Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
marika_hotani
PPTX, PDF
2,816 views
プログラミング初心者がOpenCVと機械学習でOCRエンジン自作に挑戦する話
プログラミング歴8ヶ月の初心者が OCRエンジンのプロトタイプを自作してみたのでまとめました。 @Kansai AI PUB 7/29 目次 1. OCRってなに? 2.作ってみた 3. 最後に
Software
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 27
2
/ 27
3
/ 27
Most read
4
/ 27
Most read
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
Most read
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PDF
Tesseract ocr
by
Takuya Minagawa
PDF
Surveyから始まる研究者への道 - Stand on the shoulders of giants -
by
諒介 荒木
PDF
Data-Centric AI開発における データ生成の取り組み
by
Takeshi Suzuki
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PDF
研究分野をサーベイする
by
Takayuki Itoh
PDF
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
PPTX
論文に関する基礎知識2015
by
Mai Otsuki
PDF
研究の基本ツール
by
由来 藤原
Tesseract ocr
by
Takuya Minagawa
Surveyから始まる研究者への道 - Stand on the shoulders of giants -
by
諒介 荒木
Data-Centric AI開発における データ生成の取り組み
by
Takeshi Suzuki
研究効率化Tips Ver.2
by
cvpaper. challenge
研究分野をサーベイする
by
Takayuki Itoh
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
論文に関する基礎知識2015
by
Mai Otsuki
研究の基本ツール
by
由来 藤原
What's hot
PDF
BERT入門
by
Ken'ichi Matsui
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PDF
Akkaとは。アクターモデル とは。
by
Kenjiro Kubota
PDF
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PDF
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
PDF
Cartographer を用いた 3D SLAM
by
Yoshitaka HARA
PPTX
BERT分類ワークショップ.pptx
by
Kouta Nakayama
PDF
Anomaly detection 系の論文を一言でまとめた
by
ぱんいち すみもと
PPTX
OCRは古い技術
by
Koji Kobayashi
PDF
AHC-Lab M1勉強会 論文の読み方・書き方
by
Shinagawa Seitaro
PDF
エンジニアも知っておきたいAI倫理のはなし
by
Yasunori Nihei
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
PDF
PCL
by
Masafumi Noda
PDF
TLS, HTTP/2演習
by
shigeki_ohtsu
PPTX
優れた研究論文の書き方―7つの提案
by
Masanori Kado
PPTX
位置データもPythonで!!!
by
hide ogawa
PDF
Objectnessとその周辺技術
by
Takao Yamanaka
PDF
はじめようARCore:自己位置推定・平面検出・FaceTracking
by
Takashi Yoshinaga
PDF
[DL Hacks]Visdomを使ったデータ可視化
by
Deep Learning JP
BERT入門
by
Ken'ichi Matsui
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
Akkaとは。アクターモデル とは。
by
Kenjiro Kubota
ブレインパッドにおける機械学習プロジェクトの進め方
by
BrainPad Inc.
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
Cartographer を用いた 3D SLAM
by
Yoshitaka HARA
BERT分類ワークショップ.pptx
by
Kouta Nakayama
Anomaly detection 系の論文を一言でまとめた
by
ぱんいち すみもと
OCRは古い技術
by
Koji Kobayashi
AHC-Lab M1勉強会 論文の読み方・書き方
by
Shinagawa Seitaro
エンジニアも知っておきたいAI倫理のはなし
by
Yasunori Nihei
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
by
SSII
PCL
by
Masafumi Noda
TLS, HTTP/2演習
by
shigeki_ohtsu
優れた研究論文の書き方―7つの提案
by
Masanori Kado
位置データもPythonで!!!
