Downloaded 16 times



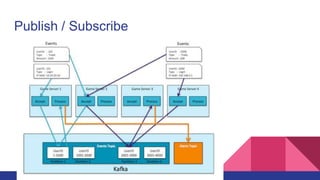
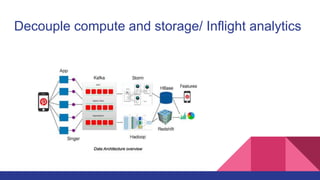
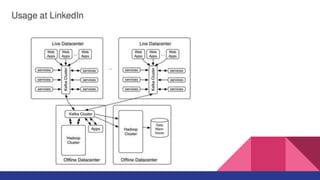



The document discusses various use cases for Apache Kafka, including website activity tracking, messaging, and stream processing. It highlights the complexities of implementing multi-data center (DC) clusters, emphasizing security and latency issues, and suggests best practices typically employed on AWS. Contact information for the author, Omid Vahdaty, is also provided.



































































