Download to read offline






![実験 (単一画像のインペインティング)
n#8%+)8#"%C#-D%+%-@%と比較
• データセット
• 2<UF'H.)++)$S,'A;(=>?OVI'
• ;)+$'H.+)/$%S,'>?ORI'
• ;%5%7!'H(#/S,'>?OWI
• フレームワーク
• X%*らによって提案された手法
• 評価指標
• 62F=
• YAP'HU%/$%5S,'FA62>?OTI
n$#-35%CB)$$C#-D%+%-@%と比較
• データセット
• ;%5%7!CUZ'H(#/S,'>?OWI'
• A0)3%F%8
• フレームワーク
• 6A;'H[*%-3S,';<6=>?OI
• EA6'HX/S,';<6=>?OVI
• 9;C;FF'H])-3S,'F%/+A62>?OVI
• 評価指標
• YAP'HU%/$%5S,'FA62>?OTI](https://image.slidesharecdn.com/b14lqn8tuguxetigd7ha-20210511-slide-prior-guided-gan-based-semantic-inpainting-cvpr2020-220418132258/95/Prior-Guided-GAN-Based-Semantic-Inpainting-9-638.jpg)

![taset averaged over different mask-to-frame ratios between 10%-50%. Lower FID means
d [10] CombCN [40] Proposed
MH
z MH
z+S MH
z+L MH
z+S+L
0 0.742 0.738 0.710 0.680 0.660
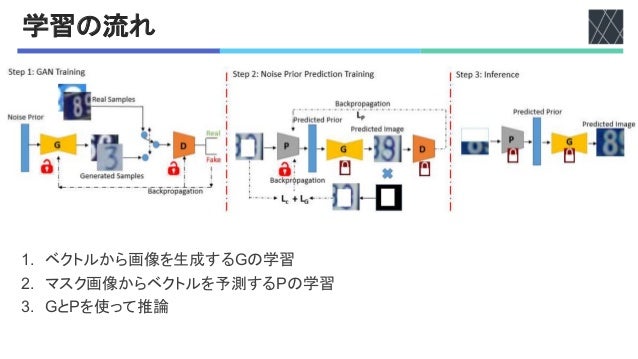
Table 4: Comparison of inpainting inference time (in ms). We dramatically im-
prove the inference of our starting iterative baseline of Yeh et al. [45]. Our run time
is also comparable with contemporary ‘single-pass-inference’ methods of PIC [49],
GIP [47] and MC-CNN [42]. Note, at 256×256 resolution, we are refering to the
‘BigGAN’ generator network.
Res Yeh et al. PIC GIP MC-CNN
Mz
(Ours)
Mz+S
(Ours)
64X64 2175 - - - 2.7 2.8
128X128 10750 - - 11.0 13.2
256X256 Not Converge 70 30 50 68 75
&"#$%"&'#3&()#$#(*#との比較
n#-B)#-8#-3の推論時間
• ^_×^_では約TV?倍スピードアップ
• O>V×O>Vでは約V>?倍スピードアップ
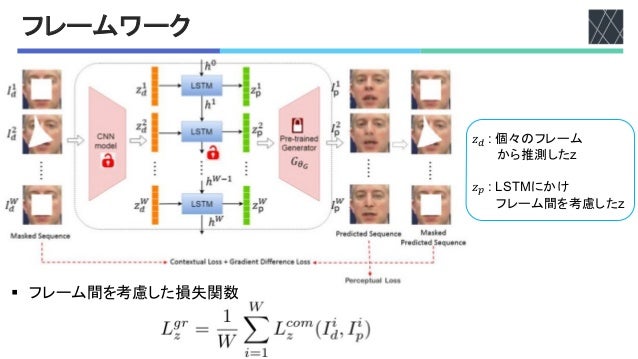
3: Grouped noise prior learning with a combined LSTM-CNN framework.
n means parameters to update.
of W frames at a time. LSTM network has a hid-
e, ht
, to summarize information observed upto that
ep, t. The hidden state is updated after looking at the
s hidden state and the current masked image (with
l structural priors), leading to temporally coherent
ructions.
3 shows our LSTM based framework for jointly re-
1 2 W
Figure 4: (a:) Refinement of initial noisy landmark detection by Bulat et al.
[7] on masked image. Note that our refinement stage rectifies even the landmarks
on unmasked regions; (b) Comparing Relative Localization Error of facial keypoints
detection on LS3D-W test set with 50% skin pixels masked.
Table 1: Comparison with the baseline iterative-inference inpainting baseline of
Yeh et al [45] at different rates of hole-to-image ratio. Lower FID indicates more
visually plausible reconstructions.
Method → Metric SVHN Cars CelebA
10% 40% 10% 40% 10% 40%
Yeh et al. → PSNR 21.3 16.5 15.1 12.2 23.8 20.1
Ours (Mz) → PSNR 21.1 17.0 14.8 12.5 23.4 20.3
Ours (Mz+S ) → PSNR - - - - 24.1 21.7
Yeh et al. et al. → FID 3.9 4.8 4.5 5.4 5.8 6.8
Ours (Mz) → FID 3.6 4.3 4.1 5.0 5.1 6.7