by
hide ogawa
Objectnessとその周辺技術
by
Takao Yamanaka
はじめようARCore:自己位置推定・平面検出・FaceTracking
by
Takashi Yoshinaga
[DL Hacks]Visdomを使ったデータ可視化
by
Deep Learning JP
Similar to プログラミング初心者がOpenCVと機械学習でOCRエンジン自作に挑戦する話
PDF
StudyCo_DocumentAI による OCR と LLM で紙文書をデータ化する(試み)
by
Taku Yoshida
PDF
オープンソースで作るスマホ文字認識アプリ
by
陽平 山口
PDF
【関東GPGPU勉強会#2】OpenCVのOpenCL実装oclMat
by
Yasuhiro Yoshimura
PDF
Media Art II 2013 第6回:openFrameworks Addonを使う 2 - ofxOpenCV と ofxCv
by
Atsushi Tadokoro
PDF
vs Google Vision API
by
隊長 アイパー
PDF
『Pythonによる ai・機械学習・深層学習アプリのつくり方』をGoogleColabで動く限り動かしてみた
by
Takehiro Eguchi
PDF
OpenCVの入り口
by
cct-inc
PPTX
OCRサービス「Tegaki」とDataSpiderで手書きデータ入力自動化の話し
by
Mika Kamei
PDF
Cloud Vsion APIによるGUIの検証自動化
by
Terui Masashi
PDF
ロボット用Open Source Software
by
たけおか しょうぞう
PDF
20170624 発表資料-ml
by
Ozawa Kensuke
PPTX
Lecuture on Deep Learning API
by
Naoki Watanabe
PDF
20190920 hannaripython20
by
Otazo Man
StudyCo_DocumentAI による OCR と LLM で紙文書をデータ化する(試み)
by
Taku Yoshida
オープンソースで作るスマホ文字認識アプリ
by
陽平 山口
【関東GPGPU勉強会#2】OpenCVのOpenCL実装oclMat
by
Yasuhiro Yoshimura
Media Art II 2013 第6回:openFrameworks Addonを使う 2 - ofxOpenCV と ofxCv
by
Atsushi Tadokoro
vs Google Vision API
by
隊長 アイパー
『Pythonによる ai・機械学習・深層学習アプリのつくり方』をGoogleColabで動く限り動かしてみた
by
