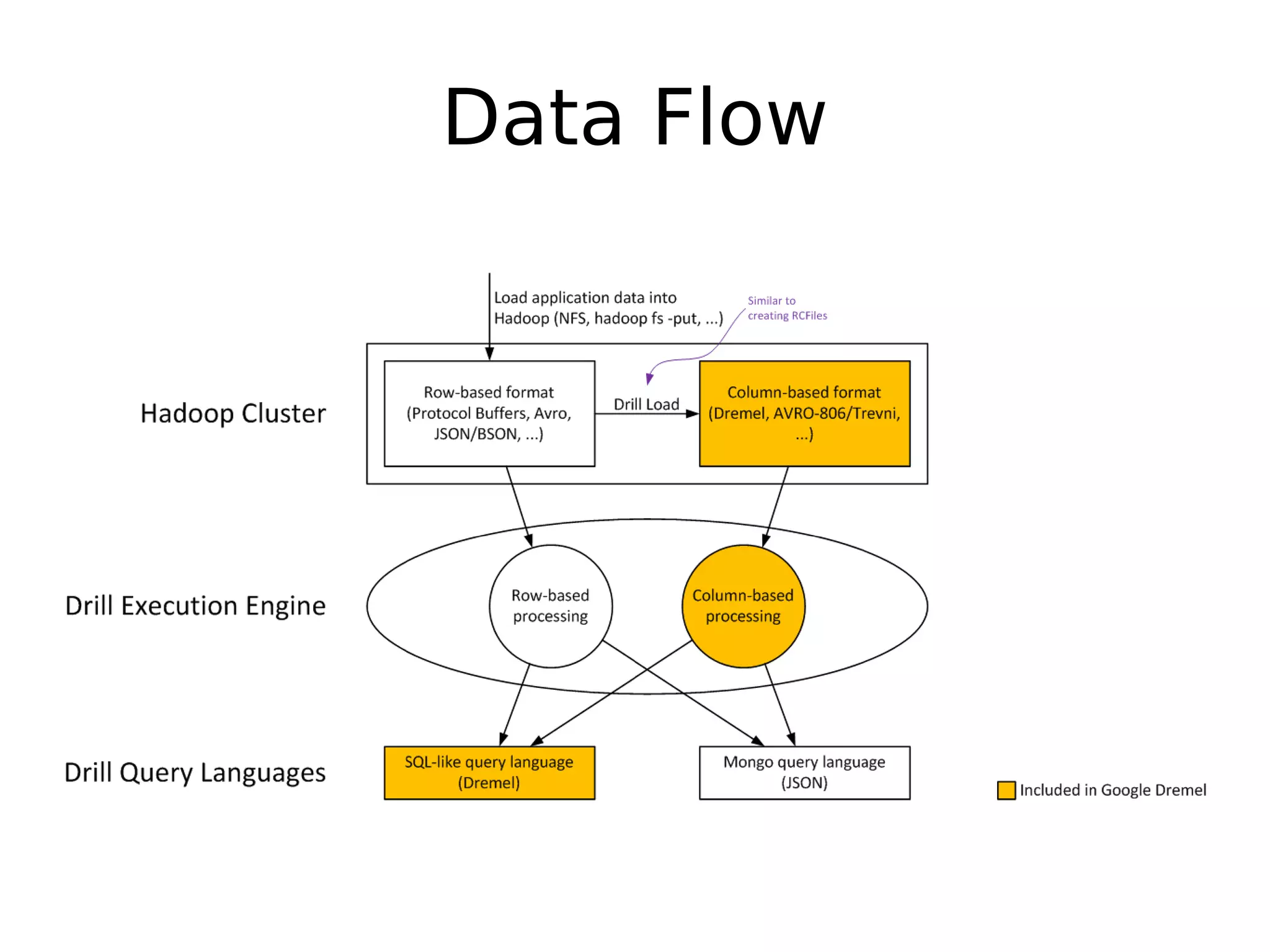
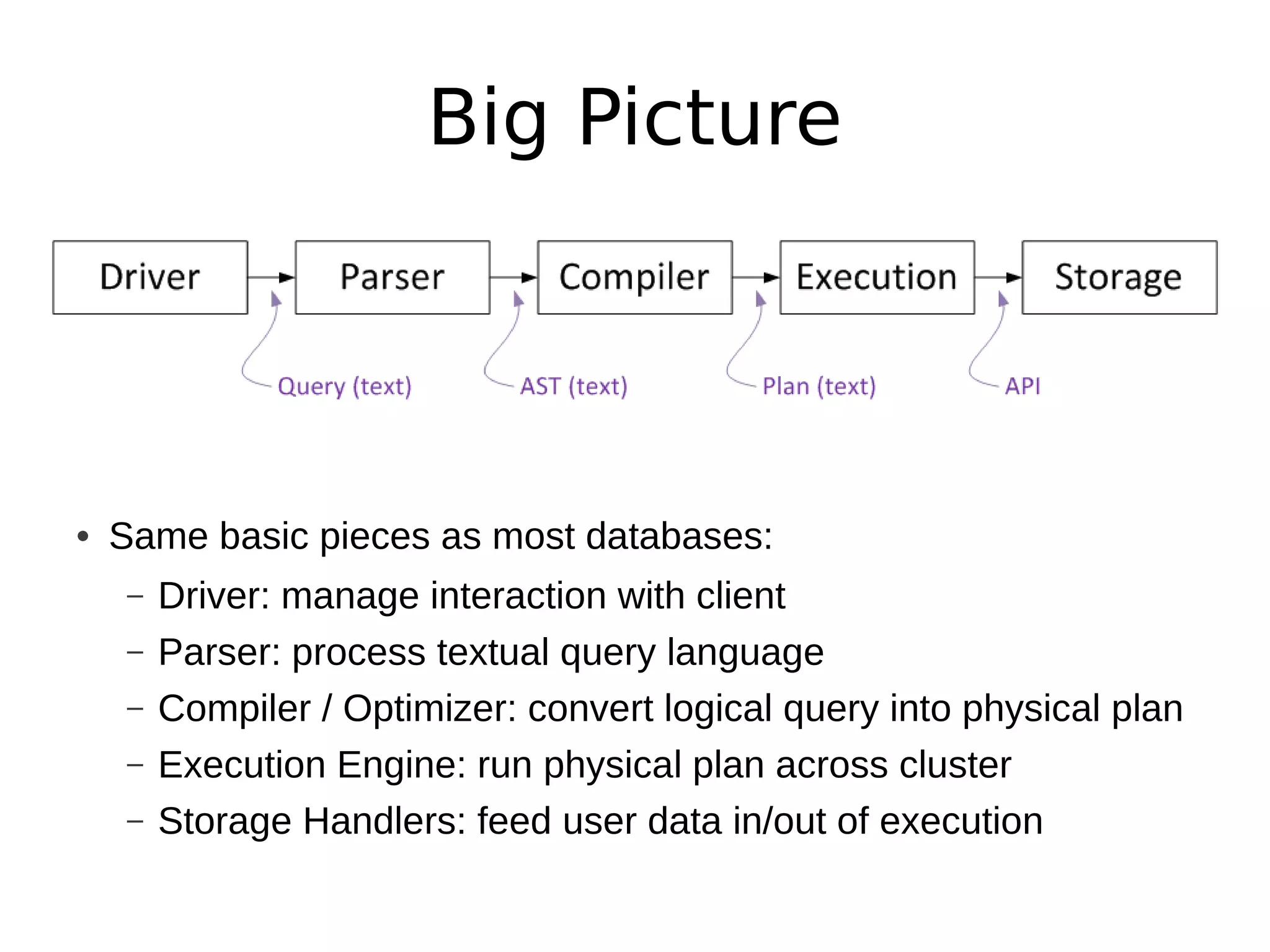
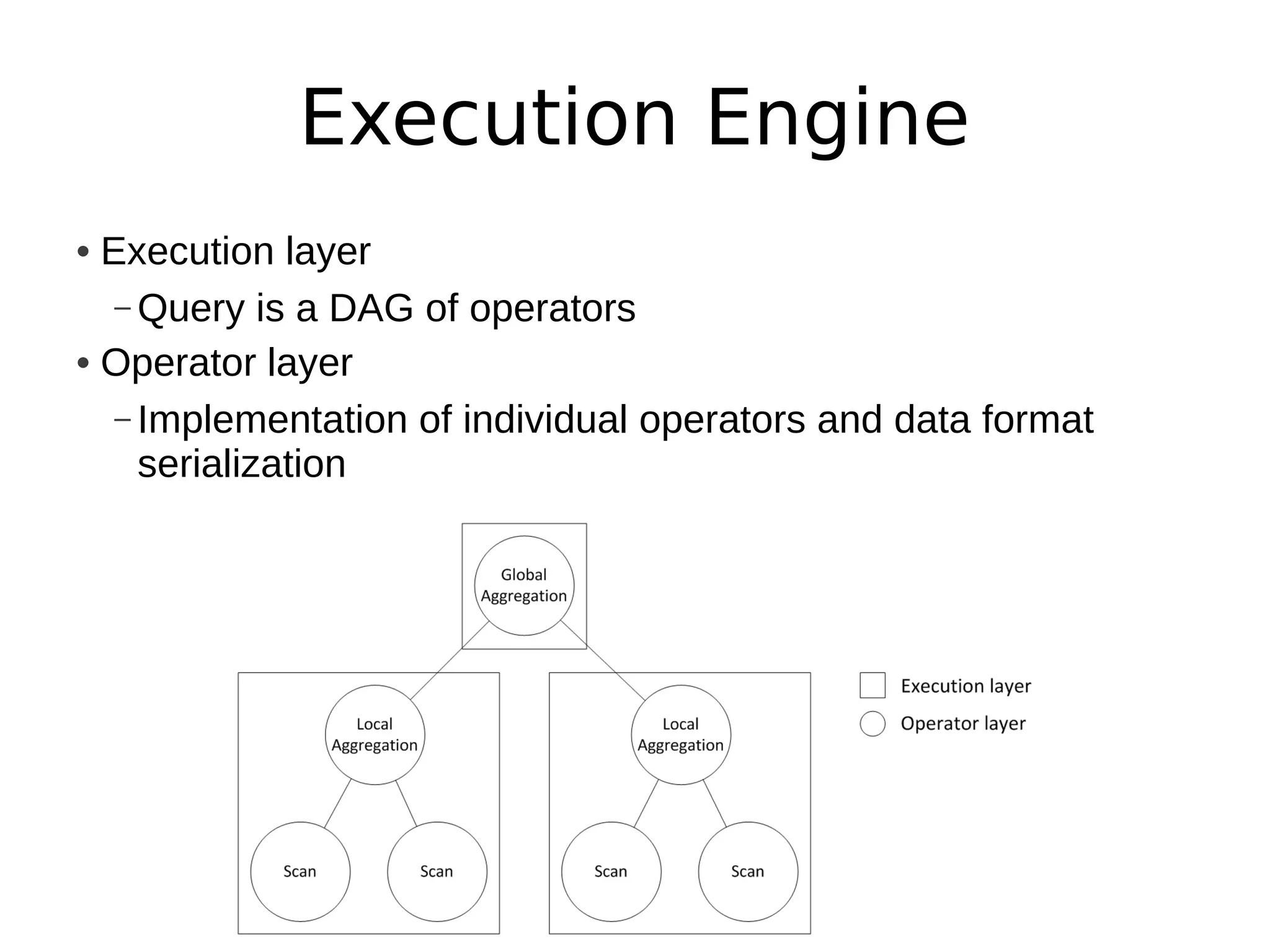
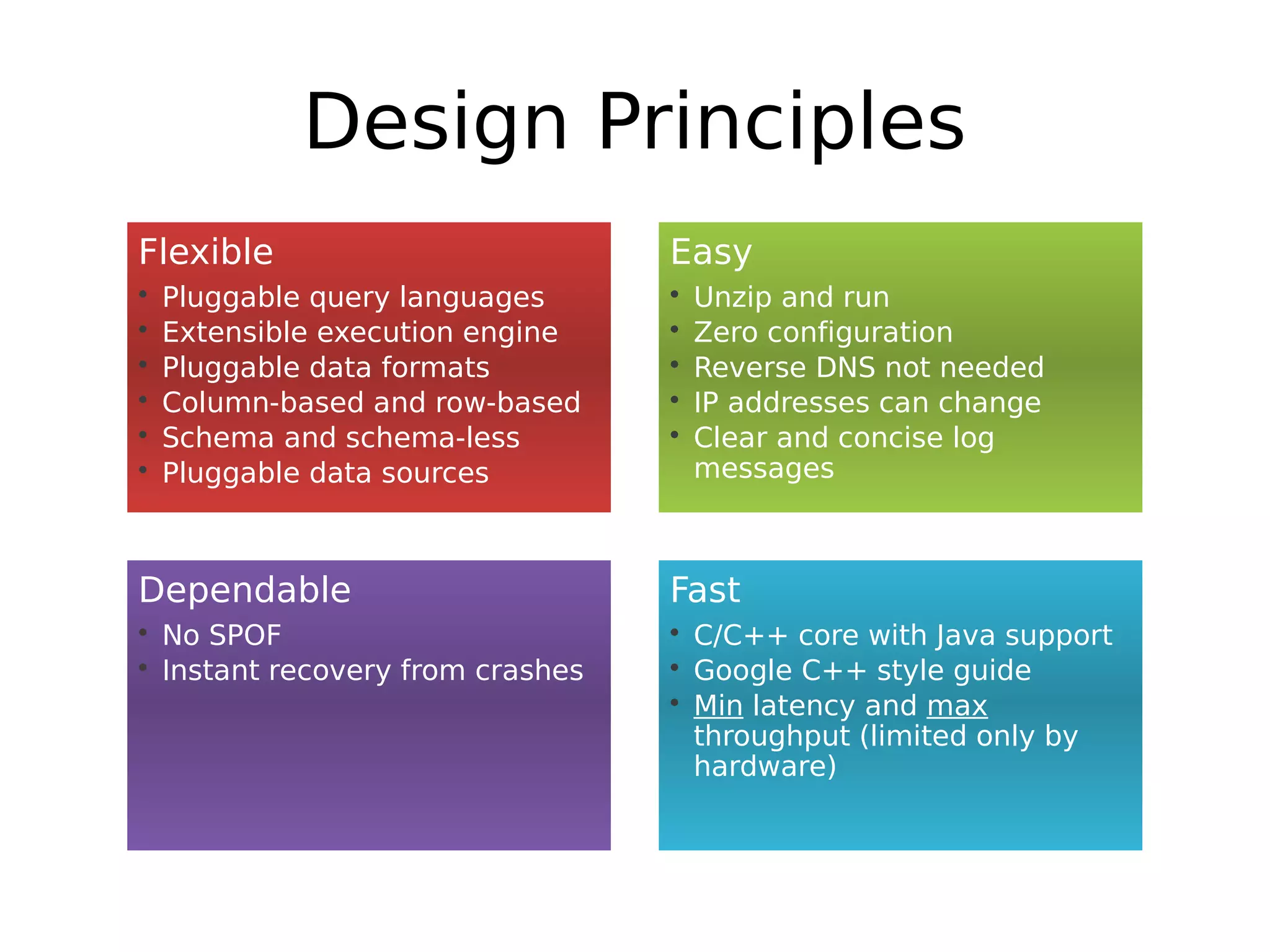
Apache Drill is a data analytics system with a flexible architecture that allows for pluggable components. It includes a driver, parser, compiler/optimizer, execution engine, and storage handlers. The parser converts queries to an intermediate representation, which is optimized and then executed across a cluster by the execution engine. Drill supports various data formats and sources through its extensible storage interfaces and scanner operators. Its design focuses on flexibility, ease of use, dependability, and high performance.










































![[UniteKorea2013] Serialization in Depth](https://cdn.slidesharecdn.com/ss_thumbnails/serializationtim-130513233953-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



