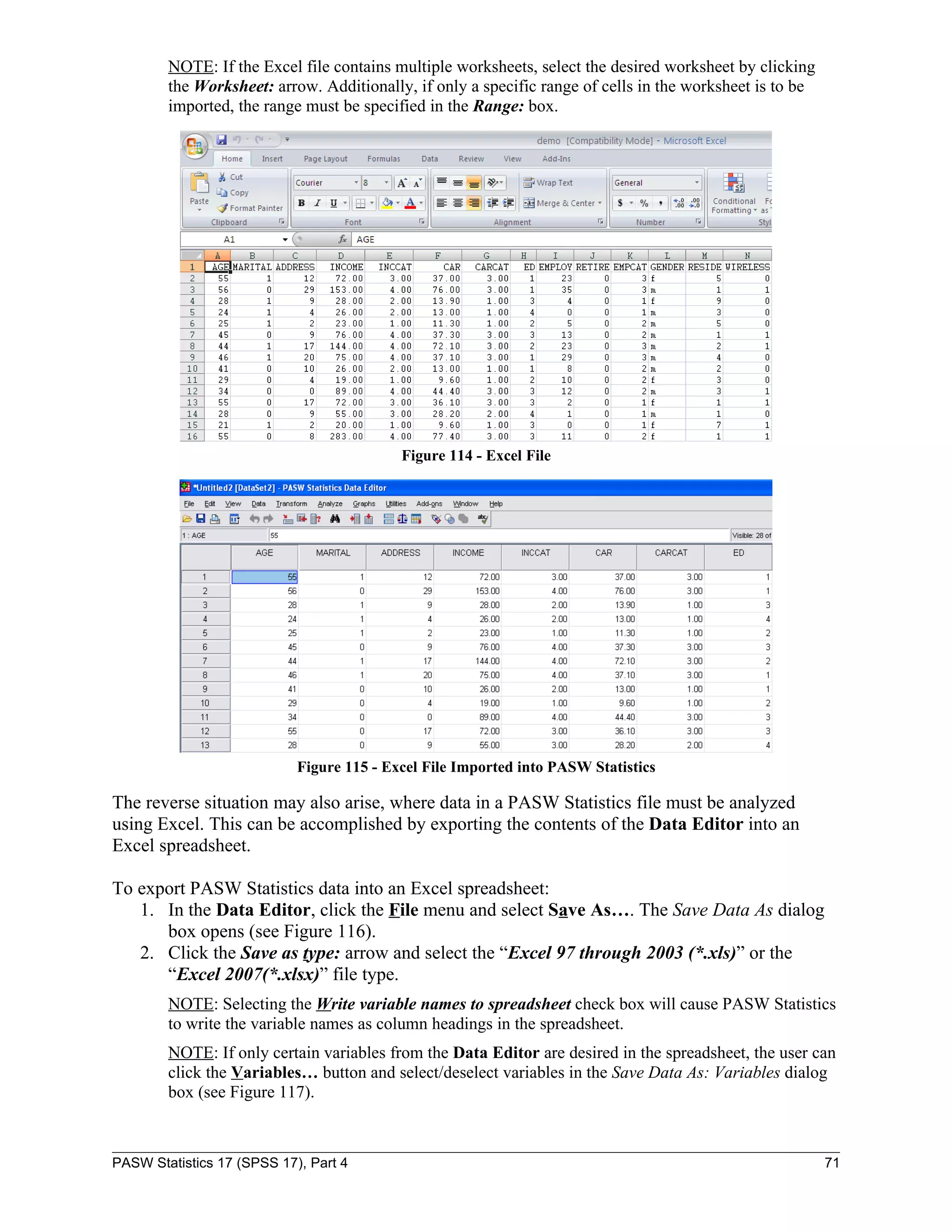
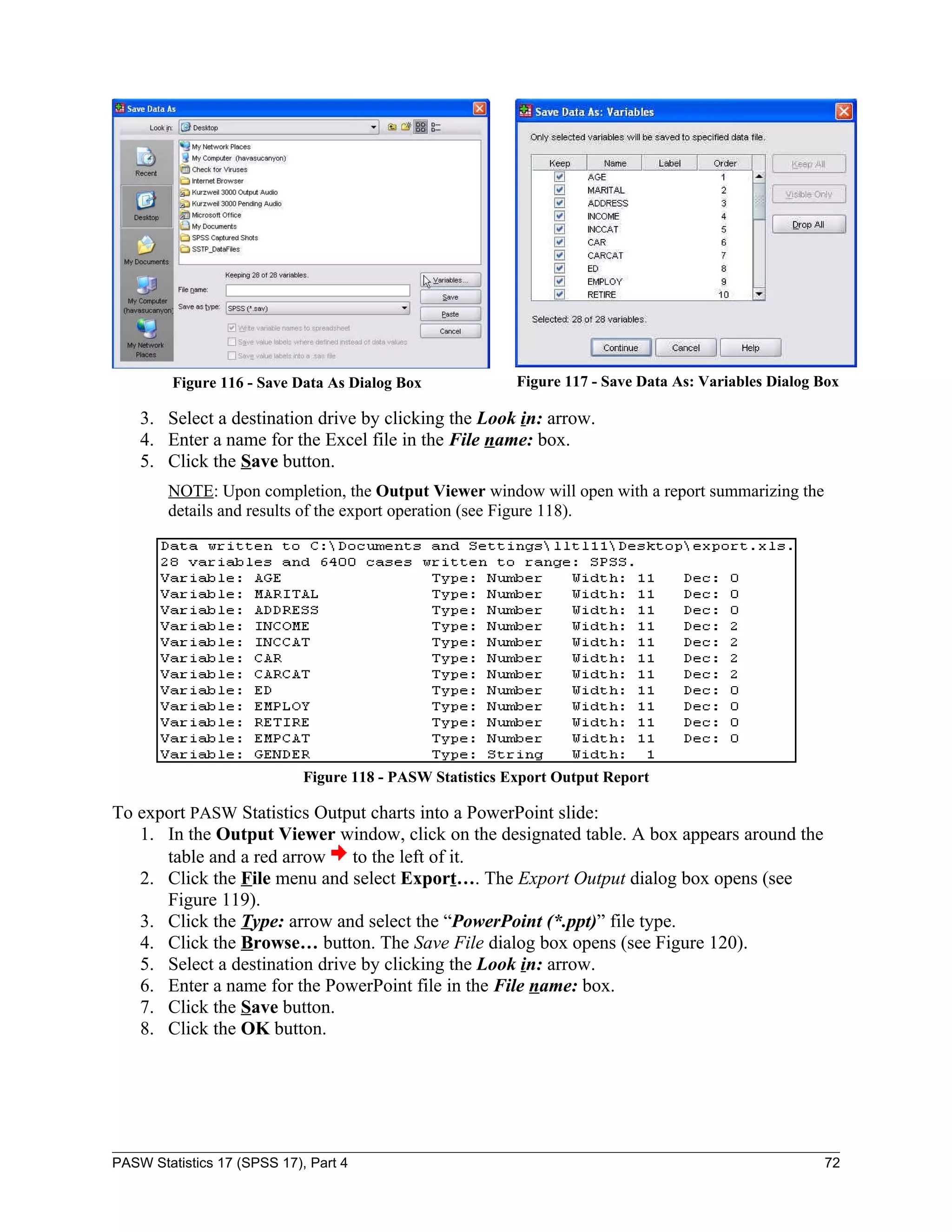
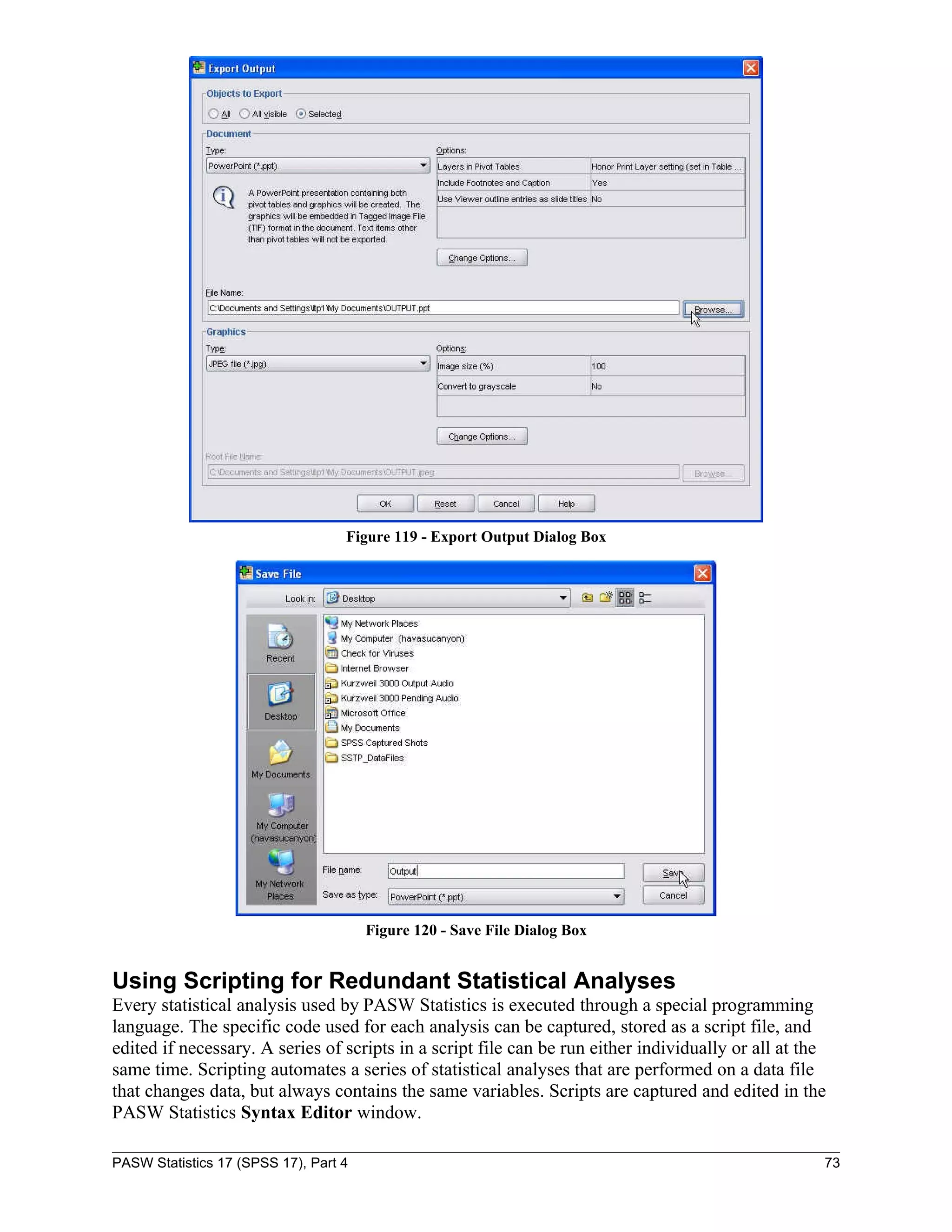
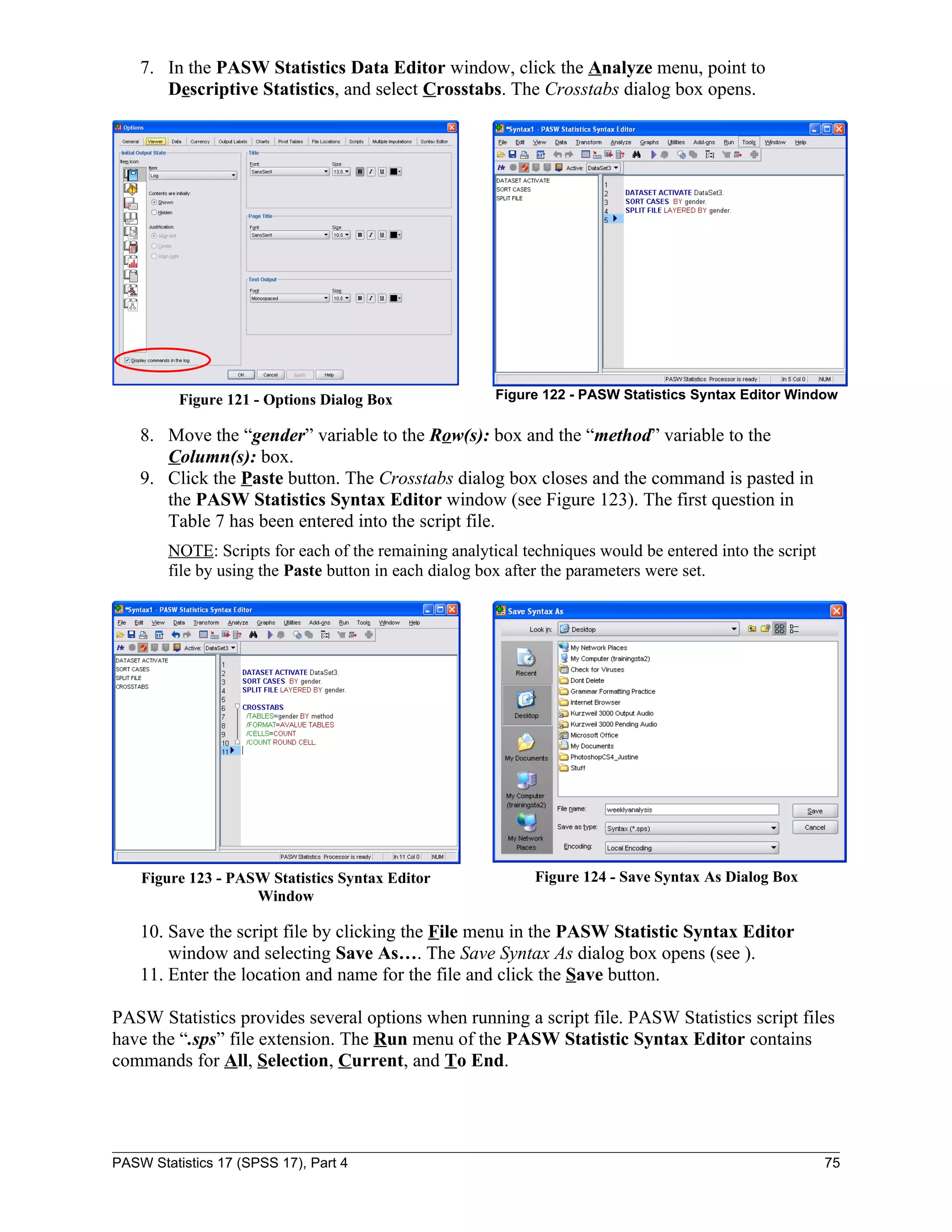
This document serves as a comprehensive guide to PASW Statistics 17 (SPSS 17), detailing its functionalities for data analysis, particularly in survey research. It includes instructions on downloading data files, creating and manipulating data files, and performing various statistical analyses such as descriptive statistics, frequency analysis, and regression. Additionally, it addresses specific research questions through practical examples, illustrating how to interpret the results and utilize various statistical tests.





