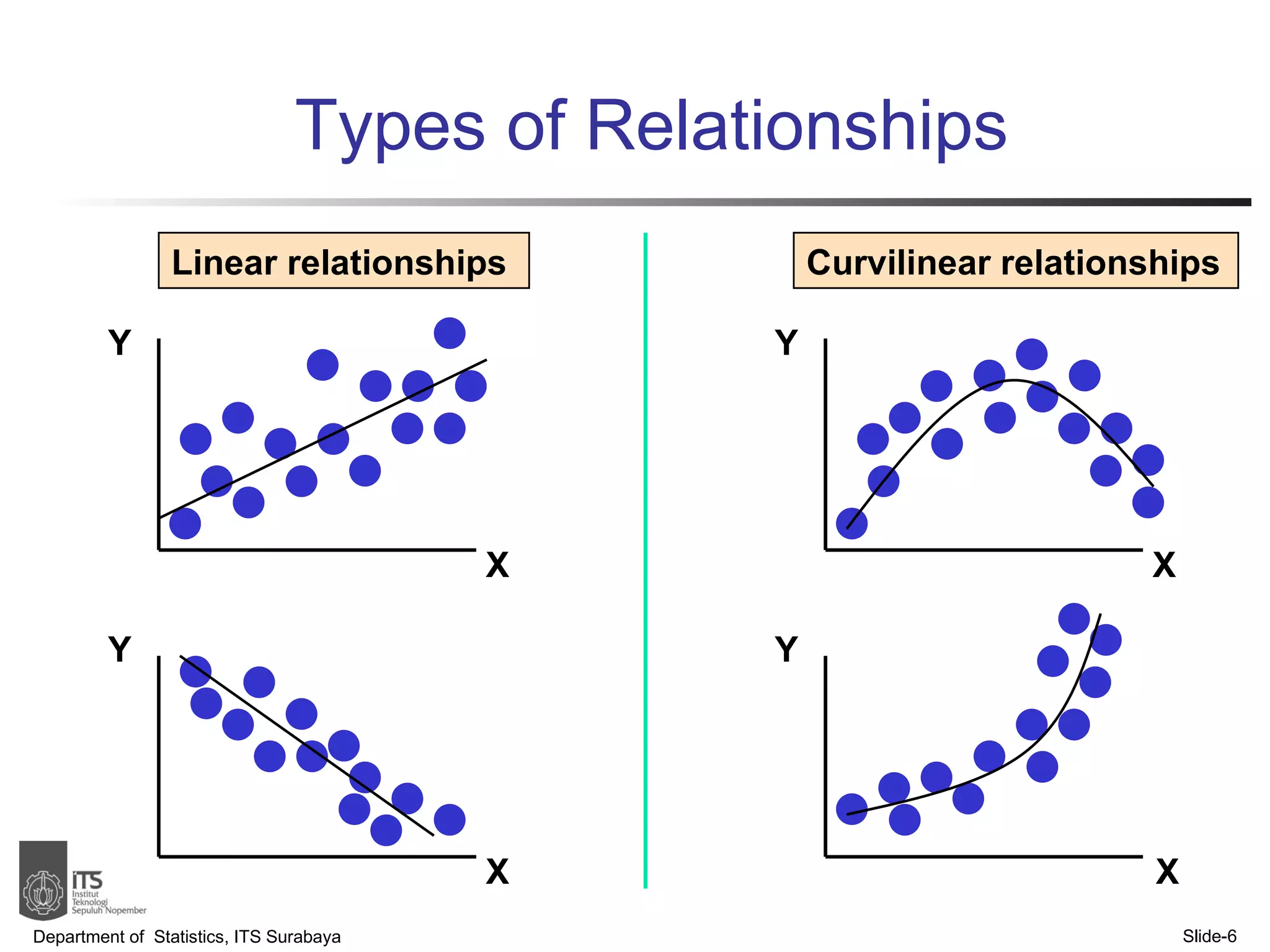
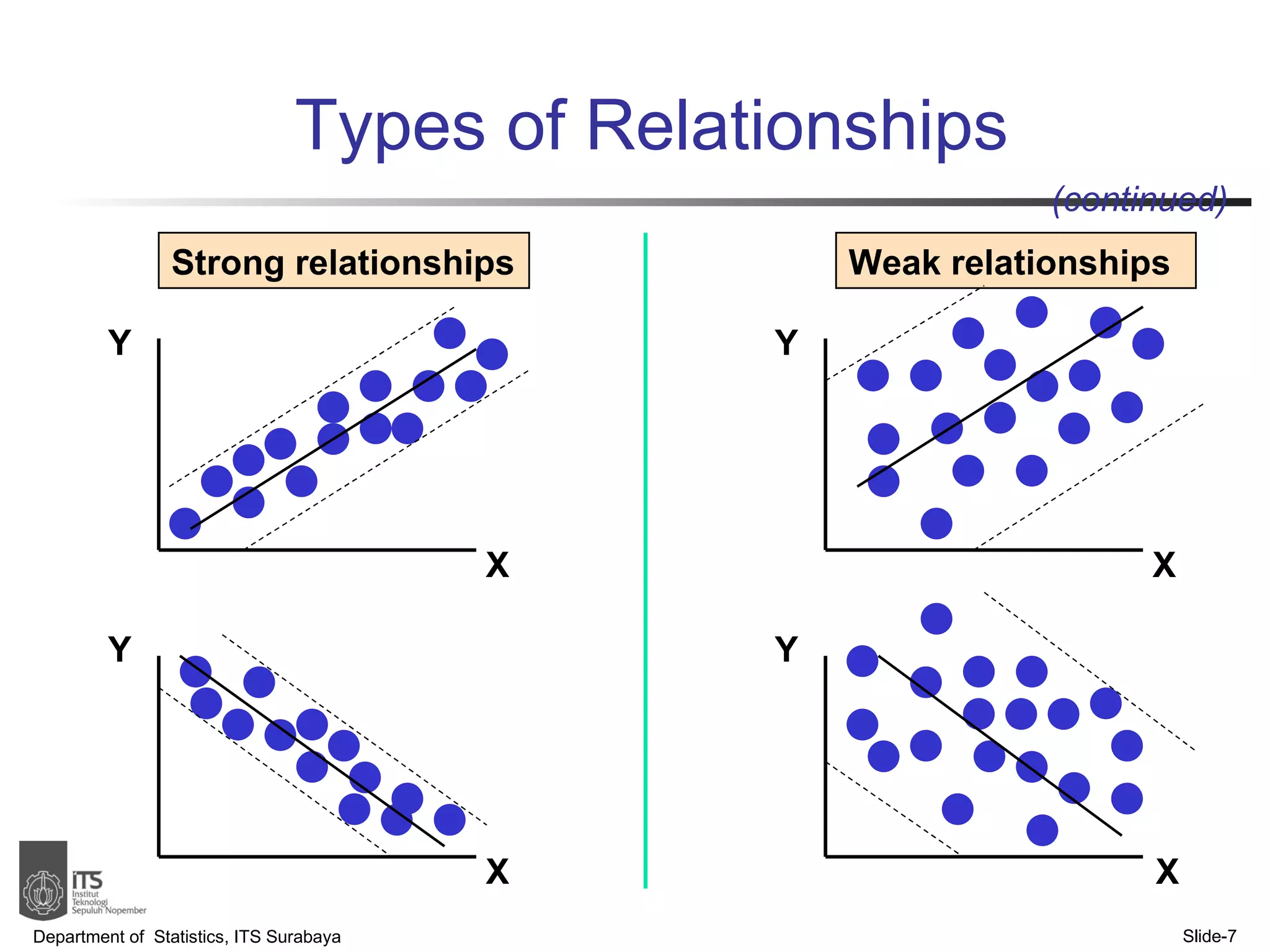
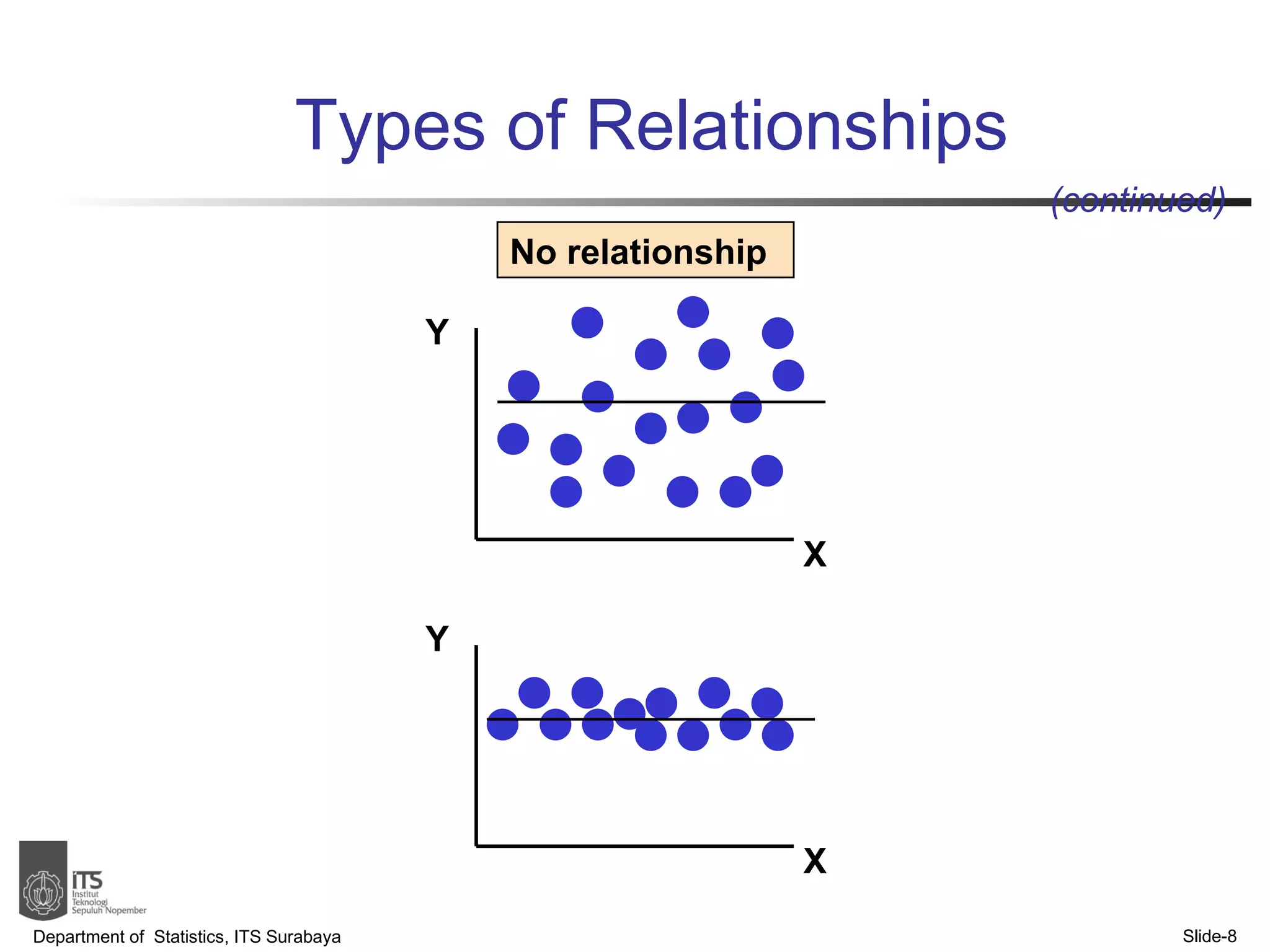
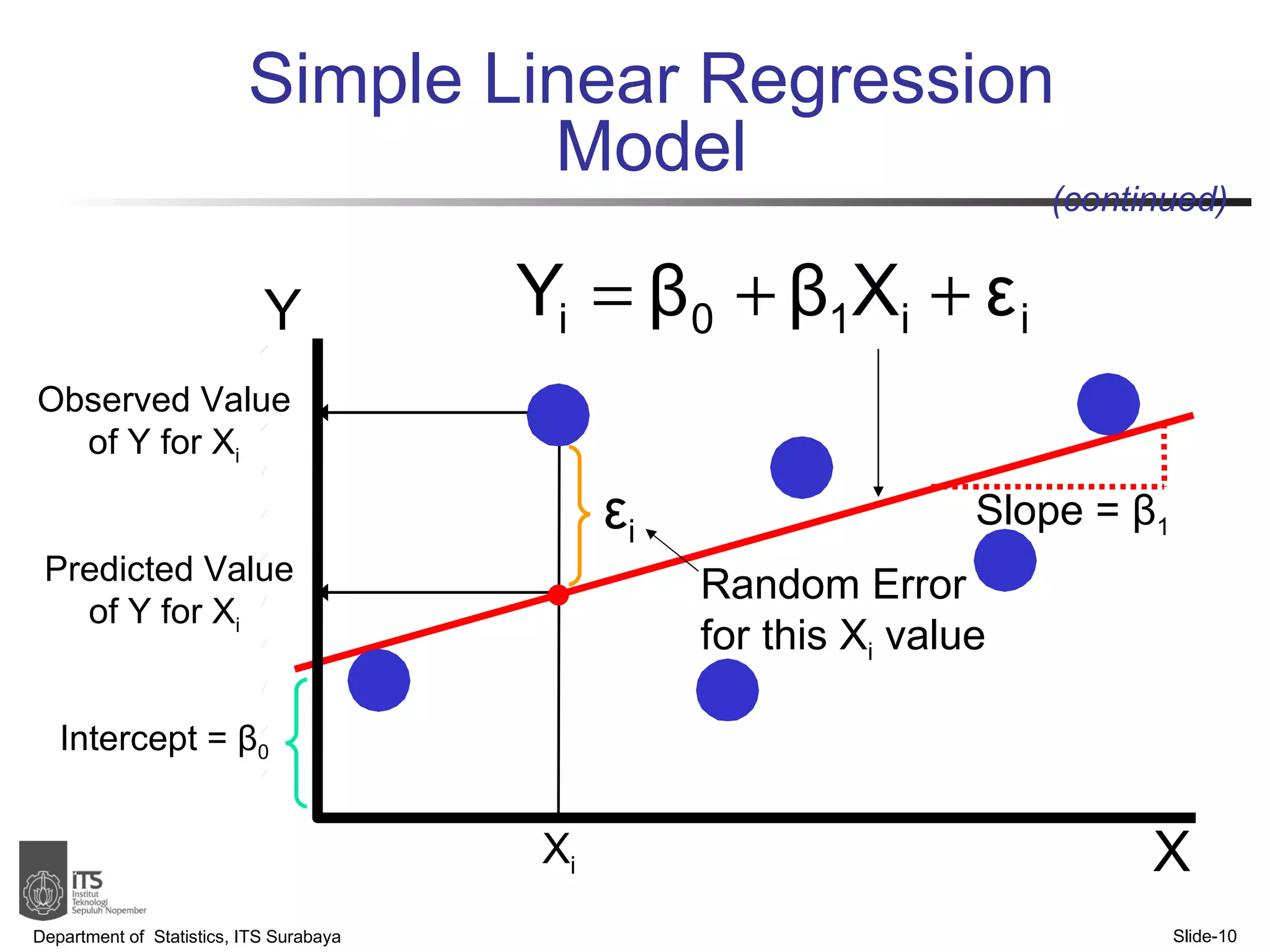
