Download as PPSX, PPTX






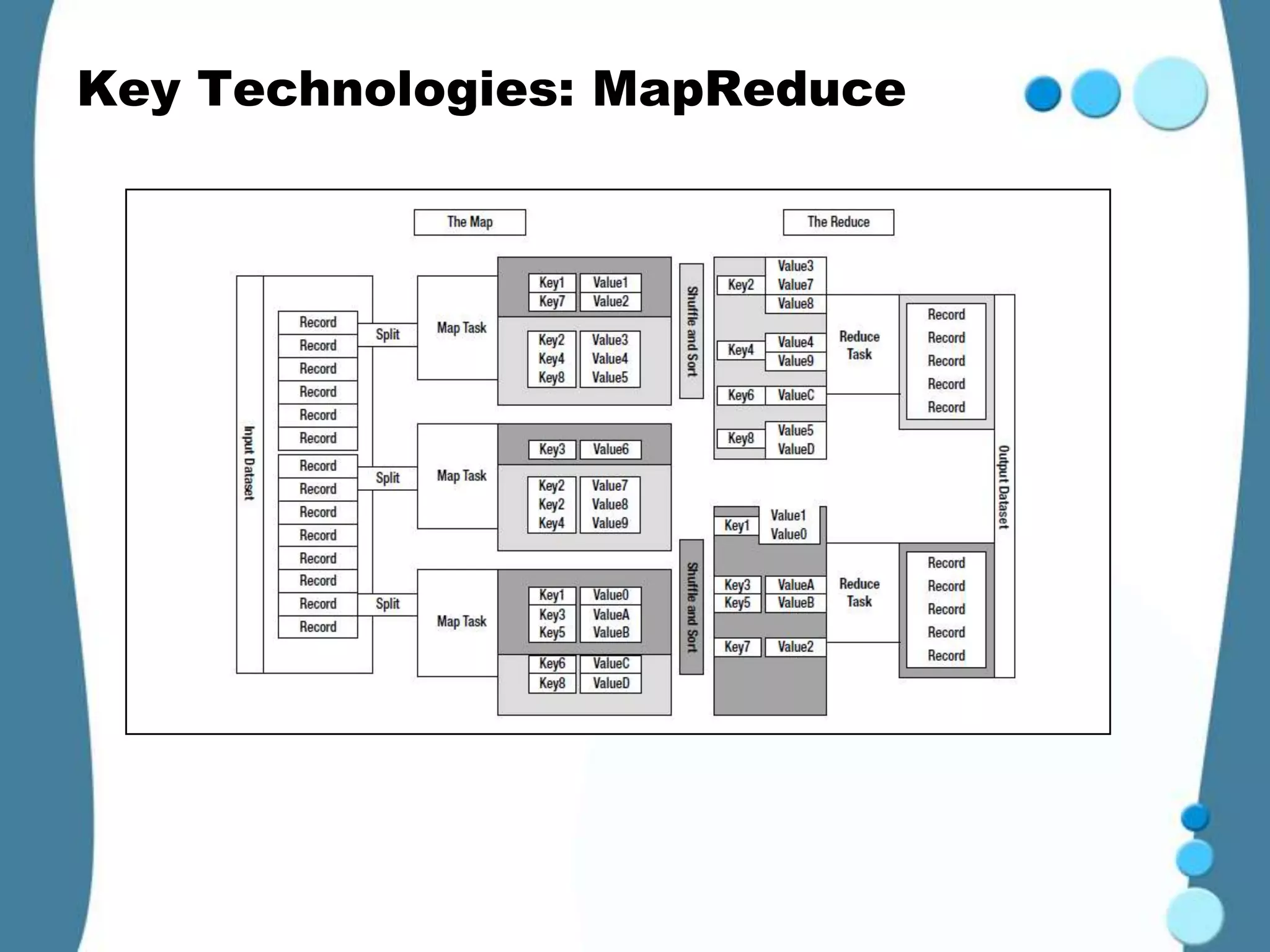

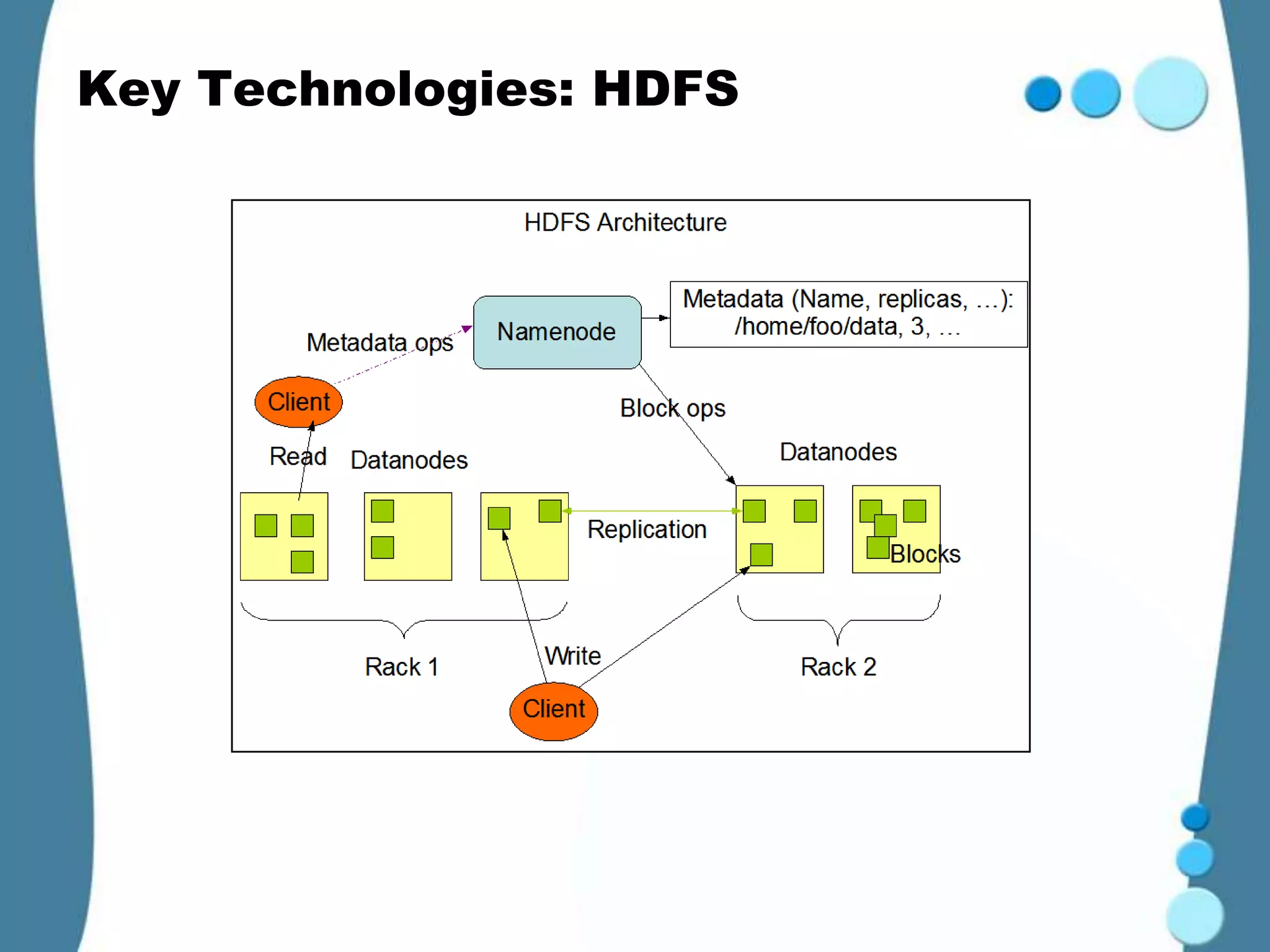

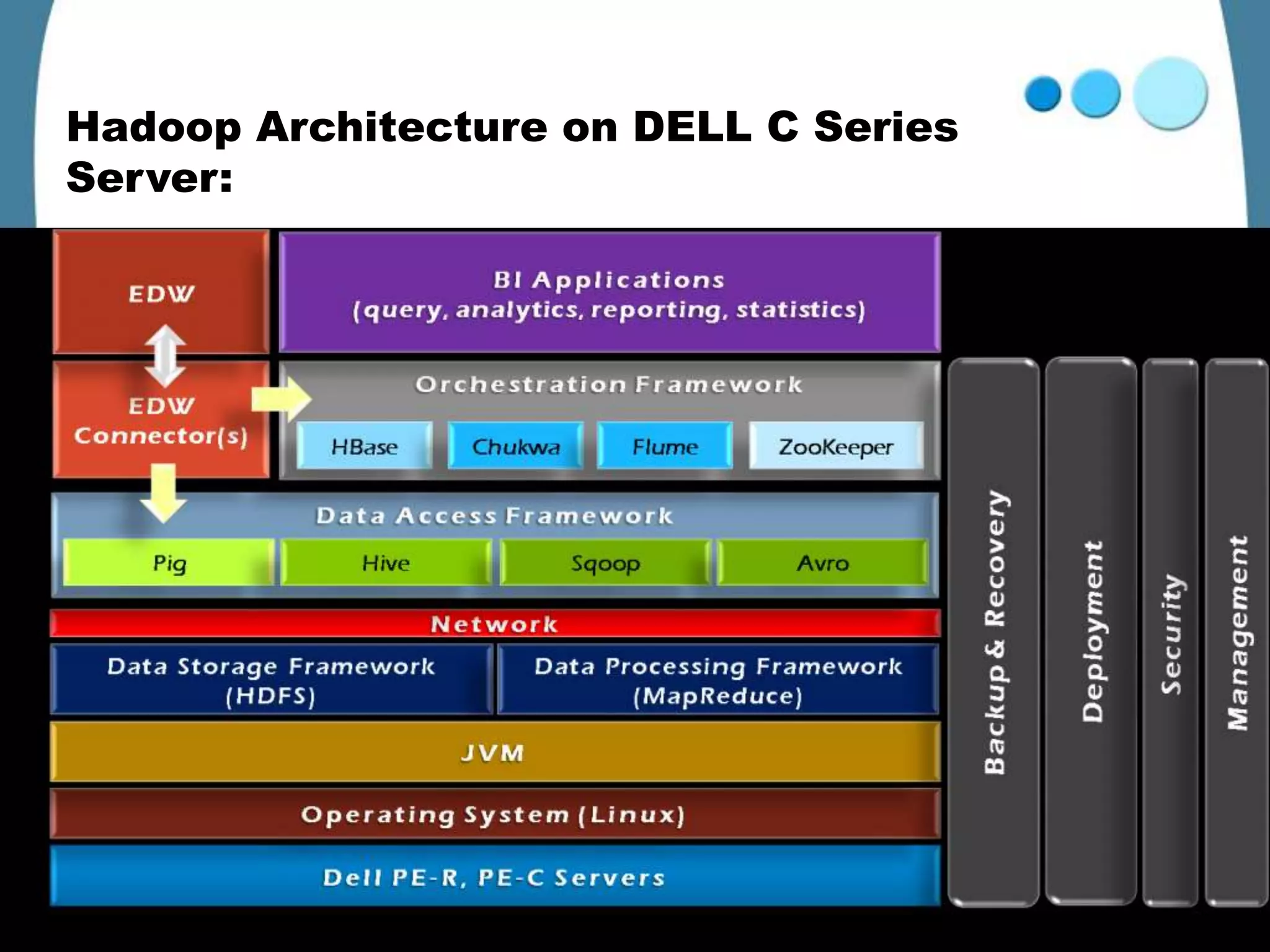



Hadoop is an open-source framework for distributed storage and processing of large datasets across clusters of commodity hardware. It was created to support applications handling large datasets operating on many servers. Key Hadoop technologies include MapReduce for distributed computing, and HDFS for distributed file storage inspired by Google File System. Other related Apache projects extend Hadoop capabilities, like Pig for data flows, Hive for data warehousing, and HBase for NoSQL-like big data. Hadoop provides an effective solution for companies dealing with petabytes of data through distributed and parallel processing.










































