Takehiro Eguchi
OpenCVの入り口
by
cct-inc
OCRサービス「Tegaki」とDataSpiderで手書きデータ入力自動化の話し
by
Mika Kamei
Cloud Vsion APIによるGUIの検証自動化
by
Terui Masashi
ロボット用Open Source Software
by
たけおか しょうぞう
20170624 発表資料-ml
by
Ozawa Kensuke
Lecuture on Deep Learning API
by
Naoki Watanabe
20190920 hannaripython20
by
Otazo Man
プログラミング初心者がOpenCVと機械学習でOCRエンジン自作に挑戦する話
1.
プログラミング初心者が OpenCVと機械学習で OCRエンジン自作に挑戦する話 marika.h 2019 年 7
月 29 日 @KANSAI AI PUB
2.
自己紹介 marika (@tama_Ud) バリスタからwebエンジニアに(2019.7~) プログラミング歴 8ヶ月くらい
3.
よろしくお願いします!
4.
目次 1.OCRってなに? 2.作ってみた 3.まとめ
5.
1.OCRってなに?
6.
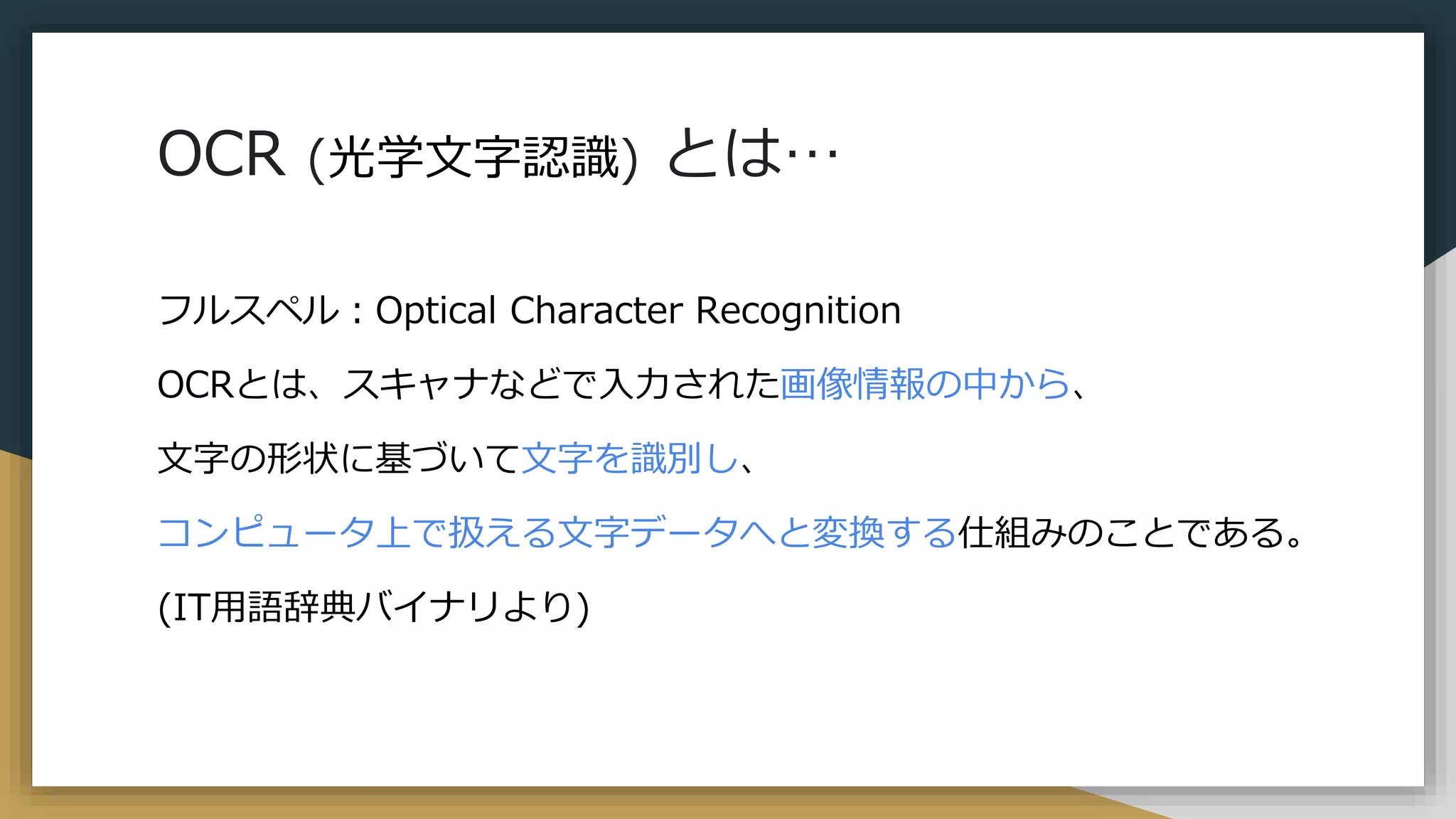
OCR (光学文字認識) とは… フルスペル:Optical
Character Recognition OCRとは、スキャナなどで入力された画像情報の中から、 文字の形状に基づいて文字を識別し、 コンピュータ上で扱える文字データへと変換する仕組みのことである。 (IT用語辞典バイナリより)
7.
たとえば…(ざっくりとしたOCR処理の例) 1234567 890 写真を撮る or スキャンする 文字を認識する 読み取った文字を PC画面に表示する
8.
OSS 業務用 webアプリ すでに多くのOCRソフトがありますが… 用途や対応言語もさまざま 180の言語に対応できるものもある
9.
今回はOpenCVを使って 自作してみました
10.
2. 作ってみた
11.
認識可能な言語:英数字+記号のみ。 目標:機械学習の基礎の理解と、 システムの完成を目標とする。 精度は求めない。 (現時点の知識では満足のいく 精度を出せませんでした…。)
12.
1. 画像取り込み 2. グレースケール変換 3.
レイアウト解析 4. 正規化 5. 特徴抽出 6. 行ごとに取り出す 7. 一文字ずつ取り出す 8. 文字認識 9. 知識処理 etc... 一般的なOCR処理の流れ 1. 画像取り込み 2. 画像のゆがみ補正 3. 二値化 4. 単語ごとに取り出す 5. 一文字ずつ取り出す 6. 正規化 7. 文字認識 今回作るOCR処理の流れ ↑ちょっと簡略化してます
13.