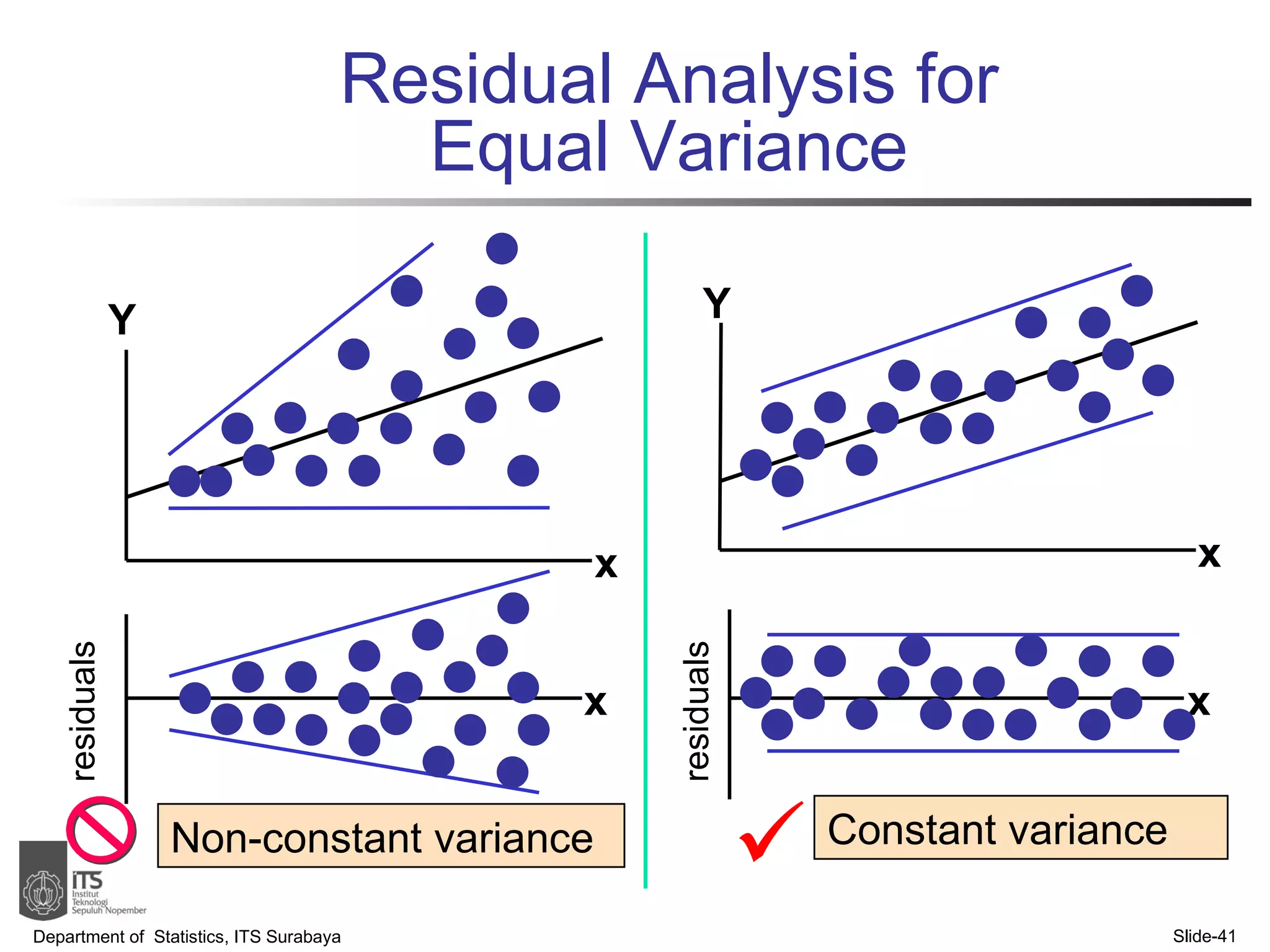
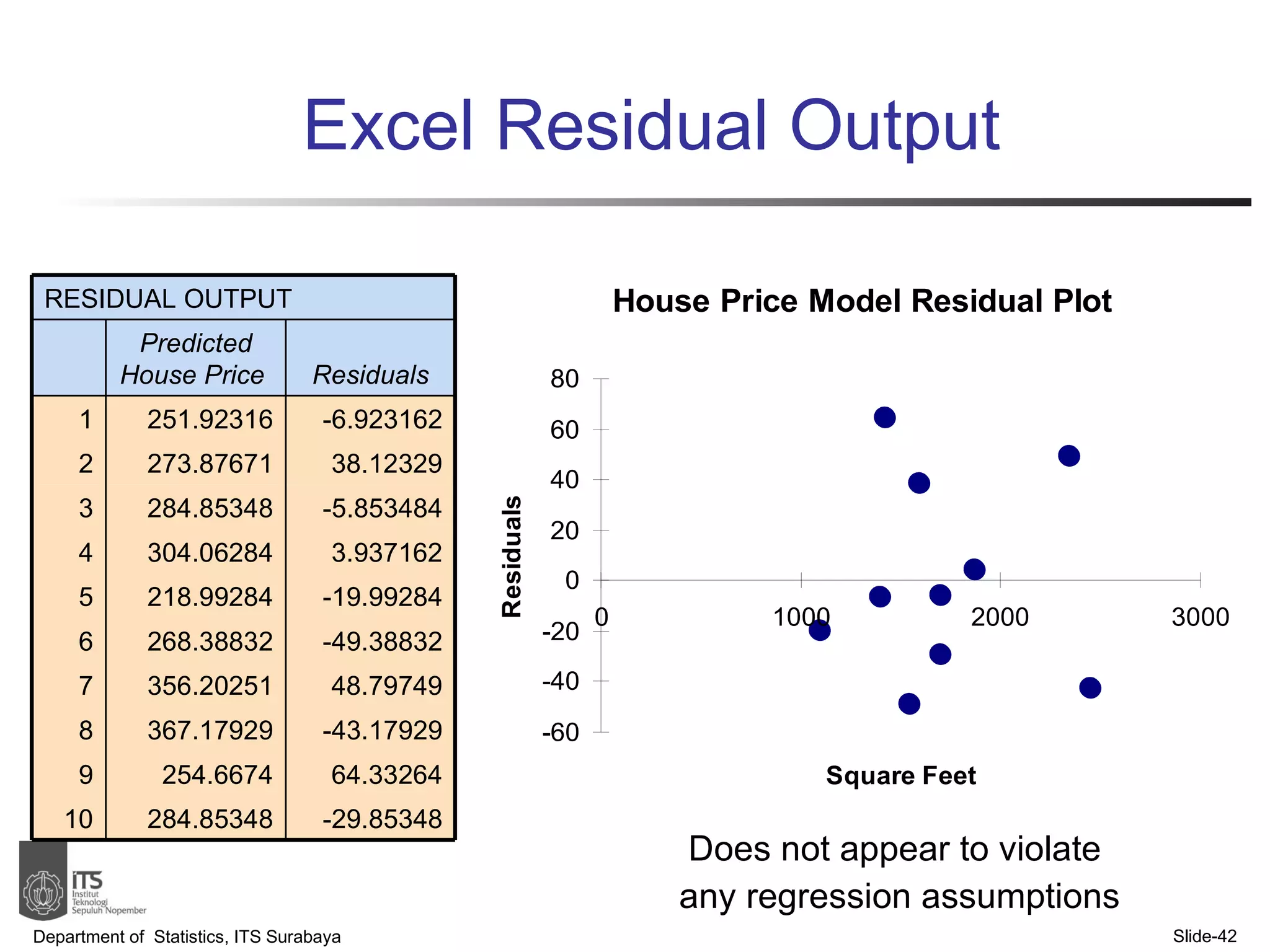
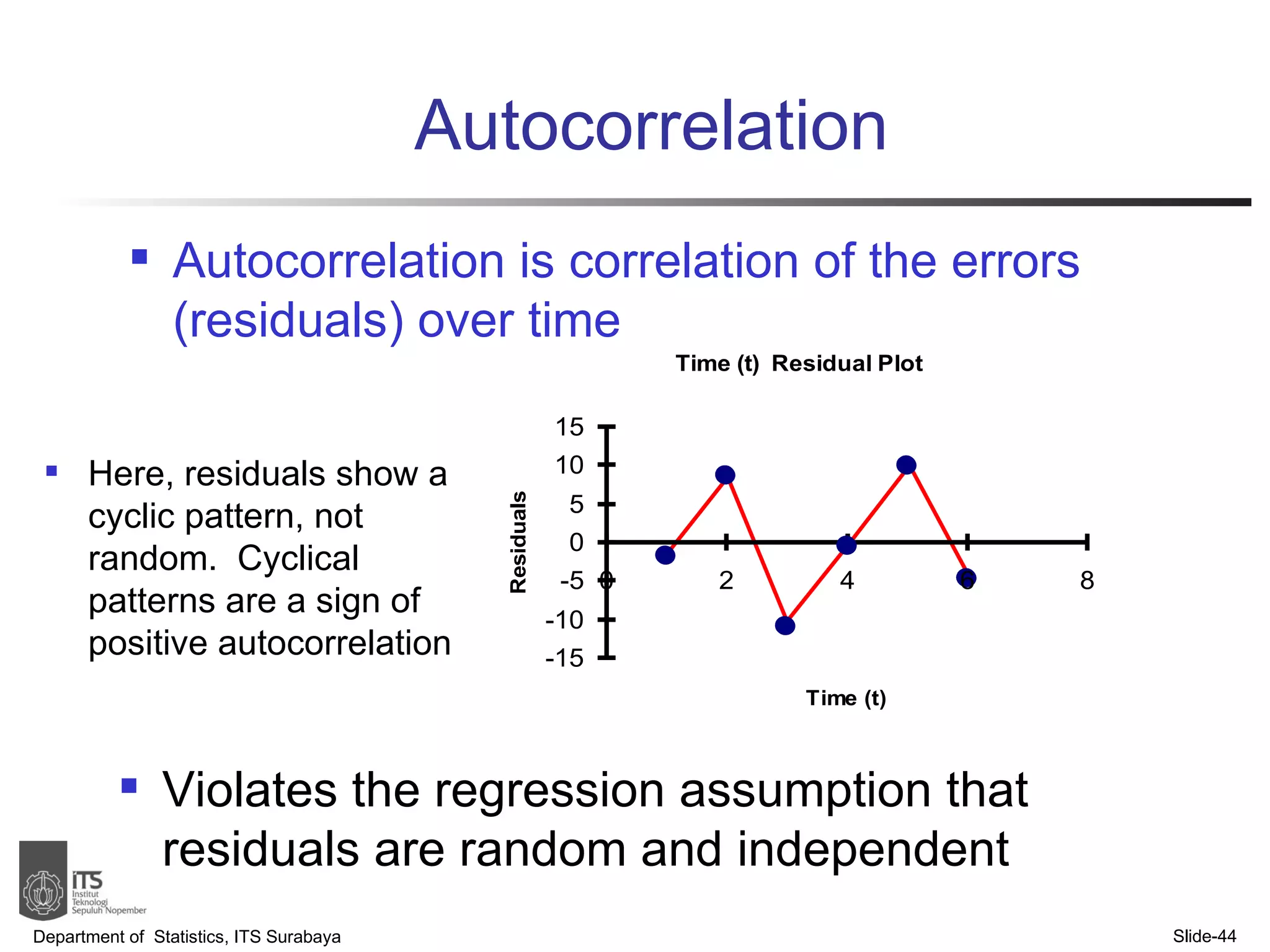
