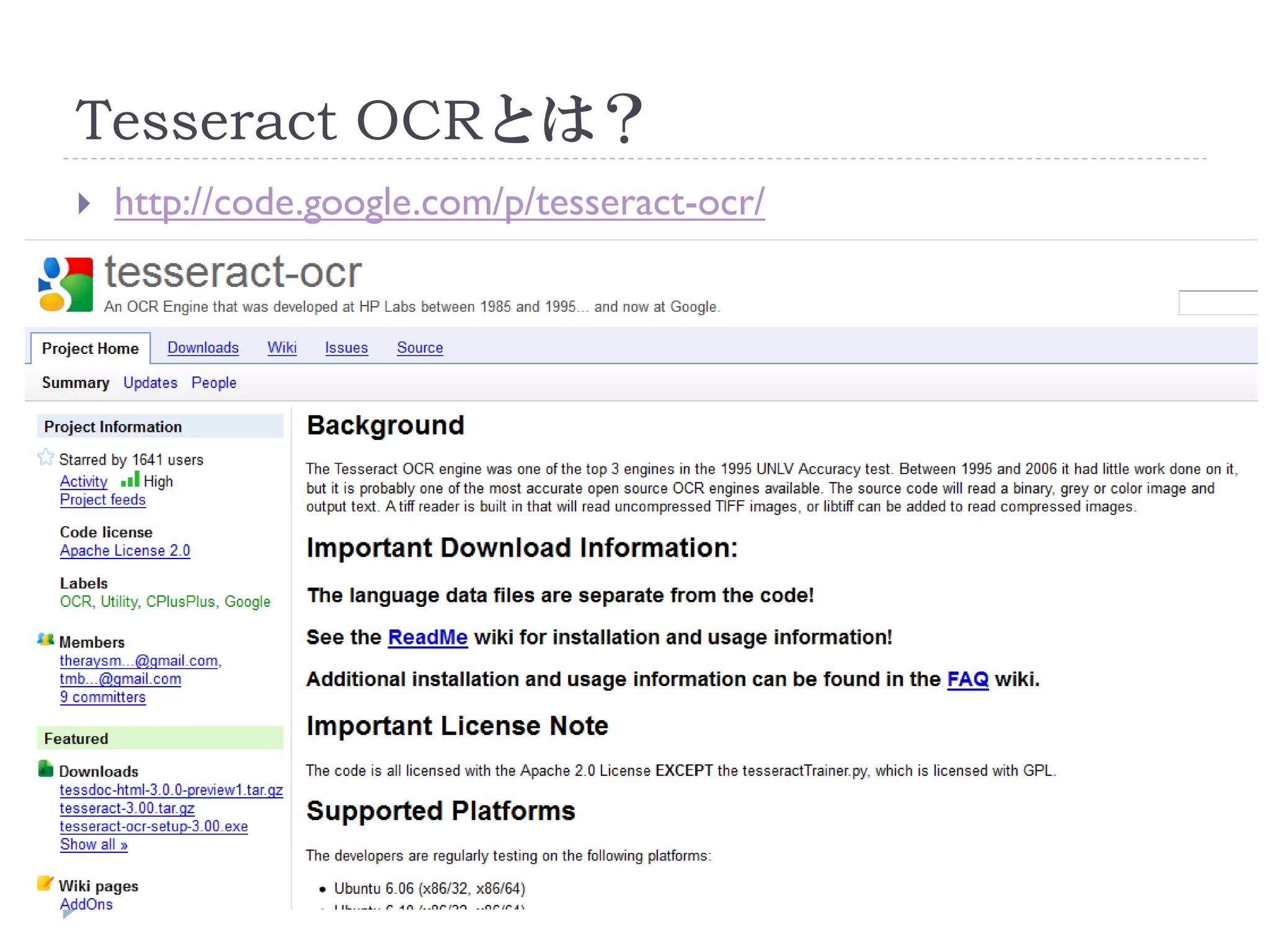
文字認識の結果例(英語)
1 Introduction
There hasbeen a steady increase in the performance of object category detection as measured bythe
annual PASCAL VOC challenges [3]. The training data provided for these challenges specifies if an
object is truncated » when the provided axis aligned bounding box does not cover the full extent of
the object. The principal cause of truncation is that the object partially lies outside Lhe image area.