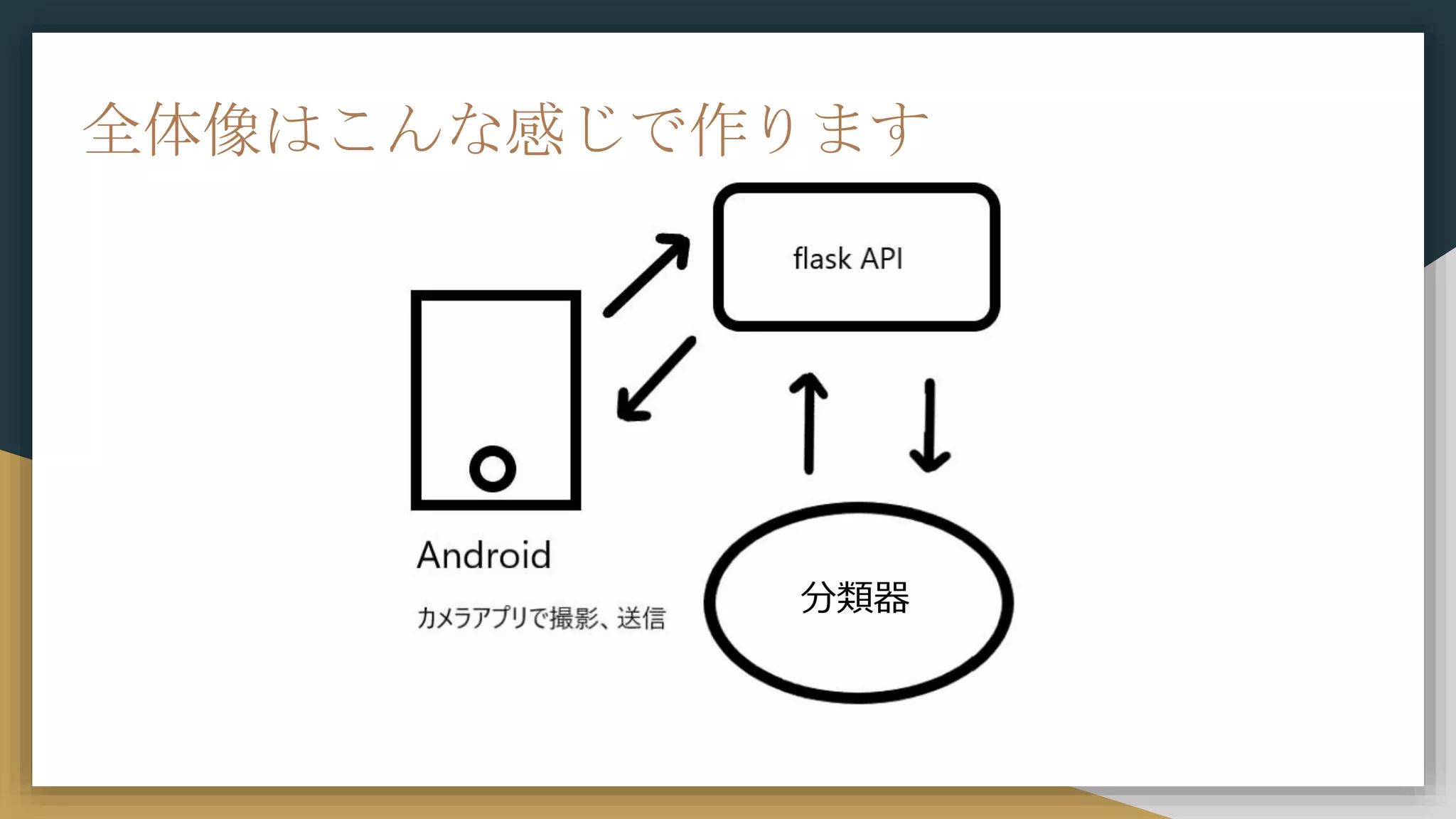
分類器 全体像はこんな感じで作ります
14.
1.画像取り込み・二値化処理 OpenCVのAdaptive threshold()関数で二値化 問題点:光や影の加減でうまく二値化できない時がある。 環境に左右されないようにチューニングするのは難しい…
15.
2. ゆがみ補正 大きなゆがみを検知して、補正します。
16.