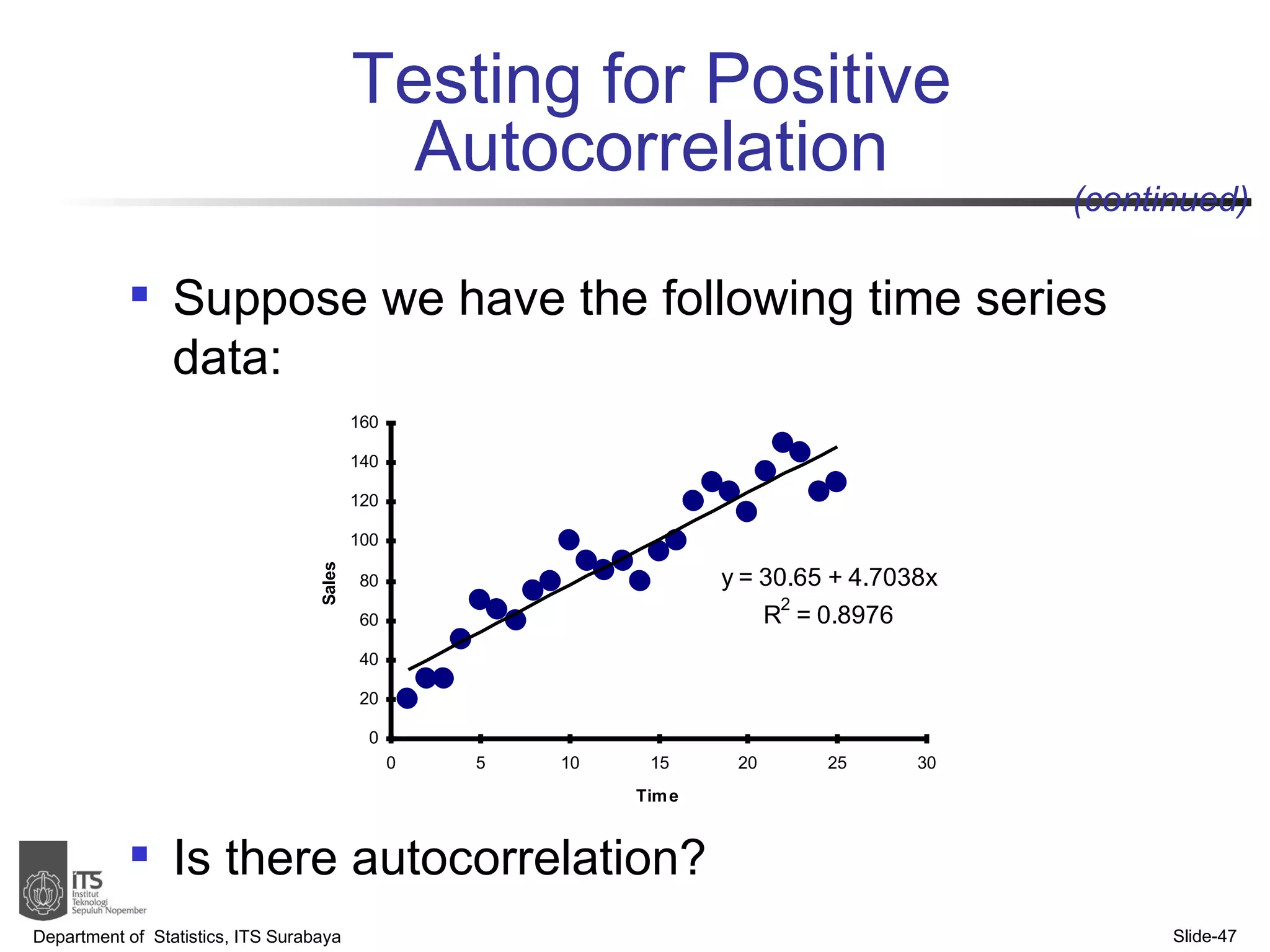
- The document discusses simple linear regression analysis and how to use it to predict a dependent variable (y) based