Most participants simple disregard the truncated training instances and learn from the non-truncated
ones. This is a waste of training material, but more seriously many truncated instances are missed
in testing, signilicantly reducing the recall and hence decreasing overall recognition performance.






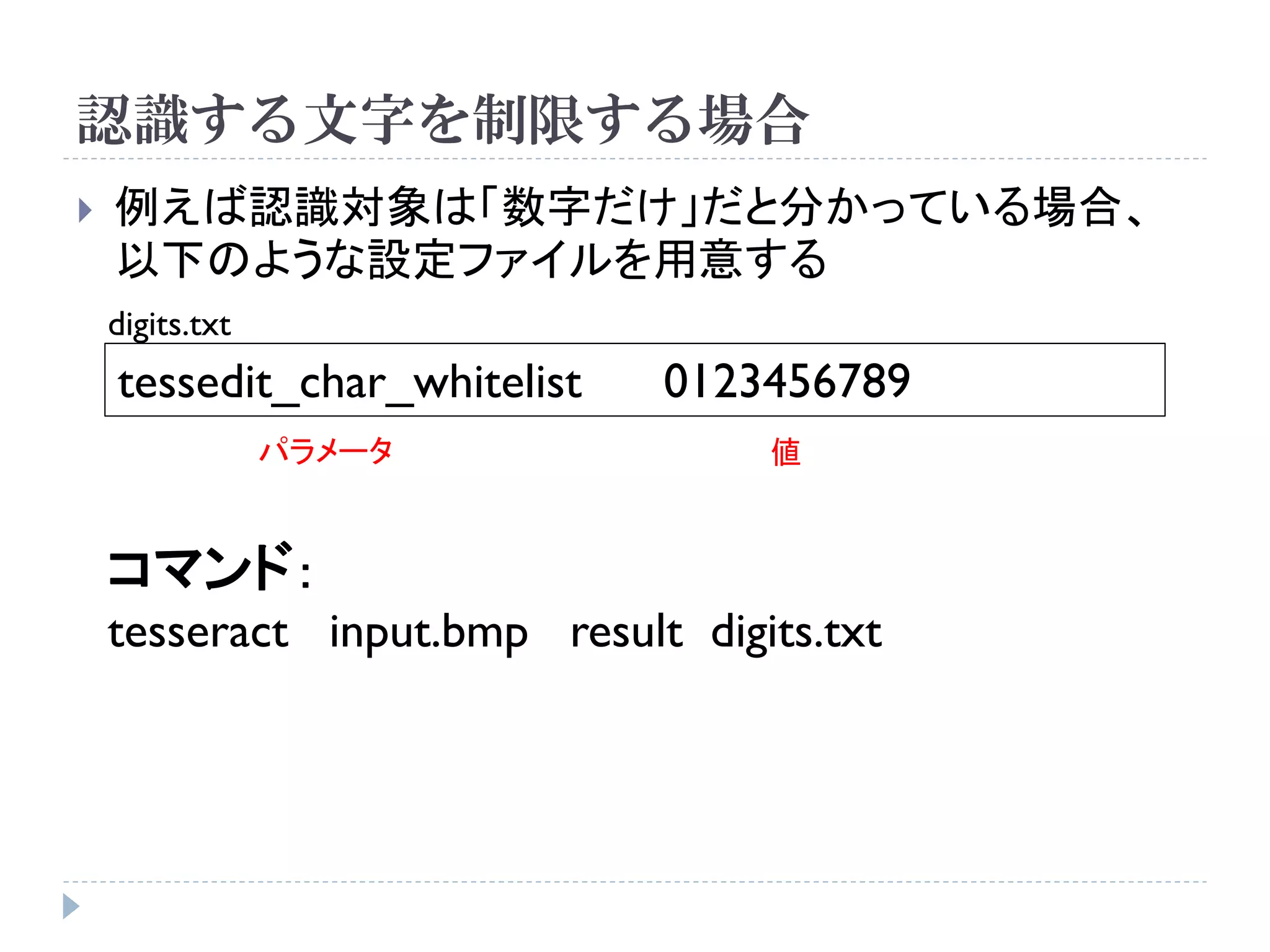
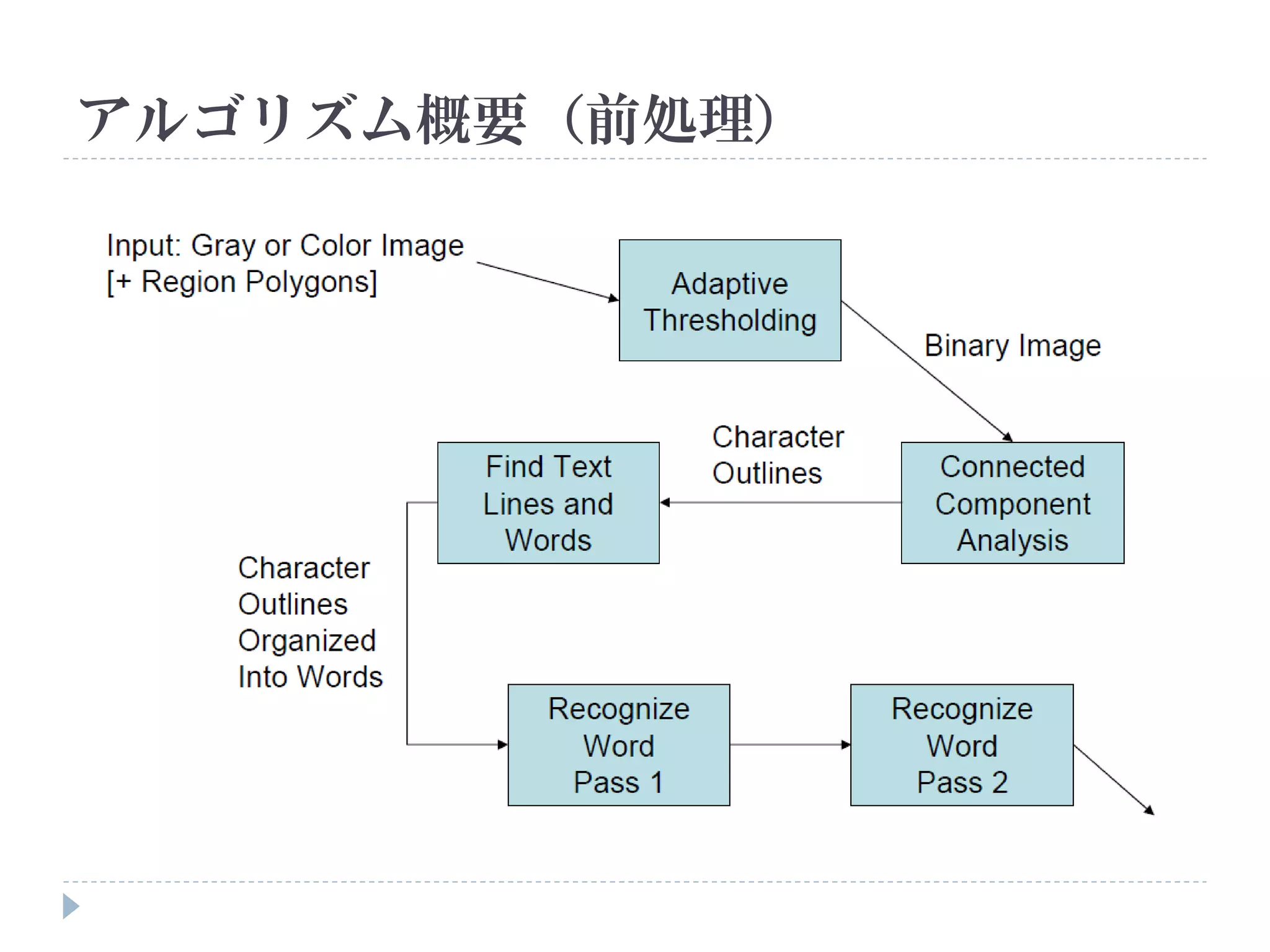