1. def _img_rotate(im): 2.
avg_gradient = 0 3. #特徴点のx,y座標を取り出す 4. for i in range(len(list_keypoints_x)): 5. kp_x = np.array(keypoints_x[i]) 6. kp_y = np.array(keypoints_y[i]) 7. #最小二乗法で直線の傾きを取得する 8. #a=傾き,b=切片 9. #傾きの絶対値の最大値を取得 10. ones = np.array([kp_x, np.ones(len(kp_x))]) 11. ones = ones.T 12. a,b = np.linalg.lstsq(ones,kp_y)[0] 13. gradients.append(a) 14. max_gradient =gradients[np.argmax(np.abs(gradients))] 15. #画像回転 16. rows,cols = thresh.shape 17. d = math.degrees(avg_gradient) 18. M = cv2.getRotationMatrix2D((cols/2,rows/2),d,1) 19. thresh = cv2.warpAffine(thresh,M,(cols,rows)) AKAZEで特徴量を検出 →クラスタリング →最小二乗法で文字列の傾 きを求める →画像を回転させる
17.
3. 単語ごとに取り出す 関数を自作してみたけど 精度が思うように上がらなかったので、 素直にライブラリに頼ります。 OpenCV contribからEASTを使って 単語ごとに認識させます。完璧ですね。
18.
4. 一文字ずつ取り出して正規化 OpenCVのfindcontours()関数で一文字ずつ切り出します
19.
5. 文字認識 1. #英字の認識モデル 2.
from keras.models import Sequential 3. def build_model(): 4. model = Sequential() 5. model.add(Conv2D(32, kernel_size=(3, 3), 6. activation='relu', 7. input_shape=(28,28,1))) 8. model.add(MaxPooling2D(pool_size=(2, 2))) 9. model.add(Flatten()) 10. model.add(Dense(784, activation='relu')) 11. model.add(Dense(52, activation='softmax')) a. 