Ours(Mz+S ) → FID - - - - 4.9 6.0
n62F=とYAPの比較
• 62F=
• さほど良い結果が得られなかった
• YAP
• 一貫して低い値を取り優れている
+,-./,+0-1+23-.-24- 5+267-18/551+23-.-24-
単位!"#$](https://image.slidesharecdn.com/b14lqn8tuguxetigd7ha-20210511-slide-prior-guided-gan-based-semantic-inpainting-cvpr2020-220418132258/95/Prior-Guided-GAN-Based-Semantic-Inpainting-11-638.jpg)
![実験 (ビデオのインペインティング)
nデータセット
• Y)@%YL+%-$#@$ H2)0#S,'>?O^I
• ビデオクリップからR>フレームごとにデータサンプルを作成
• 顔を真ん中にしてO>V×O>Vにトリミング H;*)-3S,'A;;<>?OI
• `?QRW5,'?QW5a'の範囲でランダムな四角形のマスクで訓練
nフレームワーク
• ;L07;F'H])-3S,'!!!A>?OI
• RPE)8%K'H;*)-3S,'A;;<>?OI
• (Eb29'H;*)-3S,':9<;>?OI
n評価指標
• "#K%LCYAPH])-3S,'>?OVI
Nisarg Kothari
ndk@google.com
Joonseok Lee
joonseok@google.com
Paul Natsev
natsev@google.com
Balakrishnan Varadarajan
balakrishnanv@google.com
Sudheendra Vijayanarasimhan
svnaras@google.com
Google Research
uter Vision are attributed to
ackages for Machine Learn-
ware have reduced the bar-
aches at scale. It is possible
ples within a few days. Al-
mage understanding, such as
e video classification datasets. (Sami+, 2016)](https://image.slidesharecdn.com/b14lqn8tuguxetigd7ha-20210511-slide-prior-guided-gan-based-semantic-inpainting-cvpr2020-220418132258/95/Prior-Guided-GAN-Based-Semantic-Inpainting-13-638.jpg)
![結果 (ビデオのインペインティング)
n結果
• 提案手法の複合モデルは空間次元を使うモデルと同程度の性能
• 提案手法の単一画像モデルの𝛭𝓏
ℋでさえ競合する単一モデルより優れた性能
• 構造事前分布を組み込んだ𝛭𝓏'(
ℋ
,'(2b9を組み込んだ𝛭𝓏')
ℋ
は性能向上
• 𝛭𝓏'(')
ℋ
は提案手法の中で最も良い性能
• 𝛭𝓏'(')
ℋ
は(E929とRPE)8%Kと同程度の性能
ble 3: Video FID metric by different inpainting methods on FaceForensics video dataset averaged over different mask-to-frame ratios between 10%-50%. Lower FID m
r perceptual video quality.
Yeh et al. [45] GLCIC [21] GIP [47] LGTSM [9] 3DGated [10] CombCN [40] Proposed
MH
z MH
z+S MH
z+L MH
z+S+L
0.781 0.762 0.751 0.651 0.670 0.742 0.738 0.710 0.680 0.660
マスク領域がフレームの.-から1-<のデータに対しての=7>#?@:3;の値](https://image.slidesharecdn.com/b14lqn8tuguxetigd7ha-20210511-slide-prior-guided-gan-based-semantic-inpainting-cvpr2020-220418132258/95/Prior-Guided-GAN-Based-Semantic-Inpainting-14-638.jpg)


Avisek Lahiri, Arnav Kumar Jain, Sanskar Agrawal, Pabitra Mitra, Prabir Kumar Biswas; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 13696-13705 https://openaccess.thecvf.com/content_CVPR_2020/html/Lahiri_Prior_Guided_GAN_Based_Semantic_Inpainting_CVPR_2020_paper.html

![[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning](https://cdn.slidesharecdn.com/ss_thumbnails/slidev2reduced-190422065109-thumbnail.jpg?width=640&height=640&fit=bounds)









![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20220121gudalin-220121050547-thumbnail.jpg?width=640&height=640&fit=bounds)


