![Element Description
Cell A cell is an intersection between cases and variables. Each response to a
survey question should be entered in a cell for each participant according
to the defined variable data types.
VARIABLE VIEW
Variable View is where variables are defined by assigning variable names and specifying the
attributes, such as data type (“String,” “Date,” “Numeric,” etc.), value labels, and measurement
scales (“Nominal,” “Ordinal,” or “Scale”). Users can think of Variable View as the backbone
structure for the Data View; data cannot be entered nor viewed without first defining variables in
Variable View (see Table 2).
Table 2 - Elements in Variable View
Element Description
Variable Name PASW Statistics will initially give a default variable name (var00001) that
users can change. It is recommended to assign a brief and meaningful
name to variables (e.g., “Name,” “Gender,” and “GPA”).
Variable Type The variable type determines how the cases are entered. Generally, text-
based characters are of “String” type and number-based characters are of
“Numeric” type. For example, if a user has a variable called “Name,”
then its variable type should be “String.” Similarly, a variable named
“GPA” should be a “Numeric” type with (normally two) decimal places.
Value Labels Value labels allow users to describe what the variable name stands for.
For example, if a variable has been defined as “Fav,” most likely others
may not know what it stands for. To avoid misinterpretation, value labels
can be utilized to clearly define variable names.
Creating a Data File
Creating a new PASW Statistics data file consists of two stages: (1) defining variables and (2)
entering the data. Defining the variables involves multiple processes and requires careful
planning. Once the variables have been defined, the data can then be added.
DEFINING VARIABLES
First, variable names based on your research questionnaire need to be assigned. If variable names
are not assigned, PASW Statistics will assign default names that may not be recognizable.
Second, the Type attribute should be specified for each variable. If necessary, assign labels to
values to help all users of the file understand the data better.
To define variables (example):
1. Click the Variable View tab at the lower left corner of the Data Editor window (see
Figure 3).
2. Type [Name] in the first cell under the Name column and press the [Enter] key.
3. Under the Type column, click the ellipses button . The Variable Type dialog box opens
(see Figure 4).
4. Select the String option.
5. Click the OK button.
PASW Statistics 17 (SPSS 17), Part 1 6](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-6-2048.jpg)
![Figure 3 - Variable View Tab
Figure 4 - Variable Type Dialog Box
6. Type [Gender] in row two under the Name column.
7. Activate the cell in row two under the Decimals column and change the entry to “0”
using the spin box.
8. Type [What is your gender?] in row two under the Label column.
9. Click the ellipses button in row two under the Values column. The Value Labels dialog
box opens (see Figure 5).
10. Type [1] in the Value: box.
11. Type [female] in the Label: box.
12. Click the Add button.
13. Repeat steps 10-12 using a value of [2] and a label of [male].
Figure 5 - Value Labels Dialog Box (Gender)
14. Click the OK button.
15. Type [GPA] in row three under the Name column and press the [Enter] key.
16. Type [Age] in row four under the Name column.
17. Click row four under the Decimals column and change the entry to “0” using the spin
box.
18. Type [What is your age?] in row four under the Label column.
19. In row four under the Values column, click the ellipses button. The Value Labels dialog
box opens (see Figure 6).
20. Type [1] in the Value: box.
21. Type [19 or younger] in the Label: box.
22. Click the Add button.
PASW Statistics 17 (SPSS 17), Part 1 7](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-7-2048.jpg)
![23. Repeat steps 20-22 for values [2] through [5] and label them as shown in Table 3 (you
may also refer back to the sample questionnaire). See Figure 6 for the results.
24. Click the OK button.
Table 3 - Value Labels
Value Label
2 20-23
3 24-27
4 28-31
5 32 or over
Figure 6 - Value Labels Dialog Box (Age)
DATA ENTRY
After defining the variables, users can enter data for each case. If variables are defined as having
a “Numeric” data type, then numeric data should be entered. PASW Statistics will only accept
numeric digits (0-9) for a “Numeric” data type. If variables are defined as “String” data, any
keyboard character can be entered.
To enter data:
1. Click the Data View tab at the lower left corner of the Data Editor window (see Figure
7).
2. Click in a cell and type the corresponding data. The entry will also appear in the Cell
Editor (see Figure 8).
Cell Editor
Figure 8 - Data Entry
Figure 7 - Data View Tab
PASW Statistics 17 (SPSS 17), Part 1 8](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-8-2048.jpg)
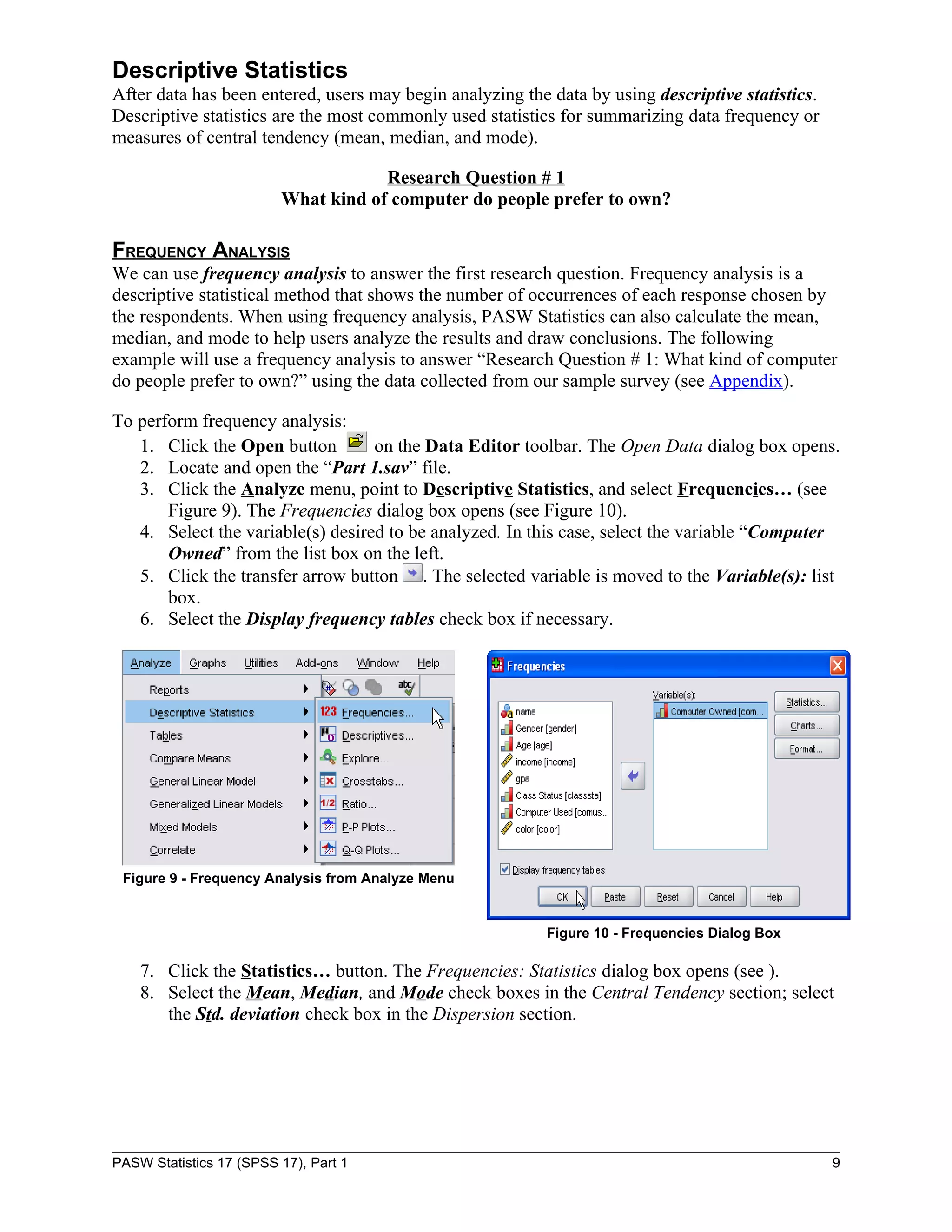


![Figure 21 - Split File Output Data
Answer to Research Question # 3
Is computer color preference different between genders?
Answer: Yes
Explanation: There is a computer color preference difference based on gender. From the
crosstabulation output, females prefer “IBM or Compatible” of “Other” color over the colors
beige, black, gray, or white. The male group prefers “IBM or Compatible” of “black” color.
FIND AND REPLACE
In PASW Statistics, the Find and Replace function is more efficient to use. Users can use Find
and Replace in Data View. However, only the Find function is available for users in Variable
View.
To use the Find and Replace function:
1. Click the Edit menu and select Find…. The Find and Replace dialog box opens (see
Figure 22).
2. In the Find: box, type [Clinton].
3. Select the Replace check box to replace ‘Clinton’ with another word.
4. Click in the Replace with: box, and type the name [Cliff].
5. Click the Show Options button.
6. Under Match to, select the Entire cell option.
7. Click the Replace All button.
Figure 22 - Find and Replace Dialog Box (Data View)
PASW Statistics 17 (SPSS 17), Part 1 15](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-15-2048.jpg)






![INDEPENDENT-SAMPLES T TEST
An Independent-Samples T Test is used to determine the likelihood that two independent data
samples came from populations that have identical means. If this were true, then the difference
between the means should be equal to zero. The null hypothesis in this case would be that the
two means are equal.
Two variables are required in the data set. One variable is the measured parameter. Examples
include weight, height, or frequency. The second variable divides the data set into two groups.
Light and Dark are the groups whose means will be compared.
Research Question # 3
Is there a difference in the average number of seedlings grown in the light
and those grown in the dark?
In this example, 20 Petri dishes each contained 10 celery seeds. Ten of the dishes were kept in
the dark for one week; the other 10 were placed under a grow light for the same amount of time.
At the end of the week, the number of seeds that sprouted was counted in each dish.
H0: Variance (light) = variance (dark).
H1: Variance (light) ≠ variance (dark).
H0: There is no difference between seedlings under the light and in the dark ( (light) = = (dark)).
H1: There is sig. difference between seedlings under the light and in the dark ( (light) ≠ (dark)).
NOTE: The first set of hypotheses is testing the variance, while the proceeding set is testing for the mean.
The variances have to be equal before we can determine if the means are equal.
NOTE: Variance: The arithmetic mean of the squared deviations from the mean, which is essentially used
to see how far the single samples are from the mean. We need to make sure the variances are equal before
we can determine if the means are equal. If the variances are equal, users will be able to move to the T
Test. If the variances are not equal, users will have to do more testing.
To run the Independent-Samples T Test:
1. Locate and open the “Seedlings.sav” file.
2. In Data View, click the Analyze menu, point to Compare Means, and select
Independent-Samples T Test…. The Independent-Samples T Test dialog box opens (see
Figure 27).
3. Select the “Seedlings” variable in the list box on the left.
4. Click the transfer arrow button to move the variable to the Test Variable(s): list box.
5. Select the “Treatment” variable in the list box on the left.
6. Click the transfer arrow button to move the variable to the Grouping Variable: list box.
7. Click the Define Groups… button. The Define Groups dialog box opens (see Figure 28).
8. Enter [0] in the Group 1: box, enter [1] in the Group 2: box, and then click the Continue
button.
9. Click the OK button. The Output Viewer window opens with several tables, including
an Independent-Samples Test table (see Figure 29).
PASW Statistics 17 (SPSS 17), Part 2 22](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-22-2048.jpg)

![Figure 31 - Define Multiple Response Sets Dialog Box
Figure 30 - Define Variable Sets from Analyze
Menu
3. Select the “American,” “TWA,” “United,” “USAir,” and “Other” airline variables and
move them to the Variables in Set: list box.