分類器はkerasで CNNを構築します
20.
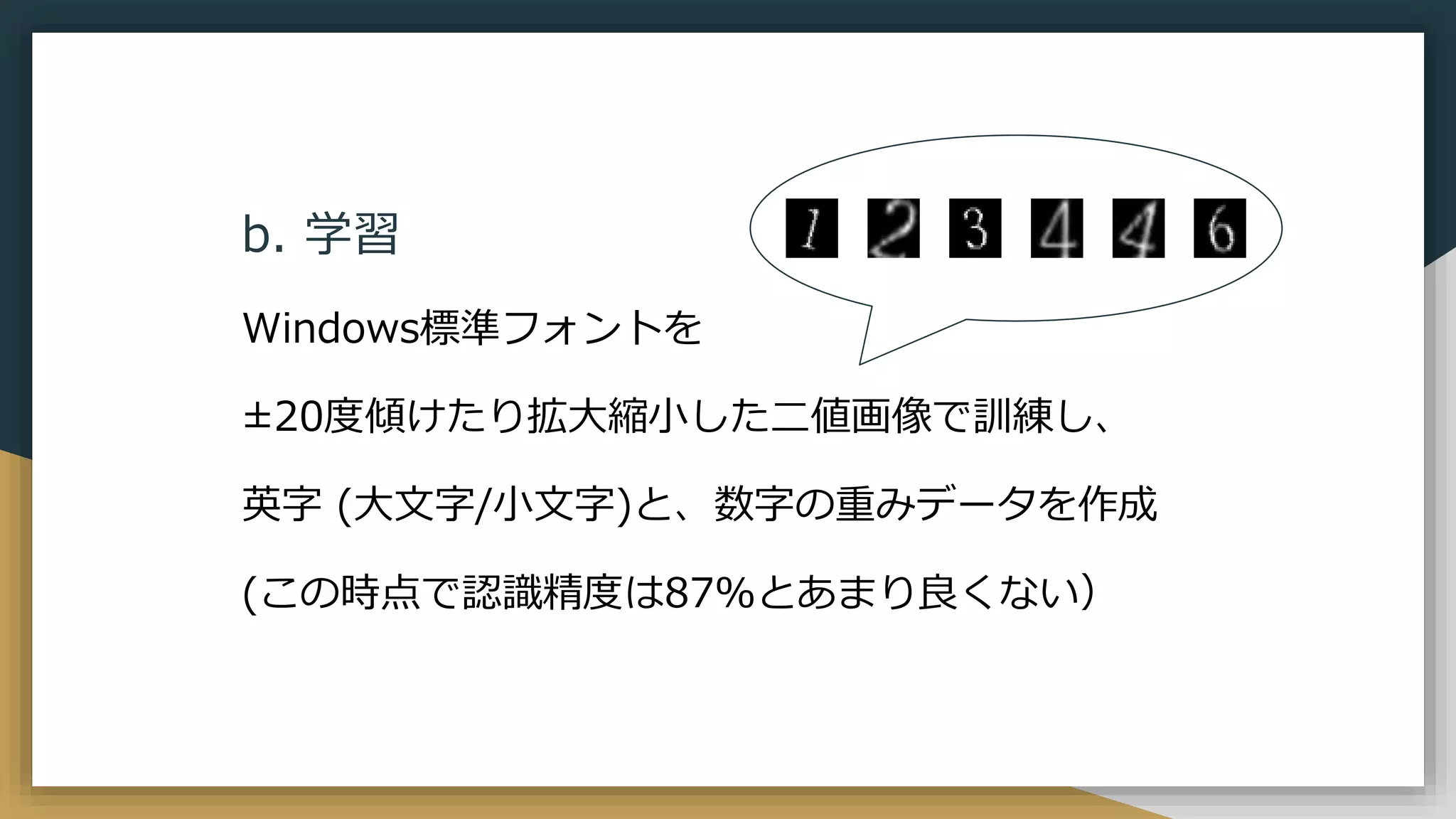
b. 学習 Windows標準フォントを ±20度傾けたり拡大縮小した二値画像で訓練し、 英字 (大文字/小文字)と、数字の重みデータを作成 (この時点で認識精度は87%とあまり良くない)
21.
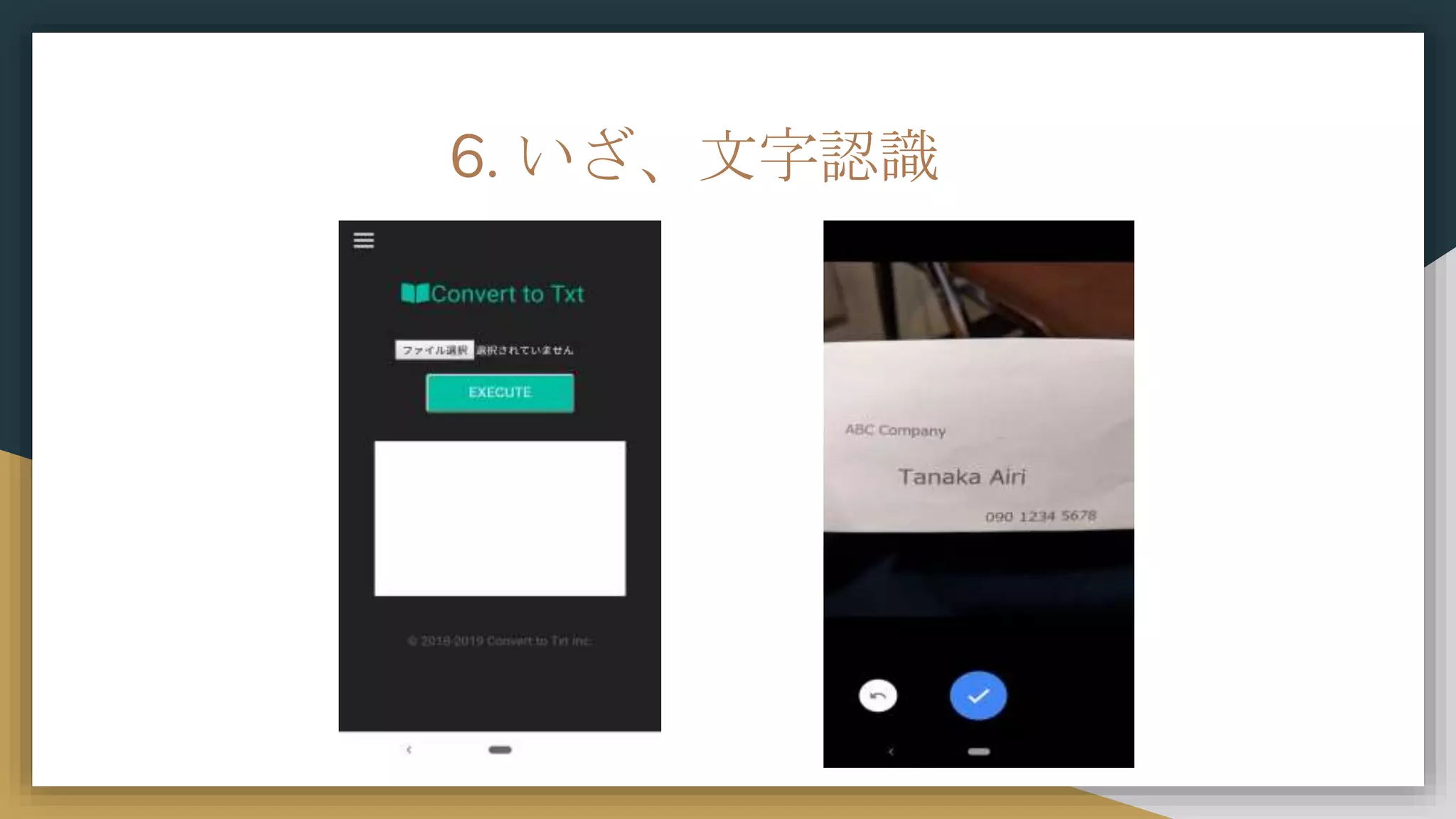
6. いざ、文字認識
22.
精度は良くない…が OCRっぽいシステムは出来た!
23.
3. まとめ
24.
・製作期間3ヶ月くらい(python・機械学習も学びながら) ・ライブラリの力を借りれば初心者でもそれっぽいものは作れる ・ブラックボックス化しないようにライブラリのロジックを学ぶ必要あり ・精度を上げるのが難しい(特に情景文字認識の場合) ・実用化するにはさらにチューニングが必要
25.
・OCRエンジンのおおまかな仕組みがわかって良かった ・もっとこうしたほうがいいよ!的なご意見ご指導お待ちしてます!
26.
引用 画像等: Wikipedia/ Tesseract https://ja.wikipedia.org/wiki/Tesseract_(%E3%82% BD%E3%83%95%E3%83%88%E3%82%A6%E3%8 2%A7%E3%82%A2) Online OCR https://www.onlineocr.net/ DocuWorks https://www.fujixerox.co.jp/product/soft ware/docuworks 参考 NTTデータ/ OCR
技術解説 文字の読み取り・認識について https://mediadrive.jp/technology/techocr05.html A gentle introduction to OCR https://towardsdatascience.com/a-gentle- introduction-to-ocr-ee1469a201aa EAST https://arxiv.org/abs/1704.03155v2