on an independent variable (x).
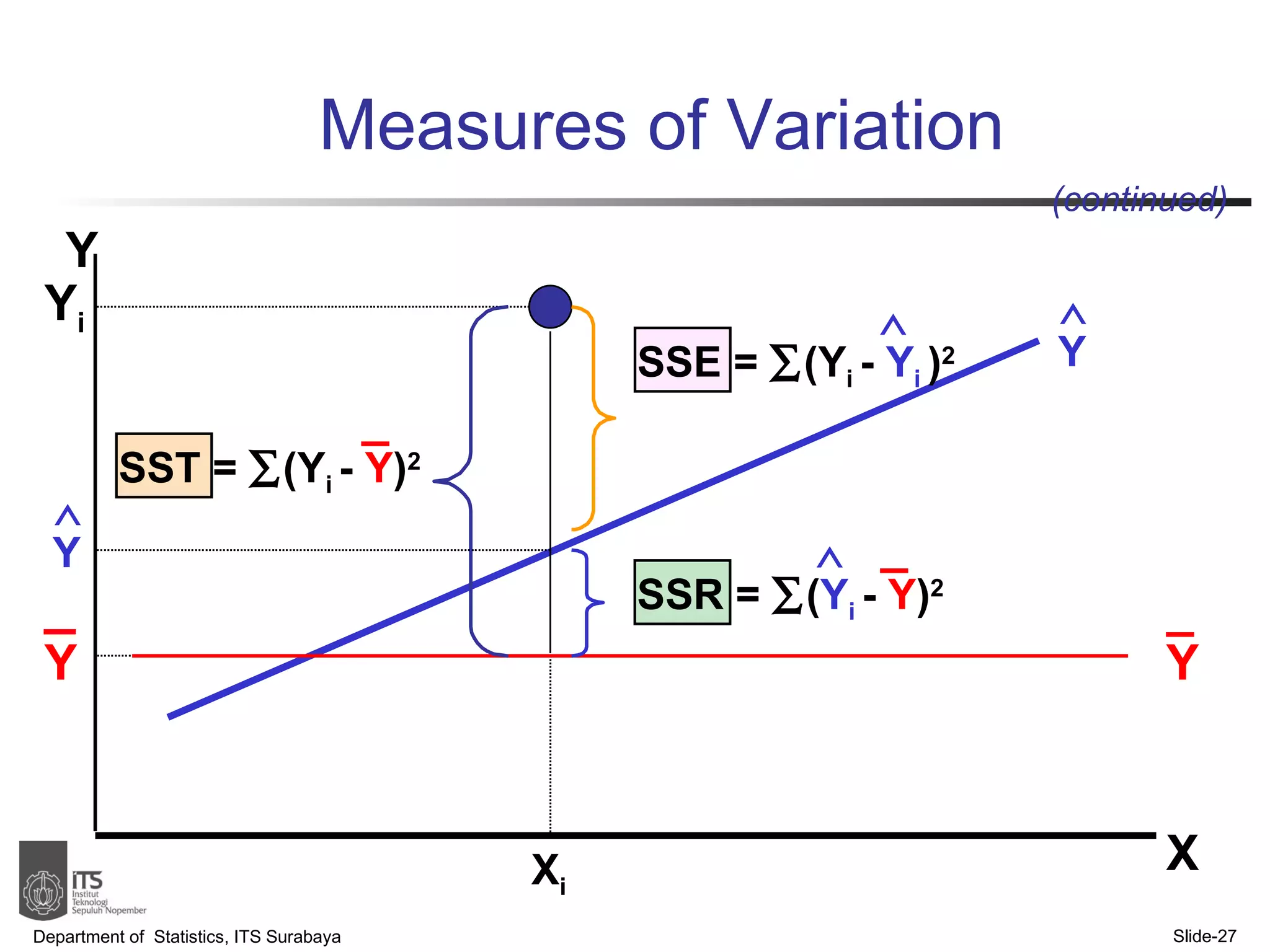
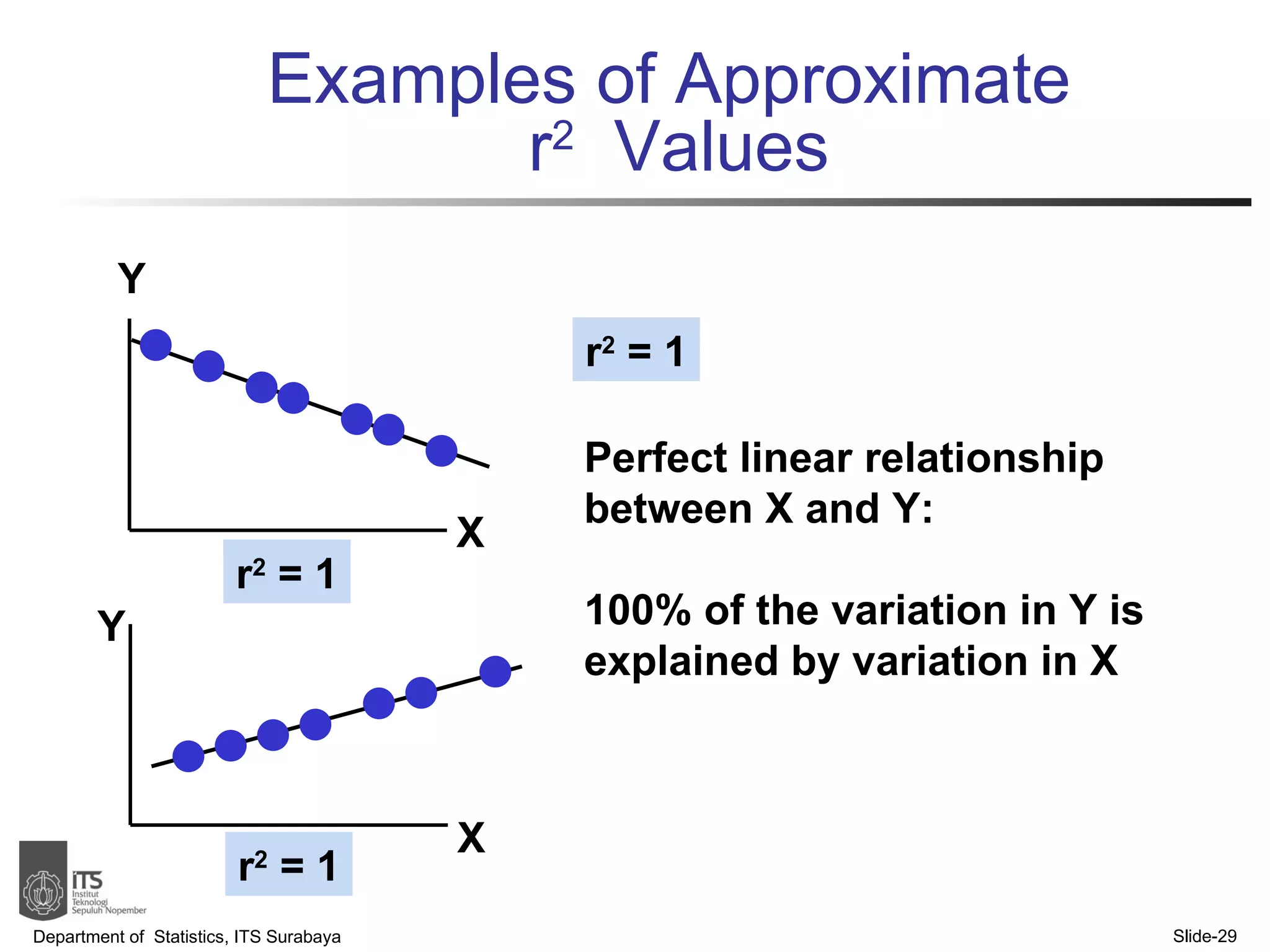
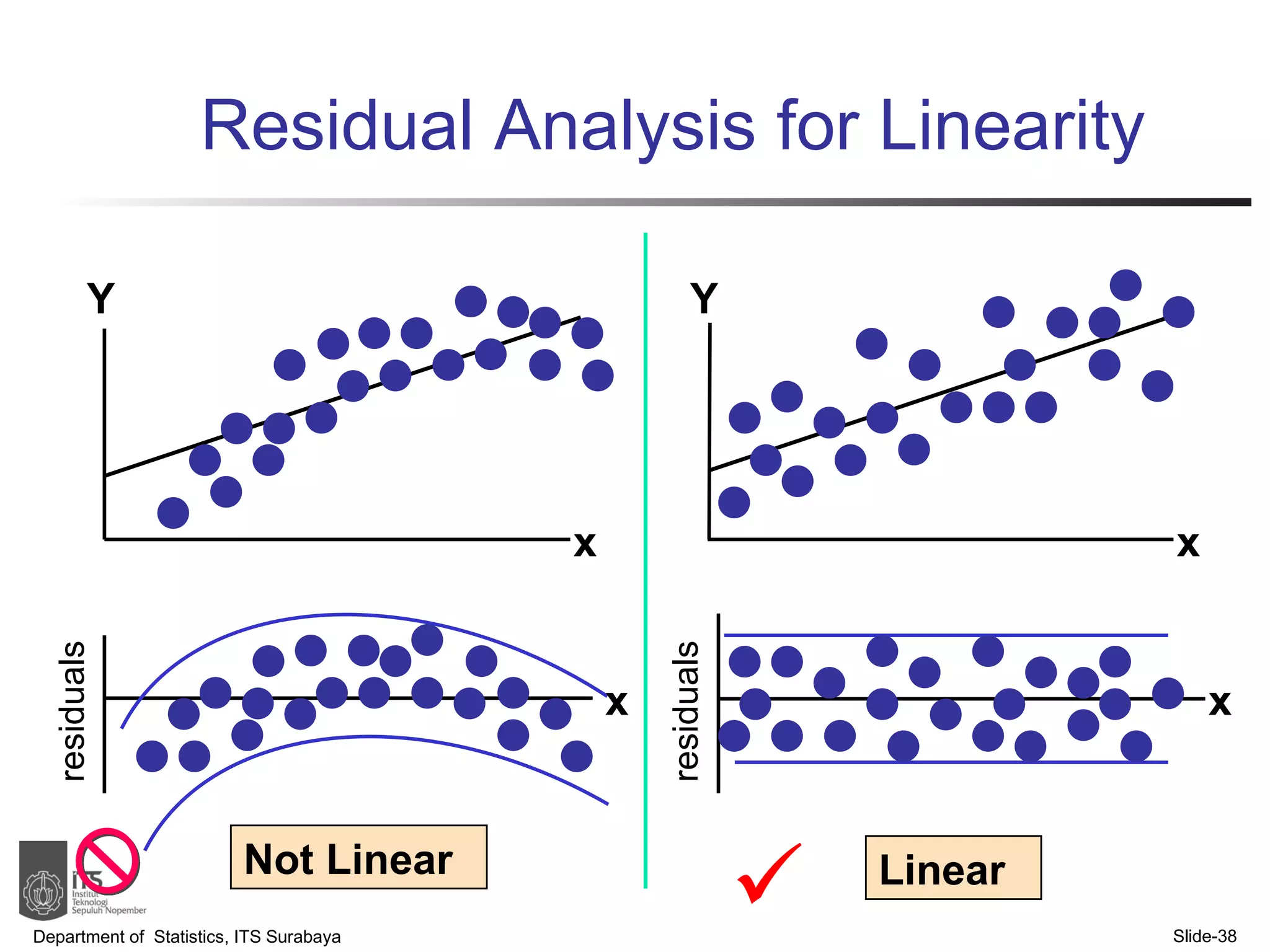