4. Make sure the Dichotomies option is selected and enter [1] in the Counted value: box.
5. Type [Airlines] in the Name: box.
6. Type [Airline frequency of response] in the Label: box.
7. Click the Add button. The set is created as “$Airlines” and listed in the Multiple
Response Sets: list box.
8. Click the Close button.
MULTIPLE RESPONSE FREQUENCIES
It is possible to obtain the answer by running a frequency analysis for each of the airline
variables. The result of such an analysis will only provide an overall raw frequency for each
response and will not allow percentage comparisons between the different airlines. A frequency
analysis that uses a multiple response set will provide an appropriate response with concise
output.
Research Question # 4
In a survey of airline passengers, which airline was selected as having been
flown most often in the previous six months?
To analyze the frequency of response for each variable in a multiple response set:
1. Click the Analyze menu, point to Multiple Response, and select Frequencies…. The
Multiple Response Frequencies dialog box opens (see Figure 32).
2. Select the multiple response set labeled “$Airlines” and move it to the Table(s) for: list
box.
3. Click the OK button. An Output Viewer window opens with the frequency analysis (see
Figure 33).
PASW Statistics 17 (SPSS 17), Part 2 24](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-24-2048.jpg)

![To incorporate a multiple response set into a crosstab analysis:
1. Click the Analyze menu, point to Multiple Response, and select Crosstabs…. The
Multiple Response Crosstabs dialog box opens (see Figure 34).
Figure 34 - Multiple Response Crosstabs Dialog Box
2. Select the “FearFactor” variable as the Row(s): variable and the “$Airlines” multiple
response set as the Column(s): variable.
3. Select the “FearFactor” variable after it is designated as the Row(s): variable. The
Define Ranges… button becomes active.
4. Click the Define Ranges… button. The Multiple Response Crosstabs: Define Variable
Ranges dialog box opens (see Figure 35).
Figure 35 - Multiple Response Crosstabs: Define Variable Ranges Dialog Box
5. Enter [0] in the Minimum: box and [1] in the Maximum: box for the “FearFactor”
variable.
6. Click the Continue button.
7. Click the Options… button. The Multiple Response Crosstabs: Options dialog box opens
(see Figure 36).
8. Select the Cases option and then click the Continue button.
9. Click the OK button. The Output Viewer window opens with the crosstab results (see
Figure 37).
PASW Statistics 17 (SPSS 17), Part 2 26](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-26-2048.jpg)

![3. Type [active] in the first cell under the Name column and press the [Enter] key.
4. Click in the first cell under the Decimals column and decrease the entry to “0.”
5. Click in the first cell under the Values column and click the Ellipses button . The
Value Labels dialog box opens (see Figure 39).
6. Type [1] in the Value: box.
7. Type [Strongly Disagree] in the Label: box.
8. Click the Add button.
9. Assign [2], [3], and [4] for [Disagree], [Agree], and [Strongly Agree], respectively, by
repeating steps 6-8 for each value added (see Figure 39).
Figure 39 - Value Labels Dialog Box
10. Click the OK button.
11. Switch back to Data View (see Figure 40).
12. Click the “active” variable heading to highlight the column.
13. Click the Edit menu and select Copy to copy the properties of the variable “active.”
14. Highlight the number of variables needed to apply the same properties to by clicking on
the header of the first variable and dragging the pointer across to the last header (see
Figure 41 and Figure 42).
15. Click the Edit menu and select Paste. The copied properties of the variable “active” will
be applied to the target variables, and the Data View and Variable View will change (see
Figure 43 and Figure 44).
Figure 41 - Selected Variable
Figure 40 - Data View Tab
PASW Statistics 17 (SPSS 17), Part 2 28](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-28-2048.jpg)
![Figure 43 - Data View Showing New Variables
Figure 42 - Selecting Target Variables
Figure 44 - Variable View Showing New Variables
INSERTING VARIABLES AND CASES
By using Insert Variable and Insert Cases, variables and cases can be added into any location
of the data file in a simple, straightforward manner. Assume that one wants to insert a new
variable named “midterm” between “pretest” and “posttest” and use it for test score data. The
following instructions describe how to insert a new variable and make it available for “Numeric”
data type.
To insert a variable:
1. Switch to Data View.
2. Click the “posttest” variable heading to highlight the column.
3. Click the Edit menu and select Insert Variable. A new variable is inserted to the left of
the highlighted variable (“posttest”).
NOTE: The new variable is created with a default name “VAR00001” which can be changed
later.
4. To define the properties of the new variable, double-click the variable heading. The
Variable View is activated for the new variable.
5. Type [midterm] in the Name column of the new variable.
6. Change the variable type if desired.
In the same manner, it is possible to insert cases in a particular location in Data View. For
instance, assume that a case should be inserted between case “10” and “11” for a particular
student’s record. By following the instructions below, one case will be inserted after the 10th
case.
To insert cases (example):
1. Switch to Data View.
2. Click row number “11” to highlight the case.
3. Click the Edit menu and select Insert Cases. A new case is inserted above case “11.”
PASW Statistics 17 (SPSS 17), Part 2 29](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-29-2048.jpg)
![DELETING VARIABLES AND CASES
Variables and cases can be deleted by using the Delete command.
To delete a variable or case:
1. In Data View, click the variable heading or the case number to highlight what will be
deleted.
2. Click the Edit menu and select Clear. The variable or case is deleted.
Merging Data Files
