Download to read offline








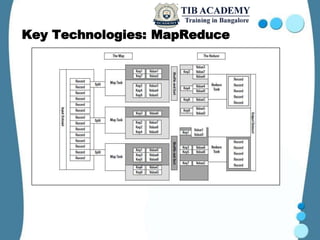


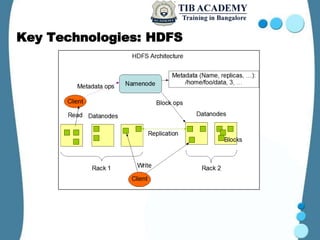



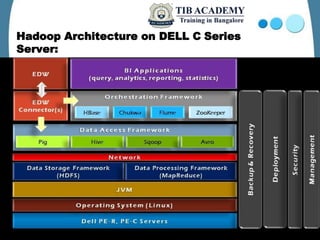



Hadoop is an open-source framework designed for processing large data sets across distributed computing environments, primarily utilizing its key technologies, MapReduce and the Hadoop Distributed File System (HDFS). Originating from the work of Doug Cutting, Hadoop has evolved since its inception in 2002 and is widely adopted by various companies for its efficiency in managing vast amounts of data. It supports several projects like Zookeeper, Pig, and Hive, enhancing its capabilities for data management and querying.



















































