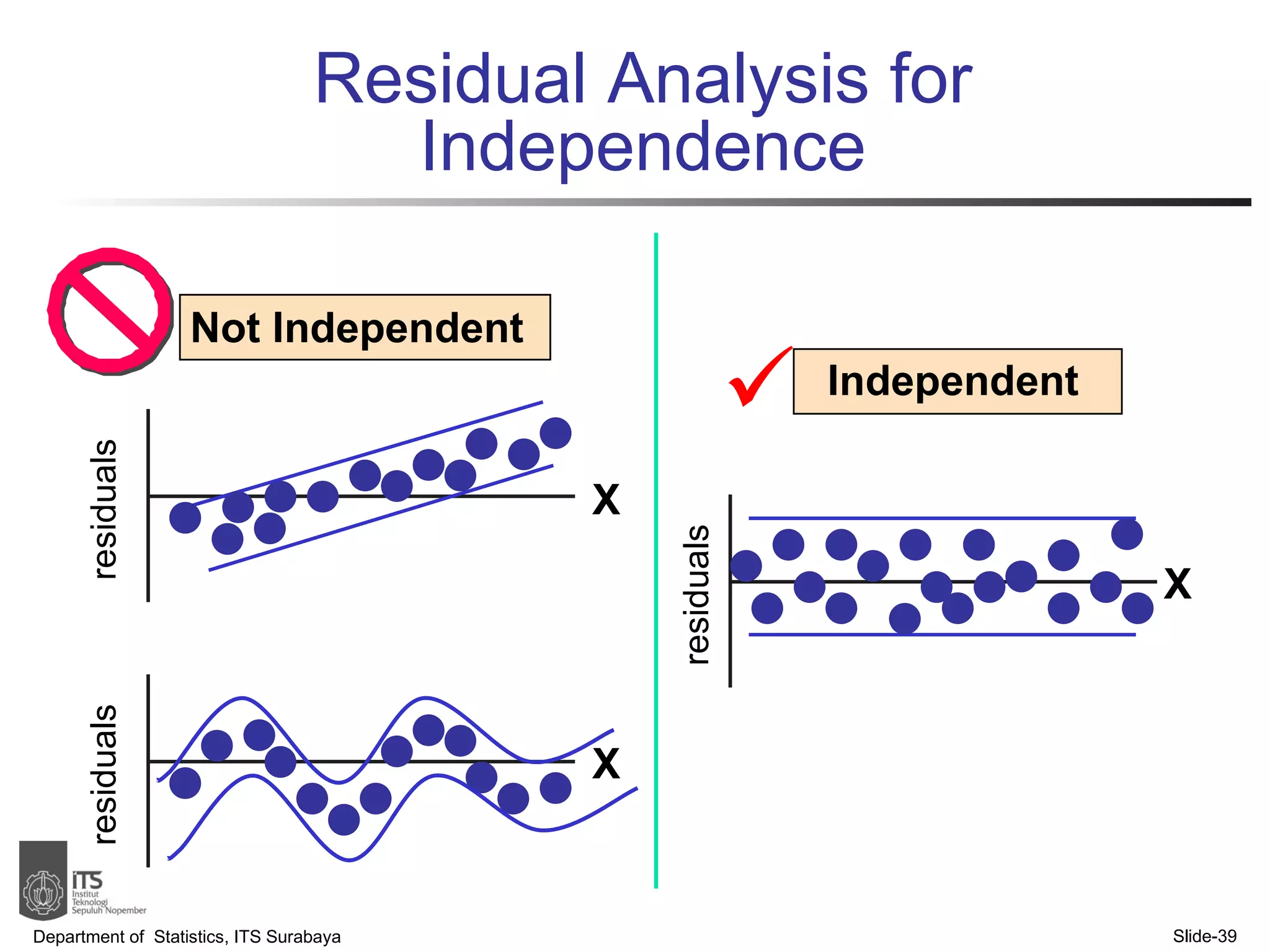
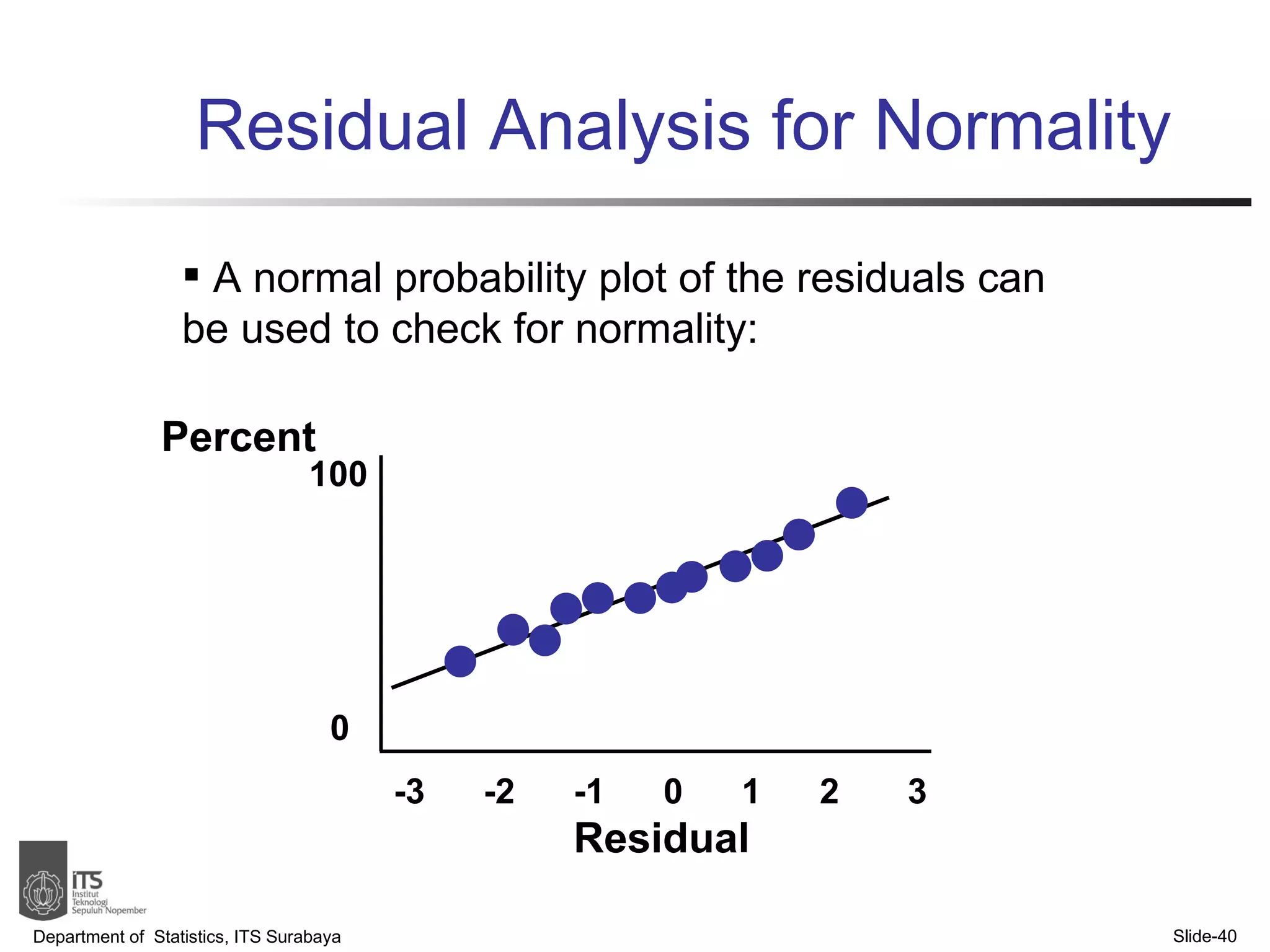
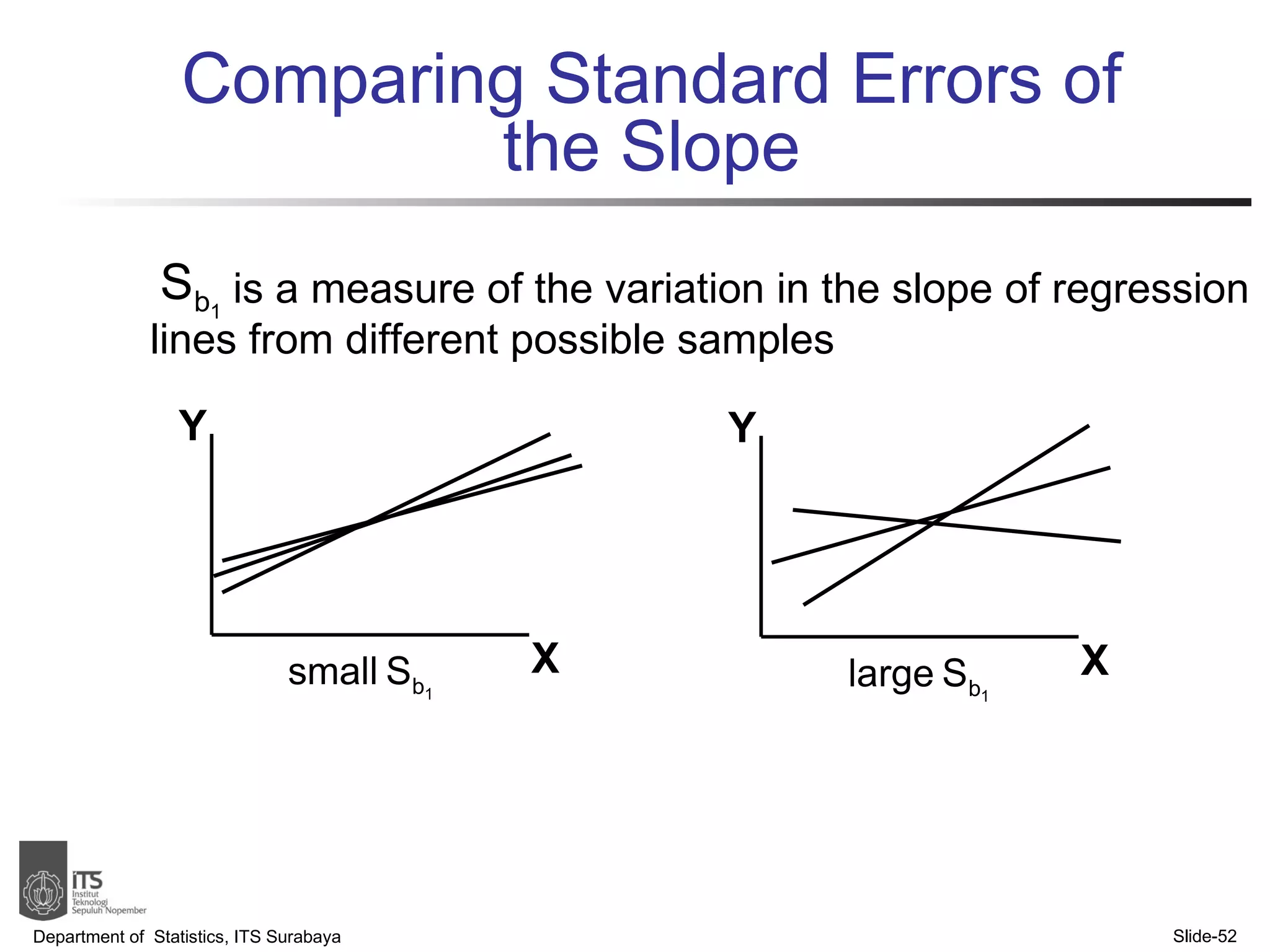
- Key points covered include the simple linear regression model, estimating regression coefficients, evaluating assumptions, making predictions, and interpreting results.