The merging data files function is useful for users who store each of their topics in separate files
and eventually need or want to combine them together. This allows users to import data from one
file into another as long as both sets of data (from each file) contain a common identifier for each
of the cases that the user wishes to combine.
An identifier has no meaning other than to distinguish each case from one another, and to
identify the correlating cases from the additional data files. This identifier can be a unique value,
number, or letter combination to be applied to each case.
NOTE: The variables do not have to be the same across data files.
CREATING THE DATA FILE FOR MERGING
Scenario: A psychological focus group on campus needs to create a file for a longitudinal study
for ten students on campus. Each file will have the same students, but four different focal points
of study pertaining to each question. Over the five year span of the study, the ten students will be
asked twelve questions each year (one a month), and the same questions will be asked each year.
At the end of the year, the three files will be combined in an annual questionnaire file to be
properly analyzed.
The merging data files function can be used to satisfy this requirement.
Inputting the Data in Variable View
Files must be created first before being merged.
To create a data file for merging:
1. Click the File menu, point to New, and select Data.
2. Once the new file has been created, select the Variable View tab.
3. For the first variable, name it [ID] to be your identifier variable, and press the [Enter]
key.
4. Change the Type attribute by clicking the ellipses button and selecting the String option
from the Variable Type dialog box.
5. Change the width to [10] and click the OK button.
6. Click in the second variable cell, type [January], and press the [Enter] key.
7. Change the Type attribute to String.
8. In the Label attribute, type [What pet would you like to own?] (see Figure 45).
9. Repeat steps 6 through 8 to enter the data in Table 4.
For additional SPSS help, visit http://www.youtube.com/mycsula.](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-30-2048.jpg)
![Figure 45 - Define Variables in Variable View
Table 4 - Variables for Case Study
Month Attribute Type Length Label Attribute
February String 10 What is your favorite shape?
March String 12 It is 1:30pm, what are you eating?
April String 12 What is your preferred beverage?
10. Once this information has been defined in Variable View, switch by clicking the Data
View tab to enter the corresponding case information.
11. Enter [Alfred] in case 1 of the ID variable, [Bethel] in case 2 of the ID variable, down to
[Jessie] in case 10 of the ID variable. Enter the corresponding information according to
Table 5. See Figure 46 for the results.
Table 5 - Input Case Information
Case ID January February March April
1 Alfred Dog Star Pizza Water
2 Bethel Cat Square Fruit Soda Pop
3 Chris Cat Triangle Veggies Grape Juice
4 Dante Dog Rectangle Sandwich Orange Juice
5 Erica Tiger Oval Chips Aloe Water
6 Fernando Tarantula Circle Calzon Beer
7 Grenadine Dog Octagon Salad White Wine
8 Harold Bees Polygon Soup Naked Juices
9 Isadora Turtle Rhombus PandaExpress V8 Juice
10 Jessie Hamster Oval Egg Salad Lemonade
PASW Statistics 17 (SPSS 17), Part 3 31](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-31-2048.jpg)
![Figure 46 - Input Case Information
12. Save the file by clicking the File menu and selecting Save. The Save Data As dialog box
opens.
13. Select the Desktop as the destination and type [Merge 1] in the File name: text box.
14. Click the Save button.
15. Close the Output Viewer window.
MERGING THE DATA FILES
To merge data files, all files must have a common variable. The common variable in this case is
ID.
To merge data files: (First, make sure the files have the same IDs.)
1. Open the files “Merge 2” and “Merge 3” and check for consistency across all of the IDs.
2. Minimize the “Merge 2” and “Merge 3” data files.
3. Once back in the “Merge 1” file, click the Data menu, point to Merge Files, and select
Add Variables… (see Figure 47).
Figure 47 - Data Menu When Selecting Add Variables
PASW Statistics 17 (SPSS 17), Part 3 32](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-32-2048.jpg)
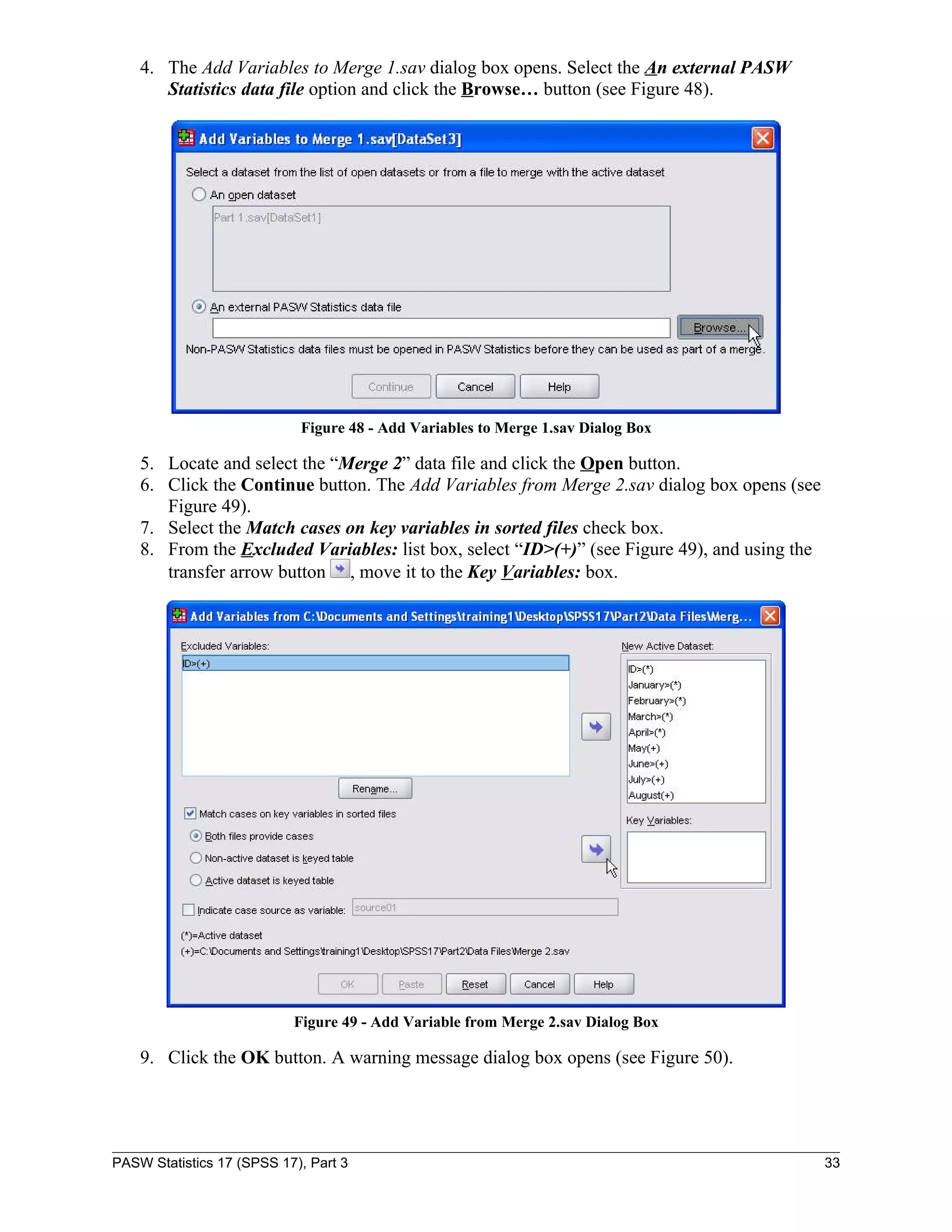
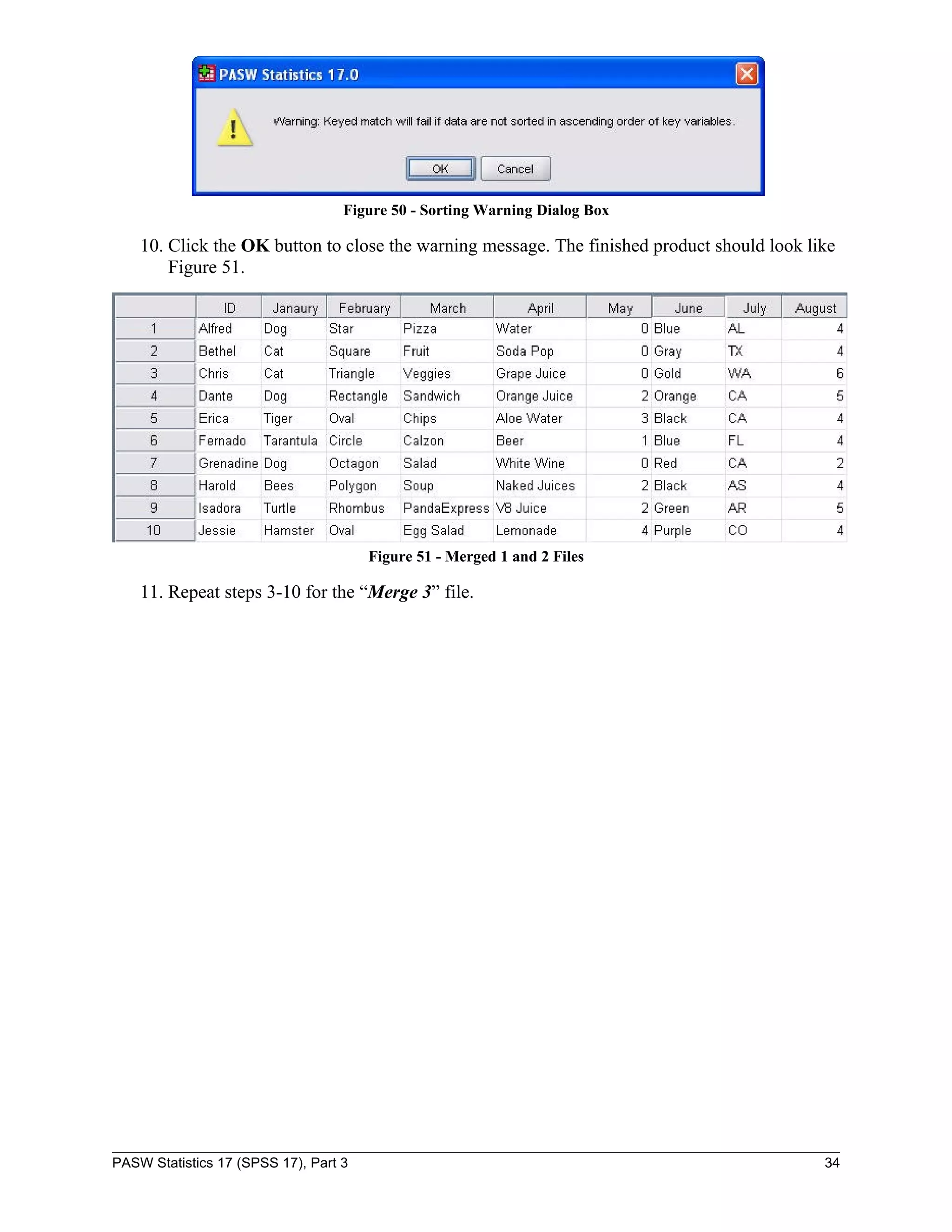



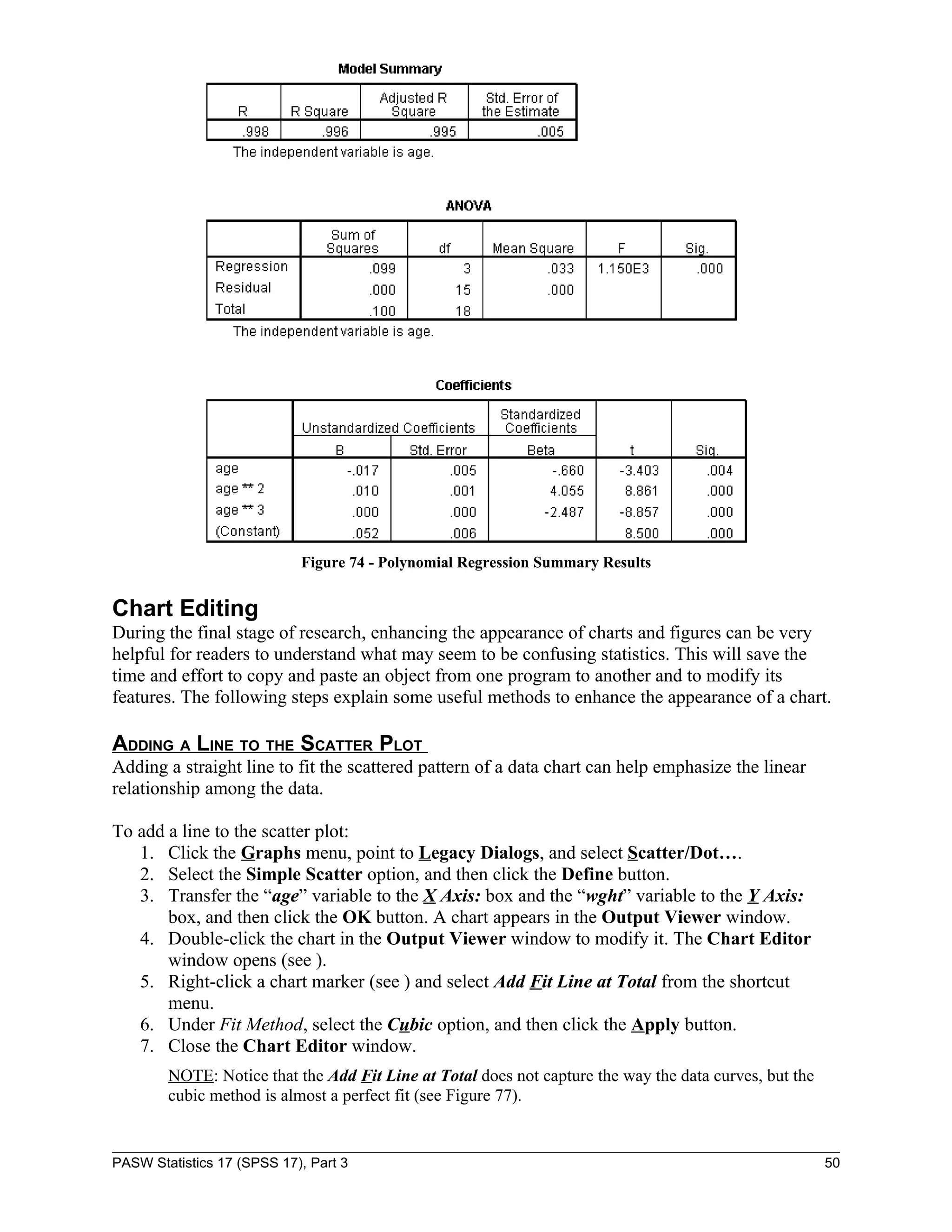
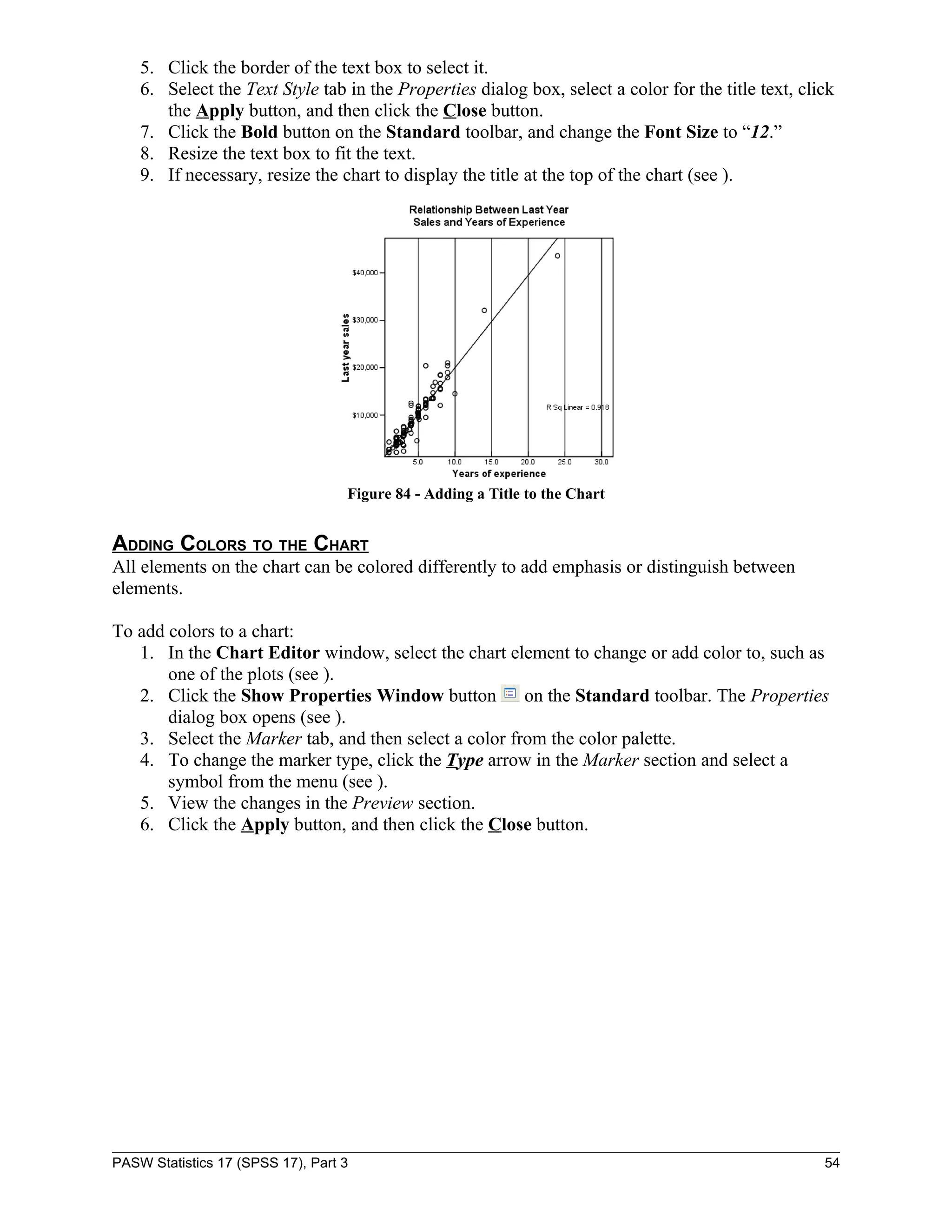
![To run a scatter plot:
1. Start PASW Statistics 17.
2. Click the Open button on the Data Editor toolbar. The Open Data dialog box opens.
3. Locate and open the “Regression.sav” file.
4. Click the Graphs menu, point to Legacy Dialogs, and select Scatter/Dot… (see ). The
Scatter/Dot dialog box opens (see ).
NOTE: To estimate the relationship between two variables, select the Simple Scatter plot.
Figure 53 - Scatter/Dot Dialog Box
Figure 52 - Graphs Menu When Selecting
Scatter/Dot
5. If necessary, select the Simple Scatter option, and then click the Define button (see ). The
Simple Scatterplot dialog box opens (see ).
Figure 54 - Simple Scatterplot Dialog Box
6. Select the variable “Last year sales [lastsale]” from the list box on the left.
7. Click the first transfer arrow button to move the variable to the Y Axis: box.
PASW Statistics 17 (SPSS 17), Part 3 38](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-38-2048.jpg)
![8. Select the variable “Years of experience [yearexpe]” from the list box on the left.
9. Click the second transfer arrow button to move the variable in the X Axis: box.
10. Click the OK button. The Output Viewer window opens with a scatter plot of the
variables (see Figure 55).
NOTE: A graph similar to Figure 55 will be displayed in the Output Viewer window. This scatter
plot indicates that there is a linear relationship between the variables “Last year sales” and “Years
of experience.”
The next step is to find a line that best accommodates the pattern of points in this scatter plot.
The steps on how to enhance graph appearance are included in the last section of this handout.