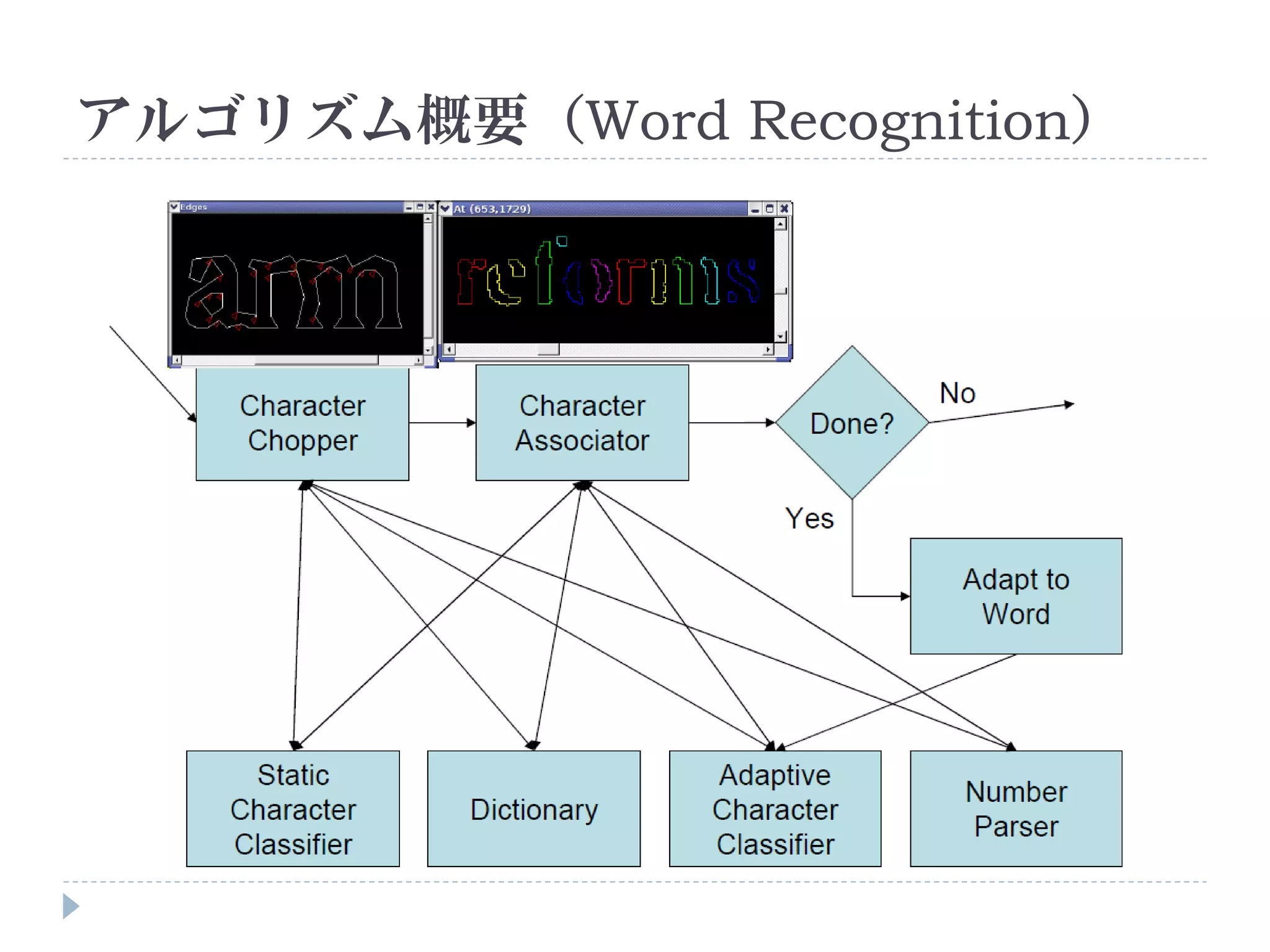
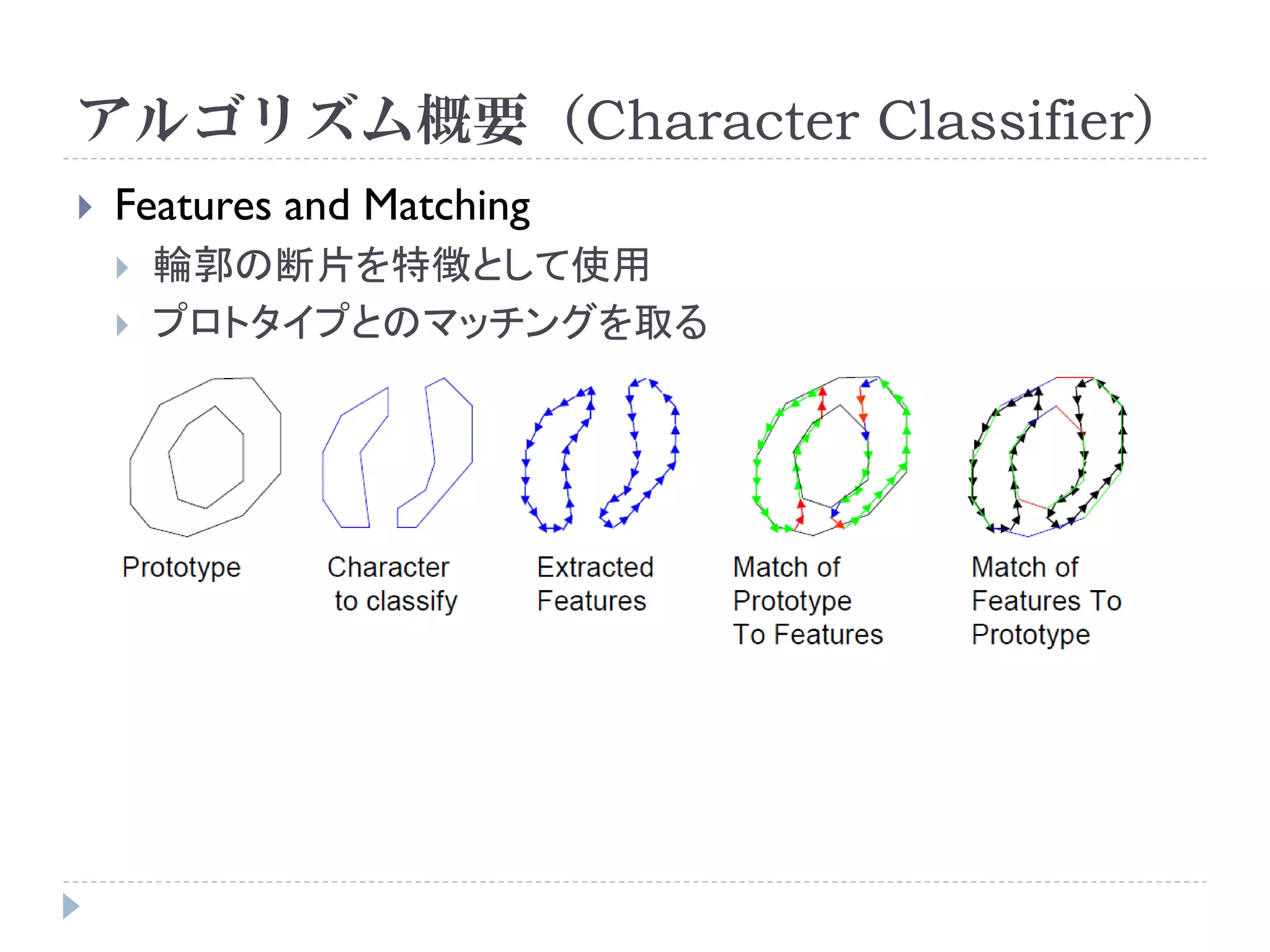
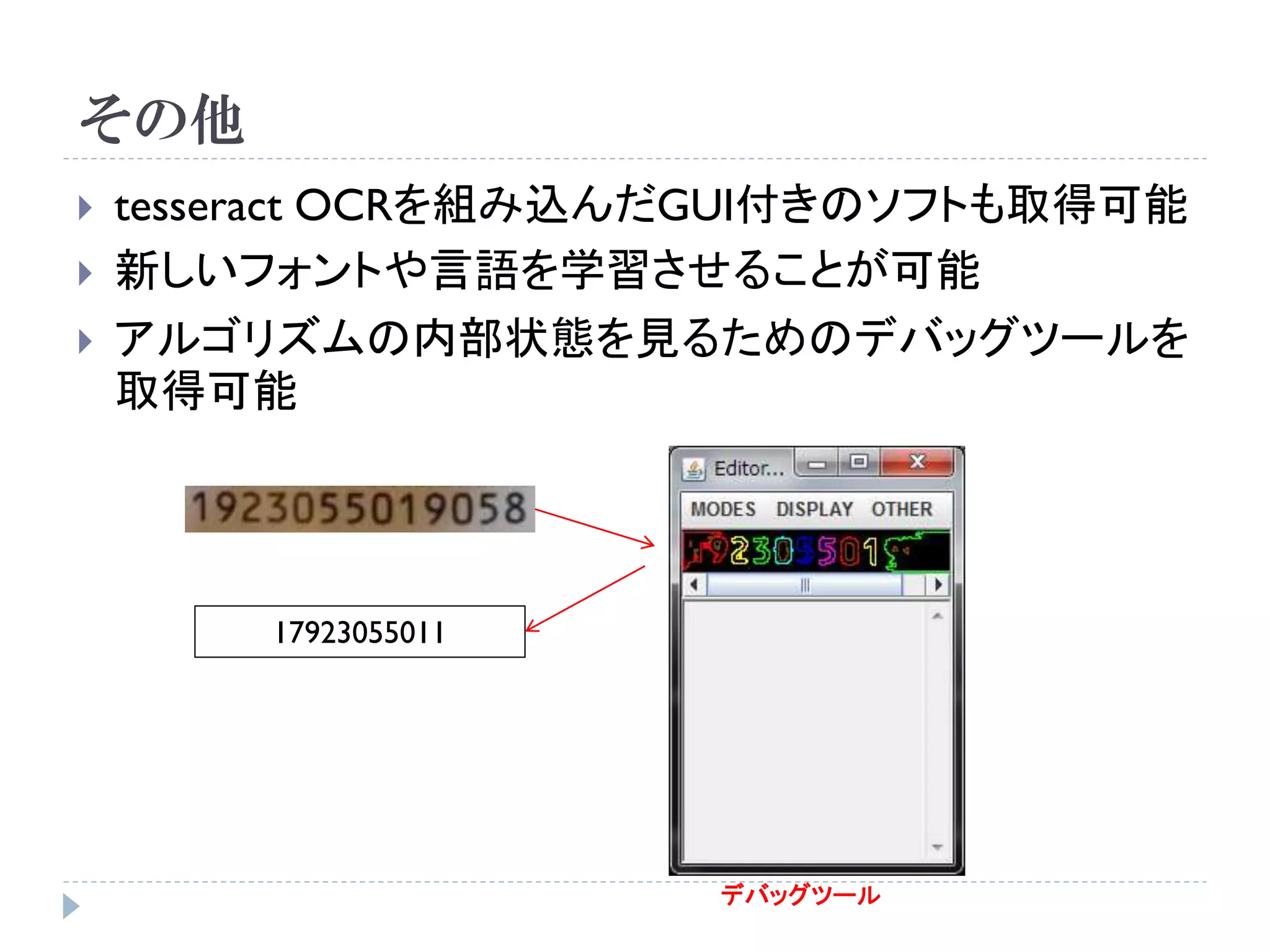
![使い方
コマンドラインで実行
Usage: tesseract imagename outputbase [-l lang] [configfile [[+|-]varfile]...]
入力画像 出力ファイル 言語 設定ファイル
例:
tesseract input.bmp result -l jpn
画像どう しのマッチング 日本語
input.bmp result.txt](https://image.slidesharecdn.com/tesseractocr-110719234541-phpapp02/75/Tesseract-ocr-10-2048.jpg)
![文字認識の結果例(英語)
1 Introduction
There has been a steady increase in the performance of object category detection as measured bythe
annual PASCAL VOC challenges [3]. The training data provided for these challenges specifies if an
object is truncated » when the provided axis aligned bounding box does not cover the full extent of
the object. The principal cause of truncation is that the object partially lies outside Lhe image area.
Most participants simple disregard the truncated training instances and learn from the non-truncated
ones. This is a waste of training material, but more seriously many truncated instances are missed
in testing, signilicantly reducing the recall and hence decreasing overall recognition performance.](https://image.slidesharecdn.com/tesseractocr-110719234541-phpapp02/75/Tesseract-ocr-11-2048.jpg)
















![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)








![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]FOTS: Fast Oriented Text Spotting with a Unified Network](https://cdn.slidesharecdn.com/ss_thumbnails/20181012yokota-181012004624-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)





