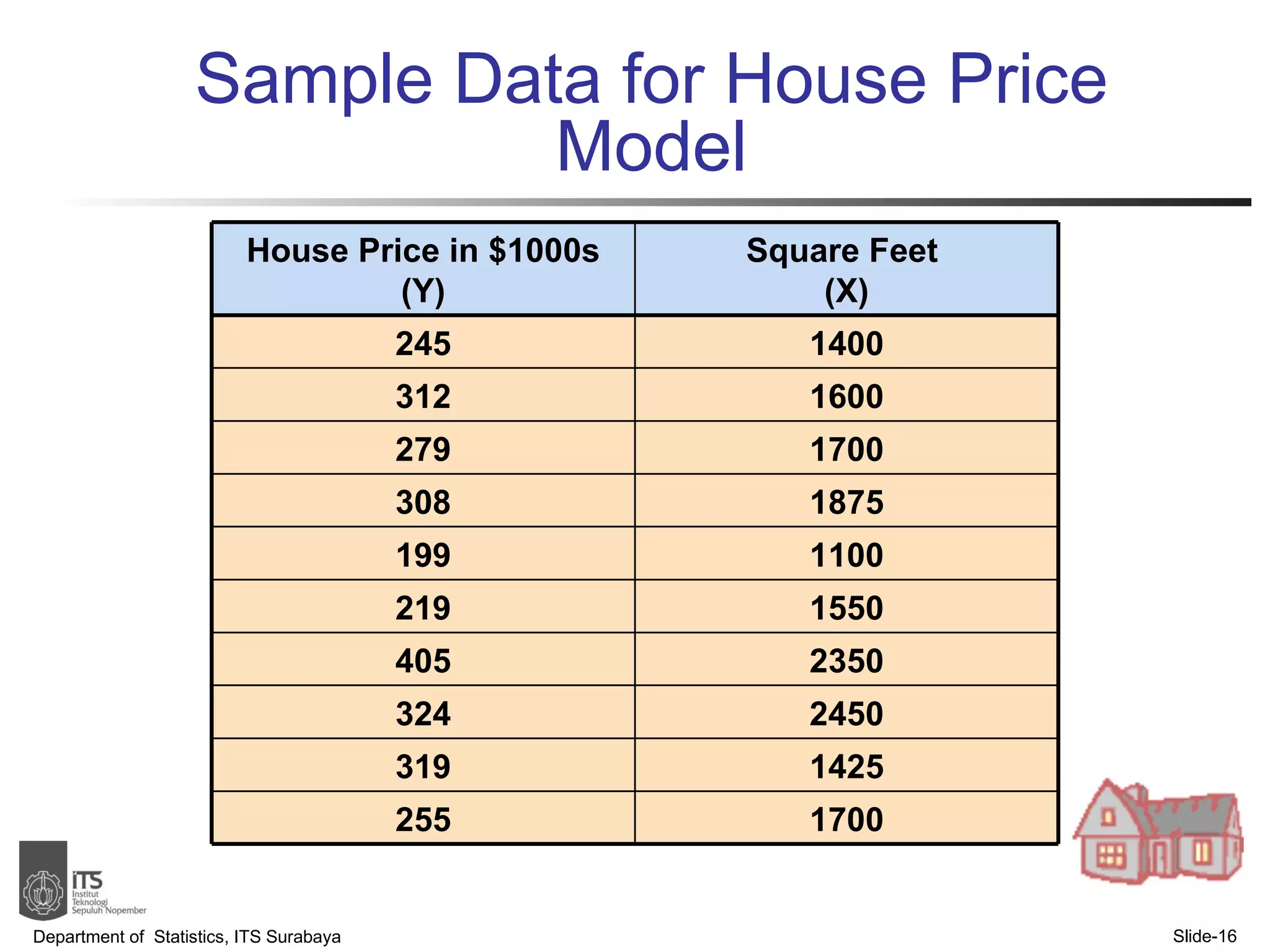
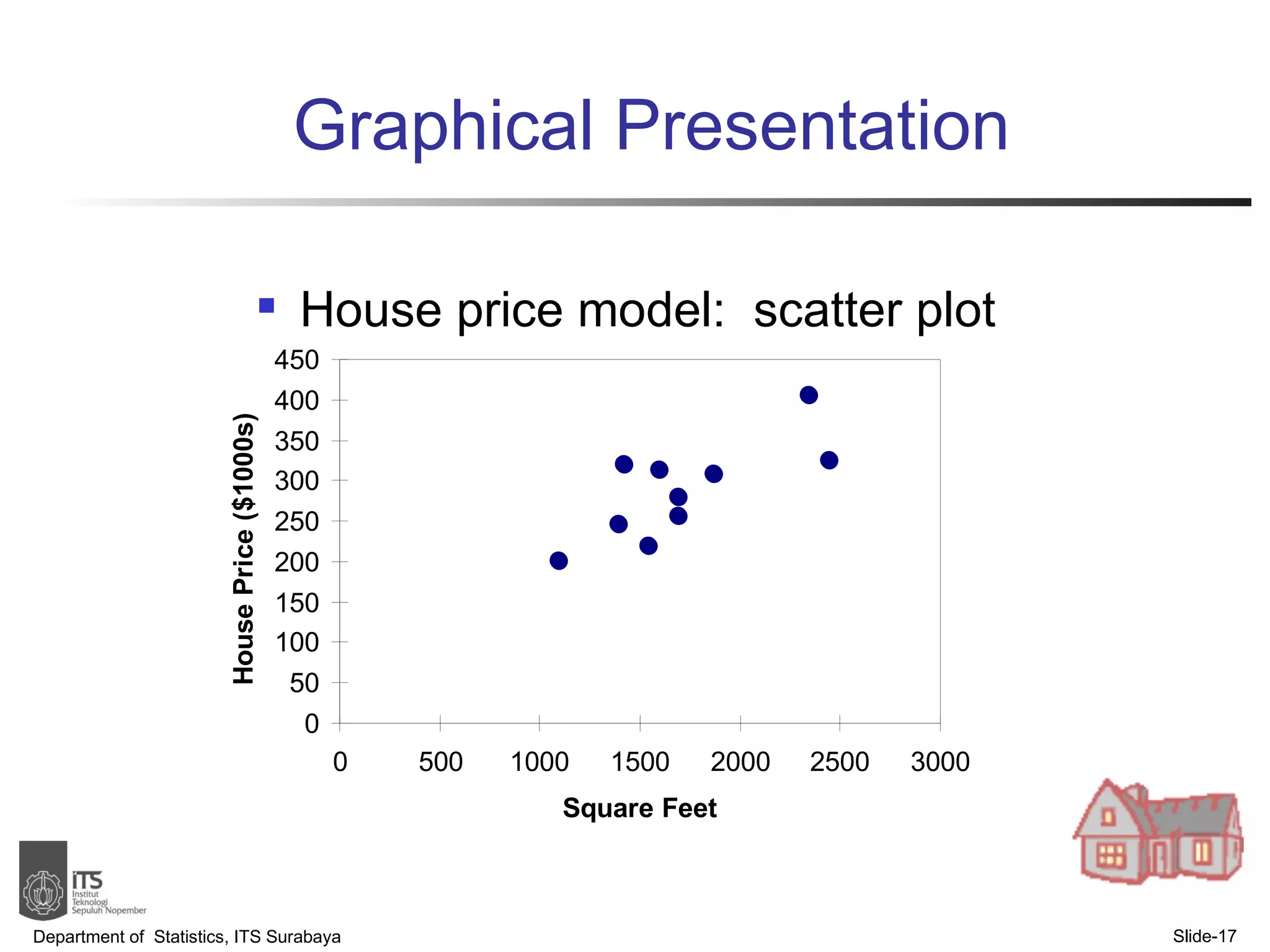