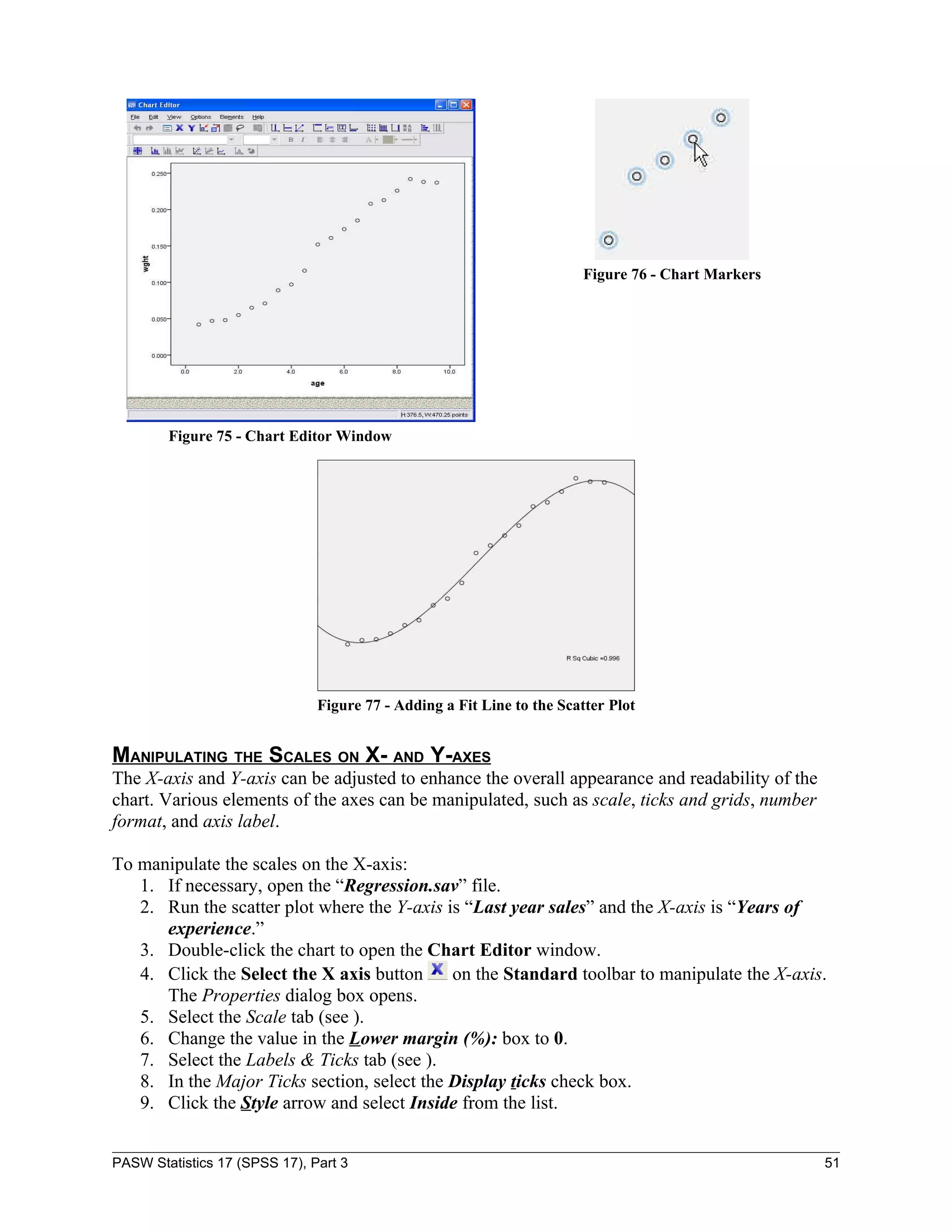
Figure 55 - Scatter Plot
PREDICTING VALUES OF DEPENDENT VARIABLES
Since it is known that a linear relationship exists between the two variables, the regression
analysis can be performed to predict this year’s sales.
To run a simple regression analysis:
1. Switch to the Data Editor window.
2. Click the Analyze menu, point to Regression, and select Linear… (see Figure 56). The
Linear Regression dialog box opens.
Figure 56 - Analyze Menu When Selecting Linear
PASW Statistics 17 (SPSS 17), Part 3 39](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-39-2048.jpg)
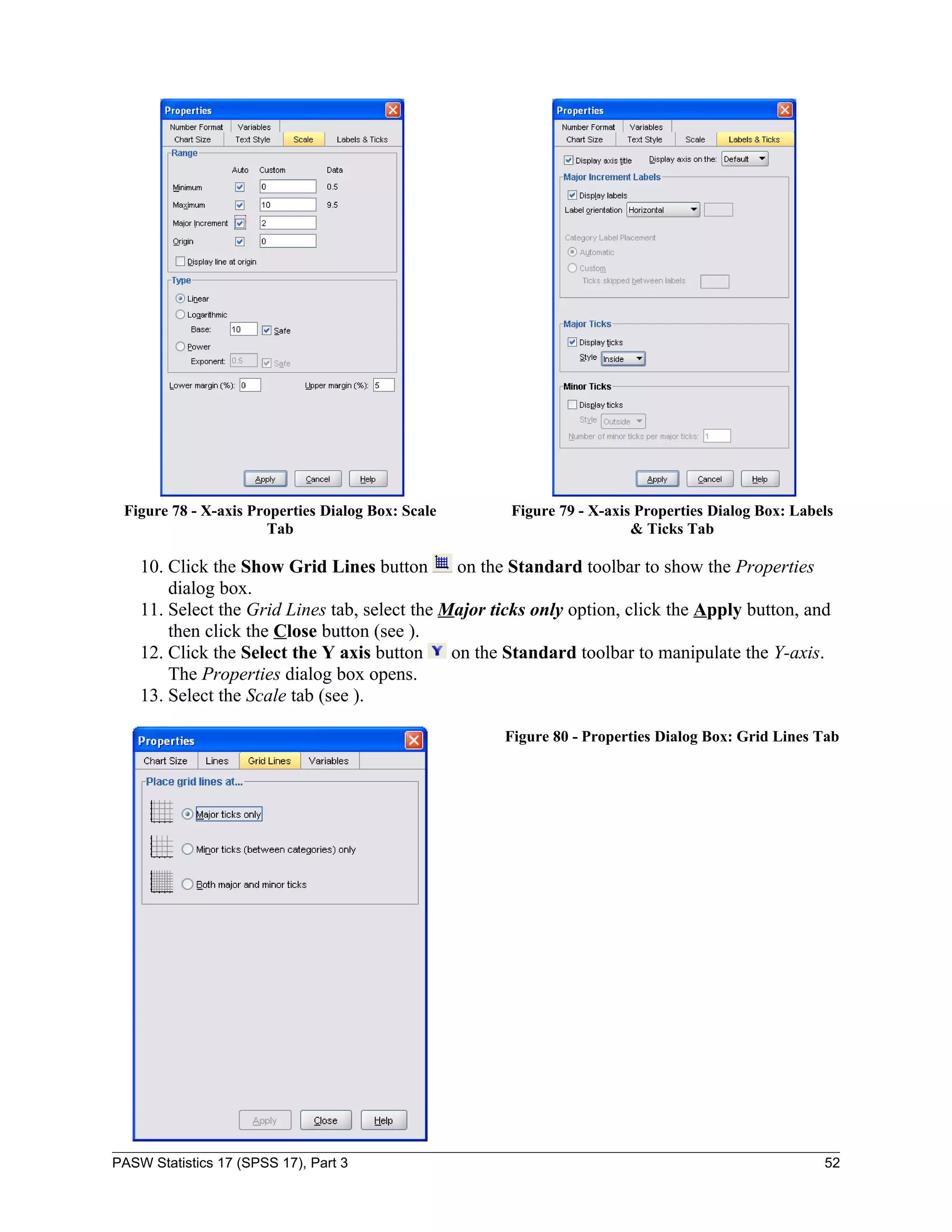
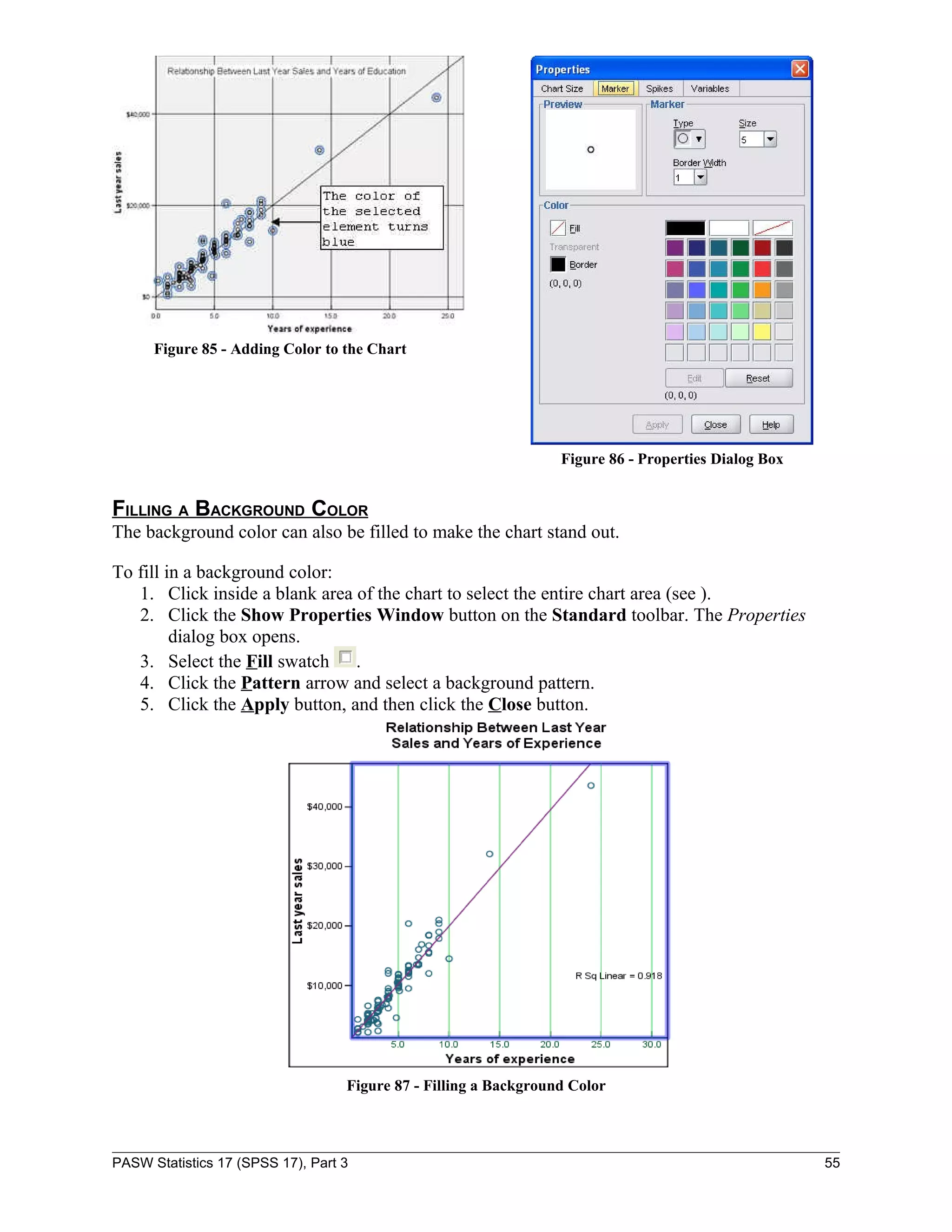
![3. Select the variable “Last year sales [lastsale]” from the variable list box on the left and
move it to the Dependent: box by clicking the first transfer arrow button (see Figure 57).
Figure 57 - Linear Regression Dialog Box
4. Select the variable “Years of experience [yearexpe]” from the variable list box on the
left and move it to the Independent(s): box by clicking the second transfer arrow button.
5. Click the OK button.
The following tables present the results of a simple regression. “R Square” (.918) indicates that
this model accounts for almost 92% of the total variation in the data (see Figure 58).
Figure 58 - Model Summary Output
PASW Statistics 17 (SPSS 17), Part 3 40](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-40-2048.jpg)
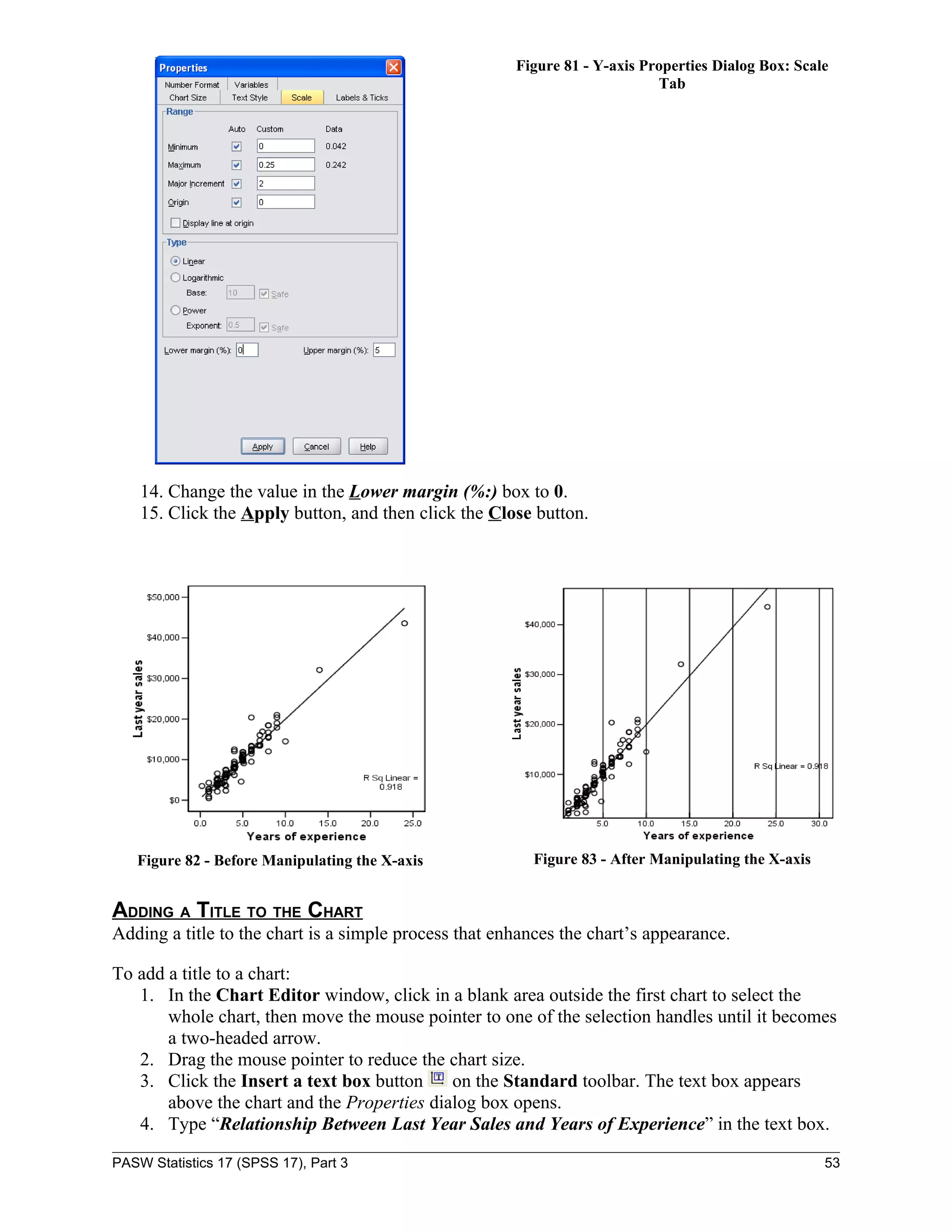
![Figure 59 - Coefficients Output
The slope and the y-intercept as seen in Figure 59 should be substituted in the following linear
equation to predict this year’s sales: Y = aX + b. In this case, the values of a, b, x, and y will be
as follows:
a = 1954.658
b = 440.987
X = Years of experience (values of independent variable)
Y = Last year sales (values of dependent variable)
PREDICTING THIS YEAR’S SALES WITH SIMPLE REGRESSION MODEL
To predict this year’s sales for each salesman, the values of a and b should be substituted in the
following linear equation:
Y = aX + b
Last year sales = (a * yearexpe) + b
This year sales = (1954.658 * yearexp2) + 440.987
a = 1954.658
b = 440.987
X = Years of experience [yearexp2]
Y = This year sales
NOTE: The new independent variable, “yearexp2” is used instead of “yearexpe” in order to predict
this year’s sales.