27.
ご清聴ありがとうございました!
Download











![1. def _img_rotate(im):
2. avg_gradient = 0
3. #特徴点のx,y座標を取り出す
4. for i in range(len(list_keypoints_x)):
5. kp_x = np.array(keypoints_x[i])
6. kp_y = np.array(keypoints_y[i])
7. #最小二乗法で直線の傾きを取得する
8. #a=傾き,b=切片
9. #傾きの絶対値の最大値を取得
10. ones = np.array([kp_x, np.ones(len(kp_x))])
11. ones = ones.T
12. a,b = np.linalg.lstsq(ones,kp_y)[0]
13. gradients.append(a)
14. max_gradient =gradients[np.argmax(np.abs(gradients))]
15. #画像回転
16. rows,cols = thresh.shape
17. d = math.degrees(avg_gradient)
18. M = cv2.getRotationMatrix2D((cols/2,rows/2),d,1)
19. thresh = cv2.warpAffine(thresh,M,(cols,rows))
AKAZEで特徴量を検出
→クラスタリング
→最小二乗法で文字列の傾
きを求める
→画像を回転させる](https://image.slidesharecdn.com/first-step-for-ocr-190729231702/75/OpenCV-OCR-16-2048.jpg)


































![[DL Hacks]Visdomを使ったデータ可視化](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20181115-181116004623-thumbnail.jpg?width=640&height=640&fit=bounds)