To predict this year’s sales using the computing function:
1. Switch to the Data Editor window.
Click the Transform menu and select Compute Variable…. The Compute Variable dialog
box opens (see Figure 60).
2. In the Target Variable: box, type [Simple].
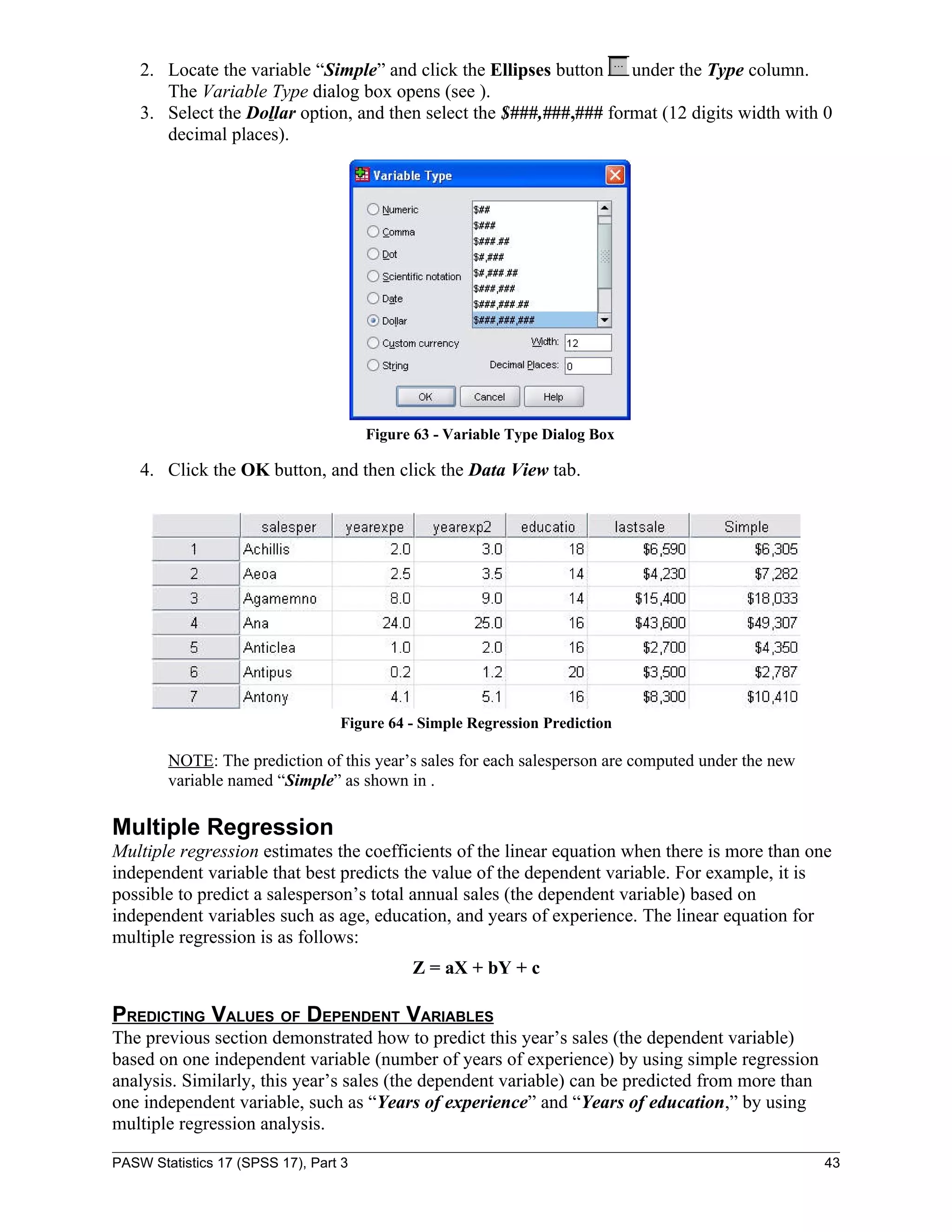
PASW Statistics 17 (SPSS 17), Part 3 41](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-41-2048.jpg)
![Figure 60 - Compute Variable Dialog Box
3. In the Numeric Expression: box, enter the following equation by typing or selecting
from the dialog box keypad:
[1954.658 * yearexp2 + 440.987]
NOTE: It is recommended to select the variable “yearexp2” directly from the variable list box
on the left of the Compute Variable dialog box to prevent typing mistakes.
4. Click the OK button. The results will be displayed in the Simple column in Data View
(see Figure 61).
Figure 61 - Simple Regression Results
To change the data type for the new variable “Simple”:
1. Click the Variable View tab at the lower left corner of the Data Editor window (see ).
Figure 62 - Variable View Tab
PASW Statistics 17 (SPSS 17), Part 3 42](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-42-2048.jpg)
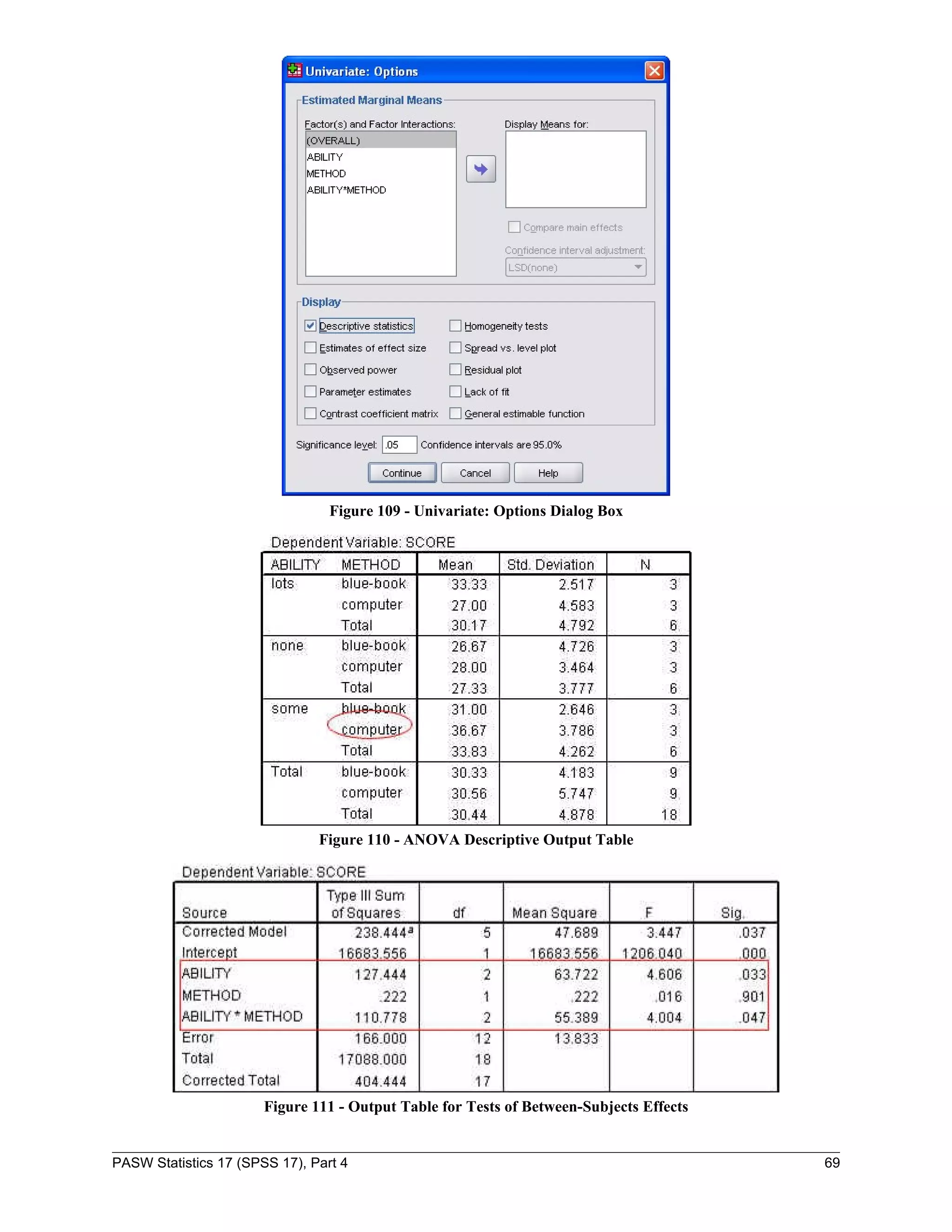
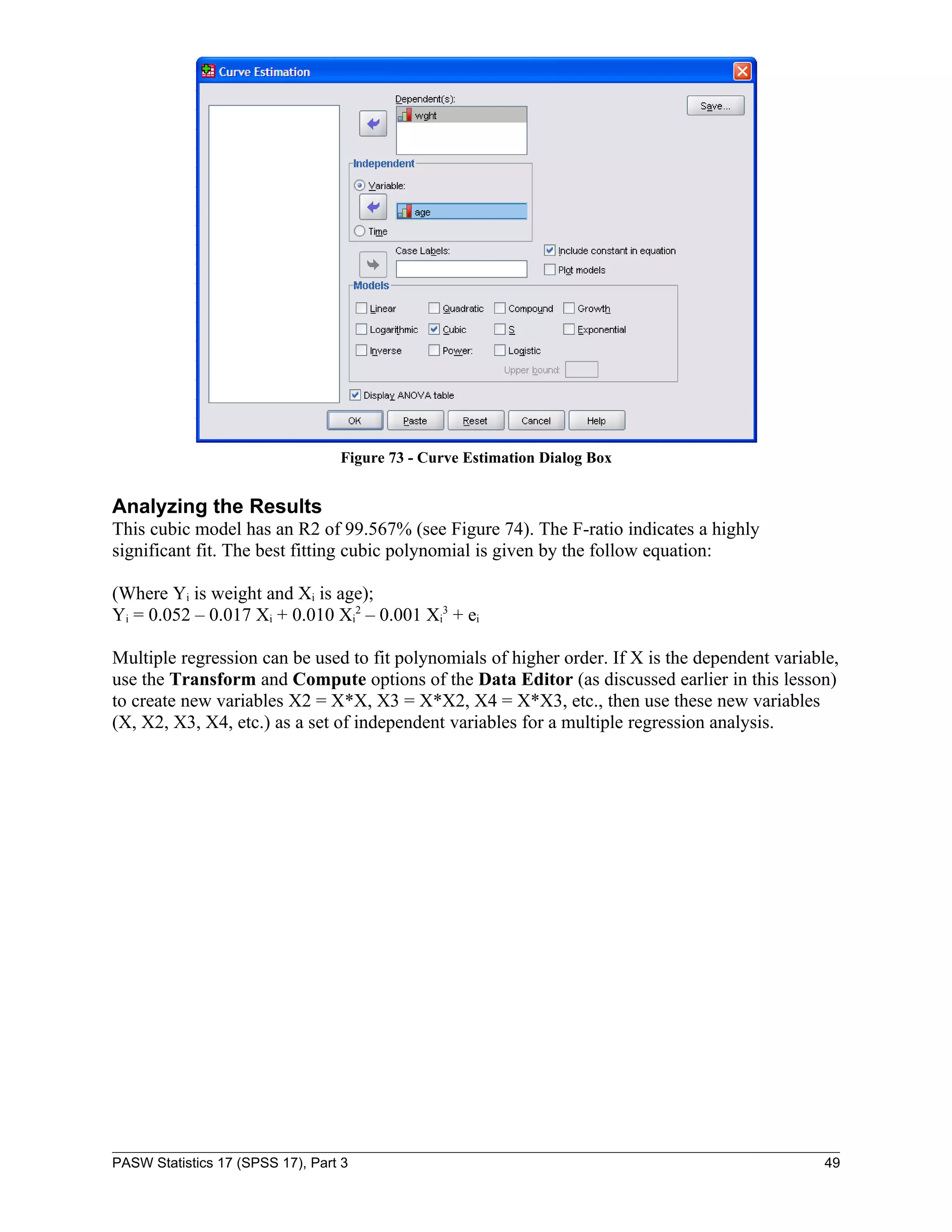
![To run multiple regression analysis:
1. Click the Analyze menu, point to Regression, and select Linear…. The Linear
Regression dialog box opens (see Figure 65).
2. From the variable list box, select “Last year sales [lastsale]” as a dependent variable and
move it to the Dependent: box by clicking the first transfer arrow button .
3. From the variable list box, select “Years of experience [yearexpe]” and “Years of
education [educatio]” and move them to the Independent(s): box by clicking the second
transfer arrow button .
4. Click the OK button.
NOTE: If there are variables in the Independent(s): or Dependent: boxes, click the Reset button
before performing steps 2 and 3 above.
Figure 65 - Linear Regression Dialog Box
NOTE: The table should look similar to . “R
Square” = “.976” indicates that this model can
predict this year’s sales almost 98% correctly.
Figure 66 - Model Summary Output for Multiple
Regression
Figure 67 - Multiple Regression Output
The slopes and the y-intercept as seen in Figure 67 should be substituted in the following linear
equation to predict this year’s sales: Z = aX+ bY + c
PASW Statistics 17 (SPSS 17), Part 3 44](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-44-2048.jpg)
![In this case, the values of a, b, x, and y will be as follows:
a = 1874.5
b = 609.391
c = (-8510.838)
X = Years of experience (independent variable)
Y = Years of education (independent variable)
Z = This year sales (dependent variable)
As indicated in the output table, the coefficient for “Years of experience” is “1874.5”and the
coefficient for “Years of education” is “609.391.”
PREDICTING THIS YEAR’S SALES WITH MULTIPLE REGRESSION MODEL
To predict this year’s sales for each salesman, the values of a, b, and c should be substituted in
the following linear equation: Z = aX + bY + c
This year sales = 1874.5 * Years of experience + 609.391 * Years of education + (-8510.838)
To predict this year’s sales by multiple regression analysis:
1. Switch to the Data Editor window.
2. Click the Transform menu and select Compute Variable…. The Compute Variable
dialog box opens (see Figure 68).
3. Click the Reset button.
4. In the Target Variable: box, type [multiple].
5. In the Numeric Expression: box, enter the following equation by typing or selecting
from the dialog box keypad:
[1874.5 * yearexp2 + 609.391 * educatio - 8510.838]
Figure 68 - Compute Variable Dialog Box
6. Click the OK button. The results will be displayed in the multiple column in Data View
(see ).
PASW Statistics 17 (SPSS 17), Part 3 45](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-45-2048.jpg)
![Figure 69 - Multiple Regression Results
NOTE: The predictions of sales for each salesperson using two independent variables are listed under the
new variable named “multiple.”
Data Transformation
Situations may arise where data transformation is useful. Most data transformations can be done
with the Compute… command. Using this command, the data file can be manipulated to fit
various statistical performances.
Research Question # 2
Who will earn a $1,000 bonus?
COMPUTING
Since each person’s yearly sales were already predicted, those who made more than $2,000
above the predicted values, obtained via multiple regression analysis, will receive $1,000 as a
bonus. Using the Compute… command, those salespeople who met the criteria can be easily
located by comparing the values of this year’s actual sales with the predictions from multiple
regression analysis computed in the previous lesson.
The first step in predicting who will receive a bonus is to calculate the difference between this
year’s actual sales and the prediction of this year’s sales from the multiple regression analysis.
To predict who will qualify for the bonus:
1. Open the “Bonus.sav” file.
2. If the Save As dialog box opens, click the No button.
3. Click the Transform menu and select Compute Variable…. The Compute Variable
dialog box opens (see ).
4. In the Target Variable: box, type [bonus].
5. In the Numeric Expression: box, type [1000].
PASW Statistics 17 (SPSS 17), Part 3 46](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-46-2048.jpg)
![Figure 70 - Compute Variable Dialog Box
6. Click the If… button. The Compute Variable: If Cases dialog box opens (see Figure 71).
7. Select the Include if case satisfies condition: option.
8. Enter the following expression by typing or selecting from the dialog box keypad:
[thissale - multiple >= 2000]
Figure 71 - Compute Variable: If Cases Dialog Box
NOTE: It is recommended that you select the variables and the >= sign directly from the variable
list box and keypad provided in the dialog box to prevent mistakes.
PASW Statistics 17 (SPSS 17), Part 3 47](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-47-2048.jpg)



![H0: Patients leave the hospital at a constant rate (there is no difference between the discharge
rates for each day of the week).
To perform the analysis:
1. Start PASW Statistics 17.
2. Click the Open button on the Data Editor toolbar. The Open Data dialog box opens.
3. Navigate to the data files folder, select the “chi-hospital.sav” file, and then click the
Open button.
Before the Chi-Square test is run, the observed values need to be declared.
To declare the observed values:
1. Click the Data menu and select Weight Cases…. The Weight Cases dialog box opens
(see Figure 88).
Figure 88 - Weight Cases Dialog Box
2. Select the Weight cases by option.
3. Select the “Average Daily Discharges [discharge]” variable and transfer it to the
Frequency Variable: box.
4. Click the OK button.
To perform the analysis:
1. Click the Analyze menu, point to Nonparametric Tests, and select Chi-Square…. The
Chi-Square Test dialog box opens (see Figure 89).
PASW Statistics 17 (SPSS 17), Part 4 58](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-58-2048.jpg)
![Figure 89 - Chi-Square Test Dialog Box
2. Select the “Day of the Week [dow]” variable and transfer it to the Test Variable List: box
(see Figure 89).
3. Click the OK button. The Output Viewer window opens (see Figure 90).
Figure 90 - Chi-Square Frequencies Output Table
Figure 91 - Chi-Square Test Statistics Output Table
PASW Statistics 17 (SPSS 17), Part 4 59](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-59-2048.jpg)
![Reporting the analysis results:
H0: Rejected in favor of H1.
H1: Patients do not leave the hospital at a constant rate.
Explanation: Figure 91 indicates that the calculated χ2 statistic, for six degrees of freedom, is
29.389. Additionally, it indicates that the significance value (0.000) is less than the usual
threshold value of 0.05. This suggests that the null hypothesis, H0 (patients leave the hospital at a
constant rate), can be rejected in favor of the alternate hypothesis, H1 (patients leave the hospital
at different rates during the week).
With Fixed Expected Values and within a Contiguous Subset of Values
By default, the Chi-Square test procedure builds frequencies and calculates an expected value
based on all valid values of the test variable in the data file. However, it may be desirable to
restrict the range of the test to a contiguous subset of the available values, such as weekdays only
(Monday through Friday).
Research Question # 2
The hospital requests a follow-up analysis: can staff be scheduled assuming that patients
discharged on weekdays only (Monday through Friday) leave at a constant daily rate?
H0: Patients discharged on weekdays only (Monday through Friday) leave at a constant daily
rate.
To run the analysis:
1. Click the Analyze menu, point to Nonparametric Tests, and select Chi-Square…. The
Chi-Square Test dialog box opens.
2. Select the Use specified range option (see Figure 89).
3. Enter [2] in the Lower: box and [6] in the Upper: box.
4. Click the OK button. The Output Viewer window opens (see Figure 92 and Figure 93).
Notice that the test range is restricted to Monday through Friday.
Figure 93 - Test Statistics Output Table
Figure 92 - Chi-Square (Subset) Frequencies Output Table
NOTE: The expected values are equal to the sum of the observed values divided by the number of
rows, while the observed values are the actual numbers of patients discharged.
Reporting the analysis results:
H0: Do not reject. Patients discharged on weekdays only (Monday through Friday) leave at a
constant daily rate.
PASW Statistics 17 (SPSS 17), Part 4 60](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-60-2048.jpg)
![Explanation: Figure 92 indicates that on average, about 92 patients were discharged from the
hospital each weekday. The rate for Mondays was below average and the rate for Fridays was
greater than average. Figure 93 indicates that the calculated value of the Chi-Square statistic was
5.822 at four degrees of freedom. Because the significance level (0.213) is greater than the
rejection threshold of 0.05, H0 (patients were discharged at a constant rate on weekdays) could
not be rejected.
Using the Chi-Square test procedure, it was determined that the rate at which patients were
discharged from the hospital was not constant over the course of an average week. This was
primarily due to a greater number of discharges on Fridays and fewer discharges on Sundays.
When the range of the test was restricted to weekdays, the discharge rates appeared to be more
uniform. Staff shortages could be corrected by adopting separate weekday and weekend staff
schedules.
With Customized Expected Values
Research Question # 3
Does first-class mailing provide quicker response time than bulk mail?
A manufacturer tries first-class postage for direct mailings, hoping for faster responses than with
bulk mail. Order takers record how many weeks each order takes after mailing.
H0: First-class and bulk mailings do not result in different customer response times.
Before the Chi-Square test is run, the cases must be weighted. Because this example compares
two different methods, one method must be selected to provide the expected values for the test
and the other will provide the observed values.
To weight the cases:
1. Open the “chi-mail.sav” file.
2. Click the Data menu and select Weight Cases…. The Weight Cases dialog box opens.
3. Select the Weight cases by option.
4. Select the “First Class Mail [fcmail]” variable and transfer it to the Frequency Variable:
box.
5. Click the OK button.
To run the analysis:
1. Click the Analyze menu, point to Nonparametric Tests, and select Chi-Square…. The
Chi-Square Test dialog box opens.
2. Select the “Week of Response [week]” variable and transfer it to the Test Variable List:
box.
3. Select the Values: option in the Expected Values section.
4. Enter [6] in the Values: box.
5. Click the Add button.
6. Repeat steps 4 and 5, adding the values [15.1], [18], [12], [11.5], [9.8], [7], [6.1], [5.5],
[3.9], [2.1], and [2] (in that order).
7. Click the OK button. The Output Viewer window opens.
NOTE: The expected frequencies in this example are the response percentages that the firm has
historically obtained with bulk mail.
PASW Statistics 17 (SPSS 17), Part 4 61](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-61-2048.jpg)
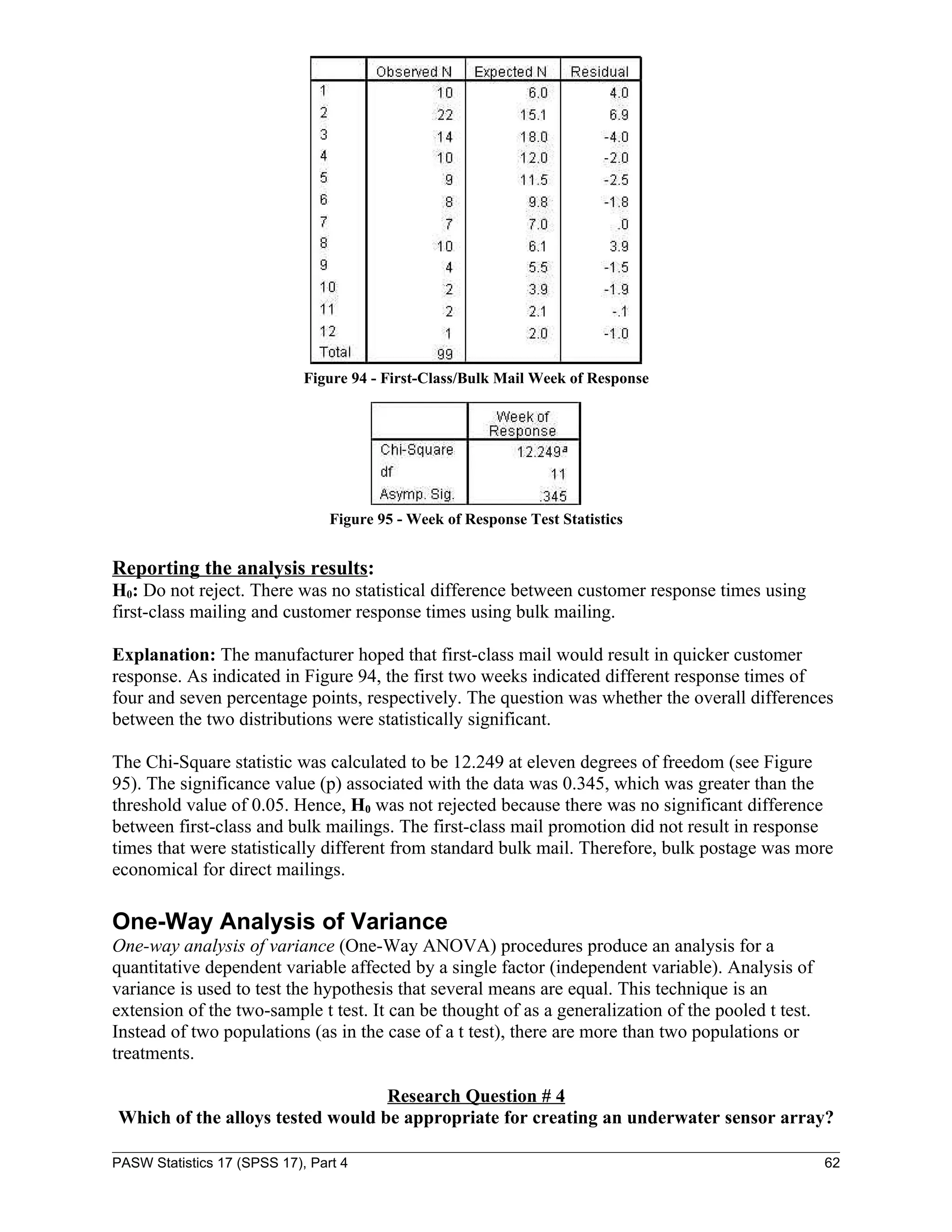
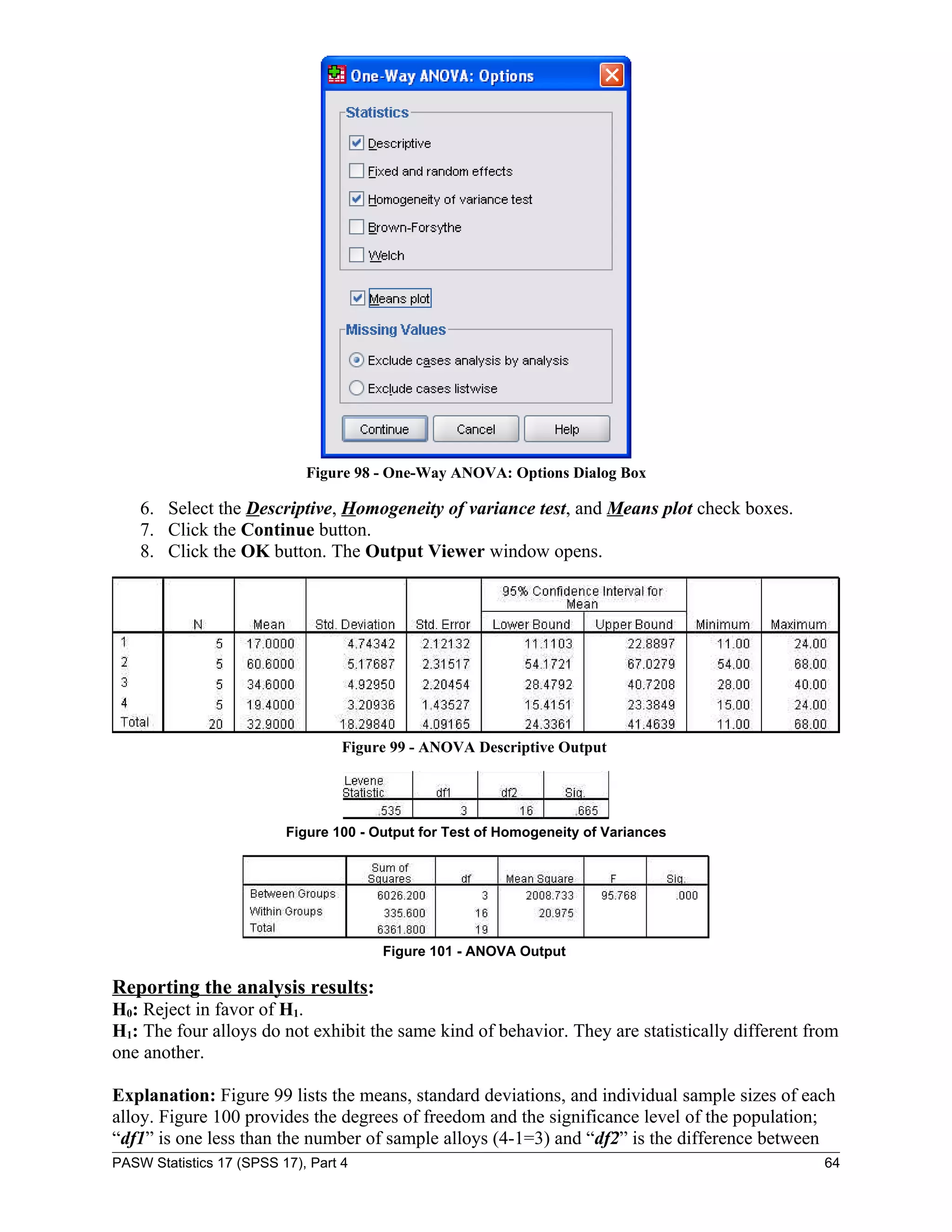
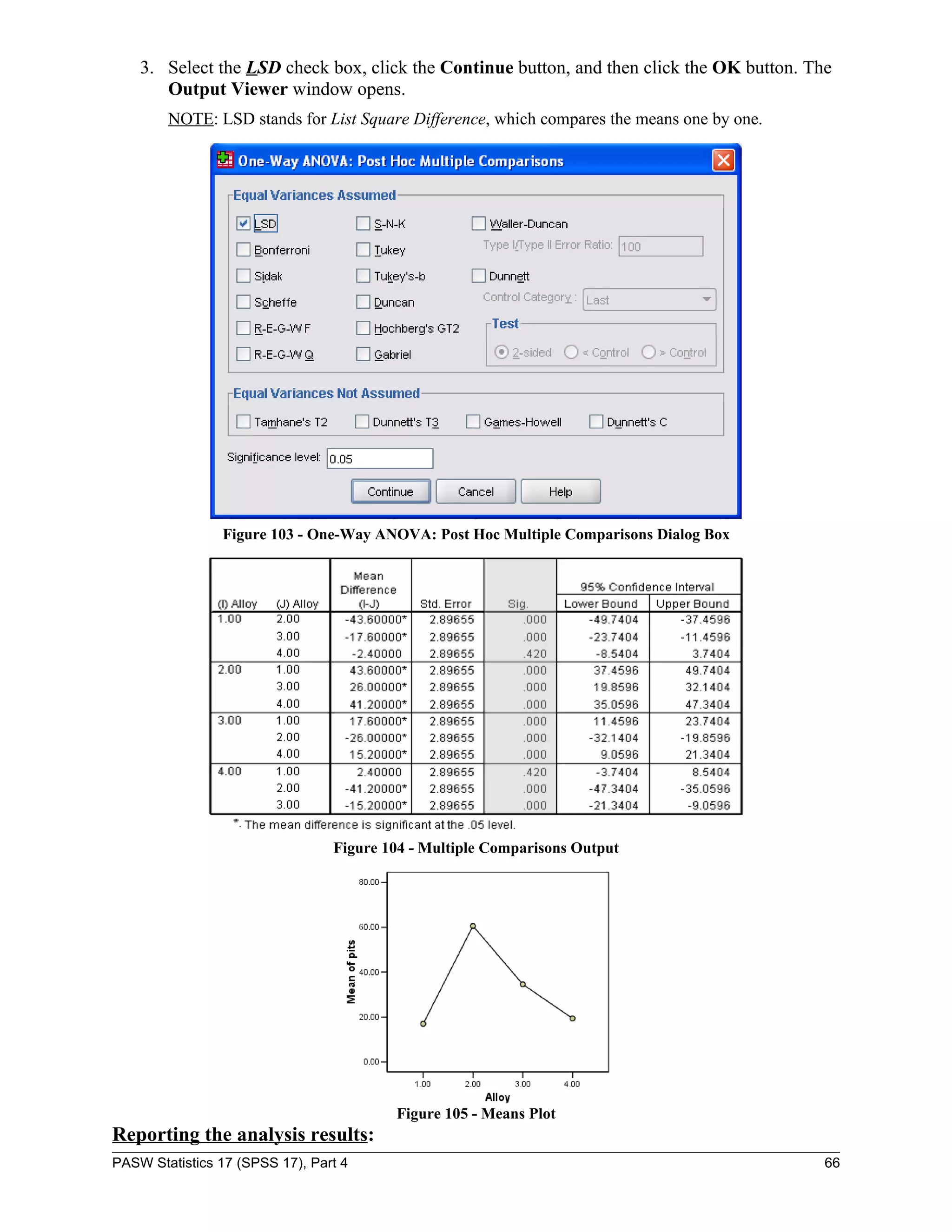
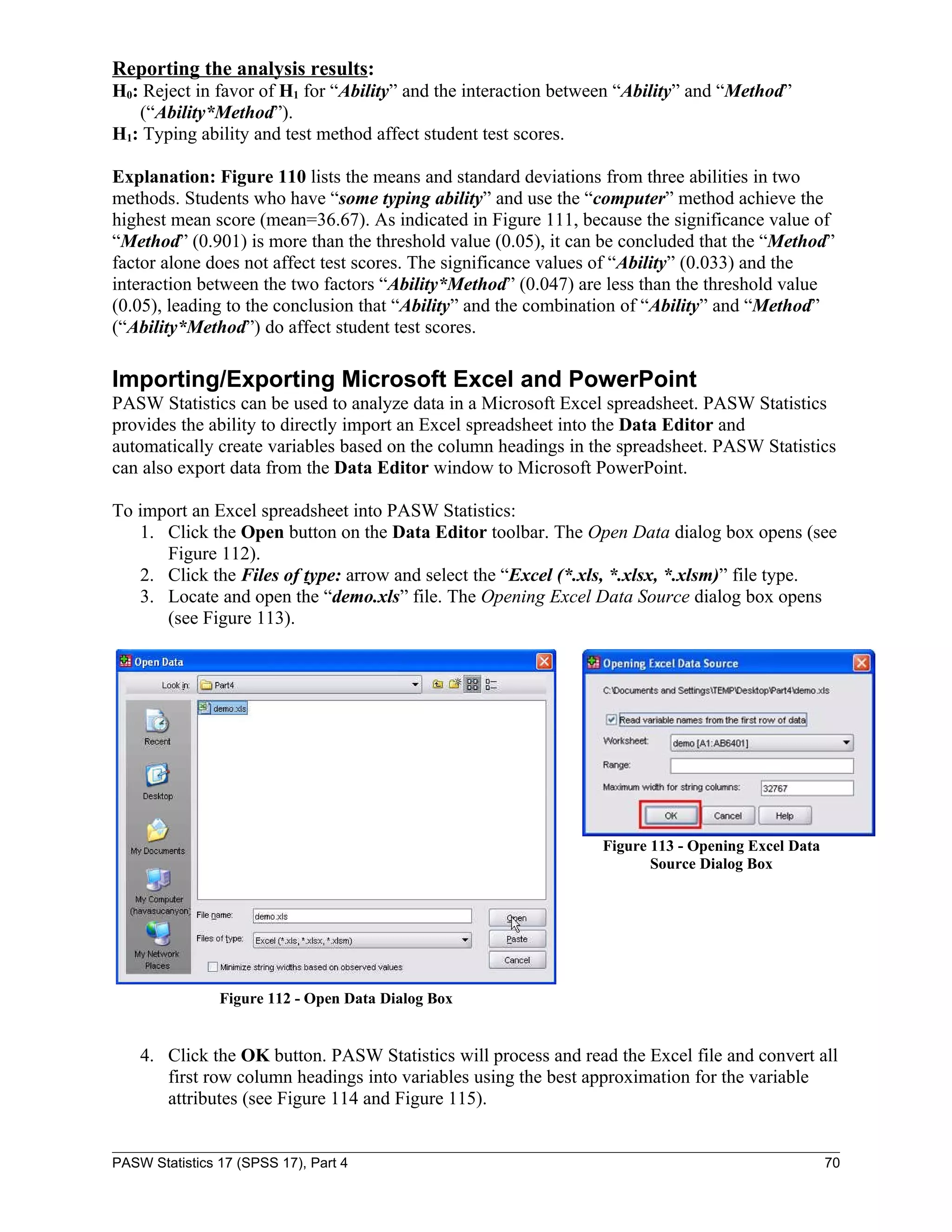
![To create an underwater sensor array, four different alloys are tested for corrosion resistance.
Five plates of the same size of each alloy are placed underwater for 60 days. After 60 days, the
number of corrosion pits on each plate is measured.
H0: The four alloys exhibit the same kind of behavior and are not different from one another.
To run One-Way ANOVA:
1. Open the “alloy.sav” file.
NOTE: Each case within the One-Way ANOVA data file represents one of the 20 metal plates
(five plates of four different alloys) and is characterized by two variables. One variable assigns a
numeric value to the alloy. The other variable is used to quantify the number of pits on the plate
after being underwater for 60 days (see Figure 96).
Figure 96 - Alloy Data File
2. In Data View, click the Analyze menu, point to Compare Means, and select One-Way
ANOVA…. The One-Way ANOVA dialog box opens (Figure 97).
Figure 97 - One-Way ANOVA Dialog Box
3. Select the “pits” variable from the box on the left and transfer it to the Dependent List:
box (see Figure 97).
4. Select the “Alloy [alloy]” variable from the box on the left and transfer it to the Factor:
box (see Figure 97).
5. Click the Options… button. The One-Way ANOVA: Options dialog box opens (see
Figure 98).
PASW Statistics 17 (SPSS 17), Part 4 63](https://image.slidesharecdn.com/paswstatisticsguideparts1to4-100608162918-phpapp02/75/SPSS-statistics-how-to-use-SPSS-63-2048.jpg)