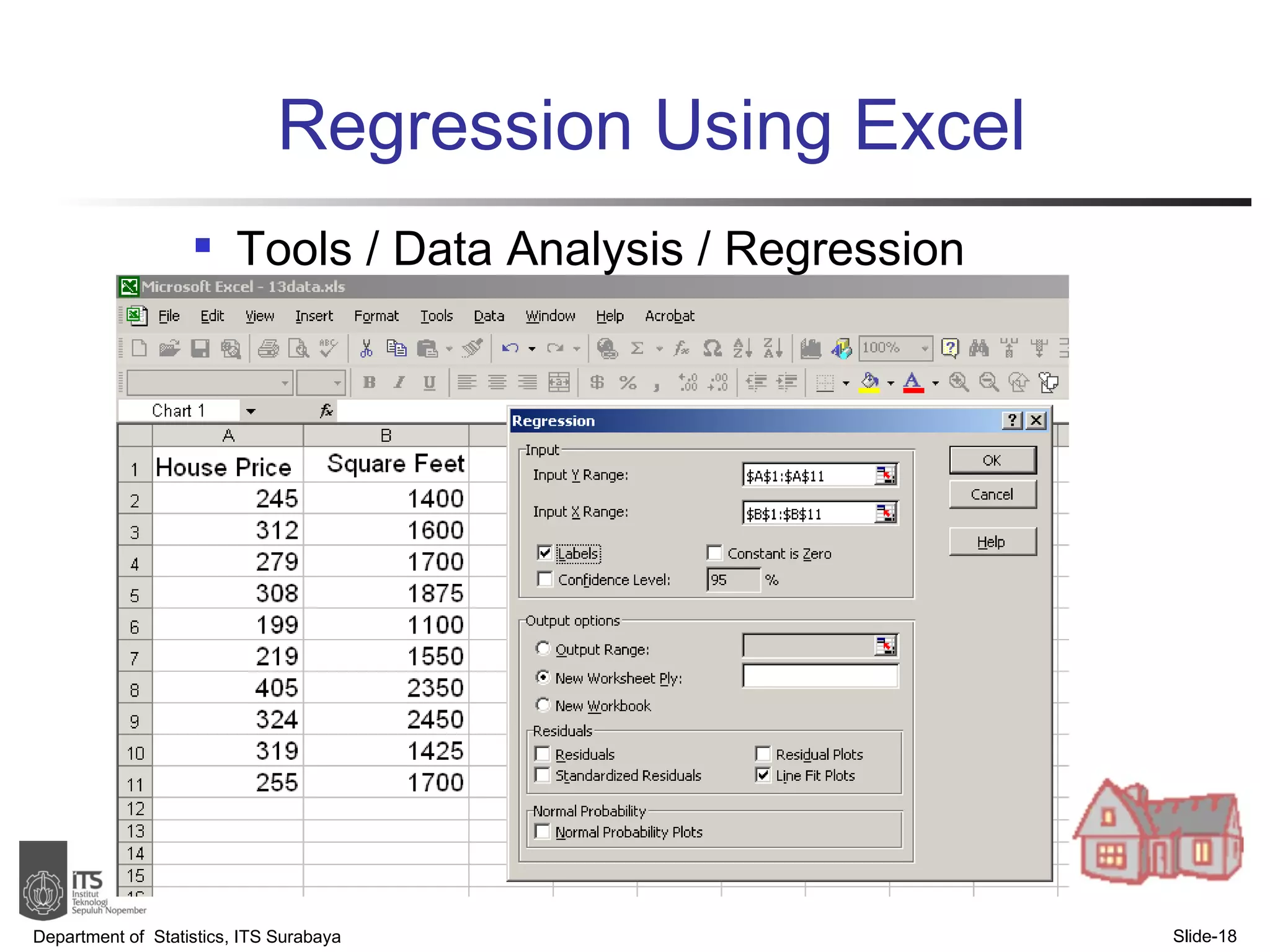
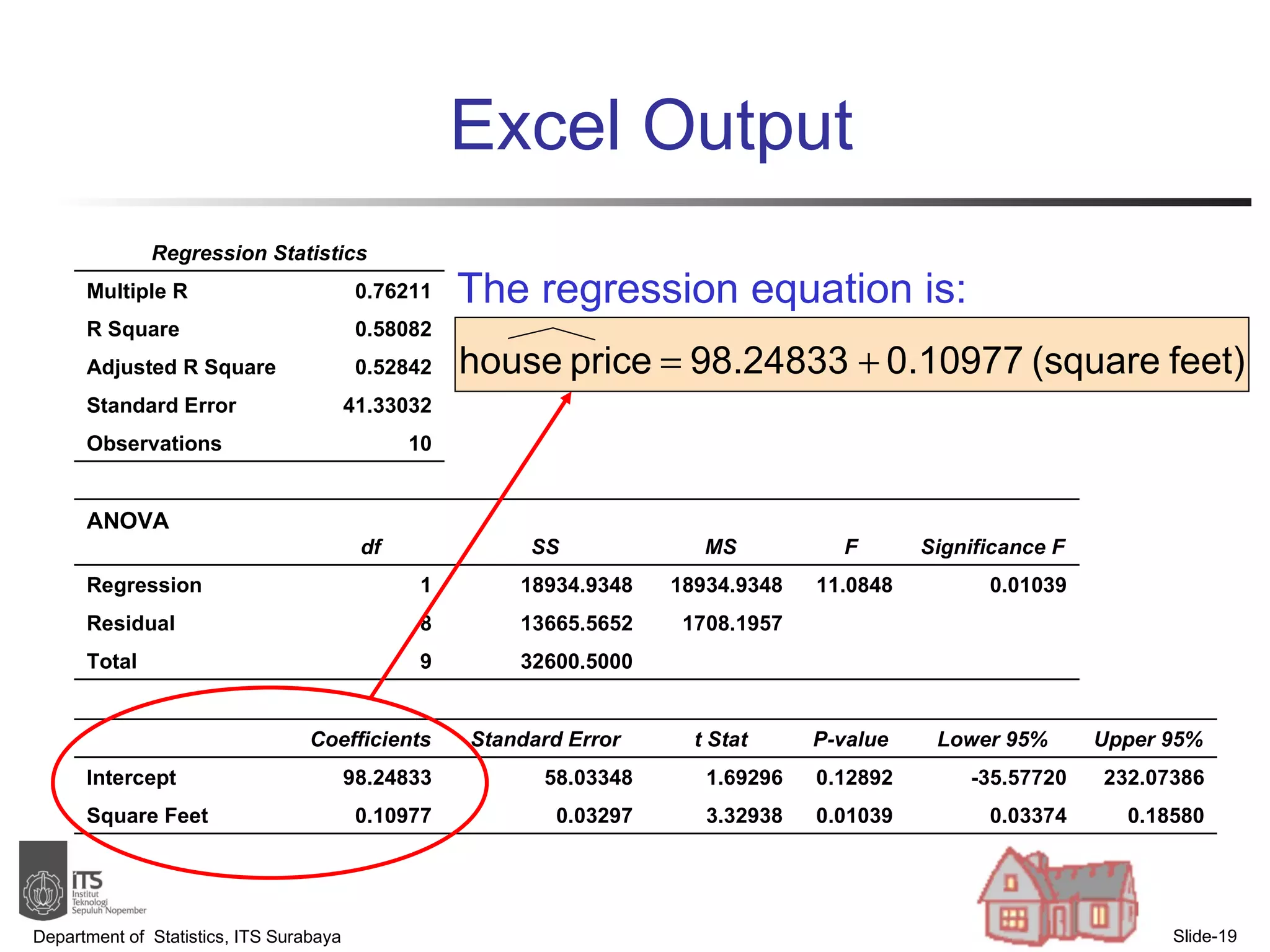
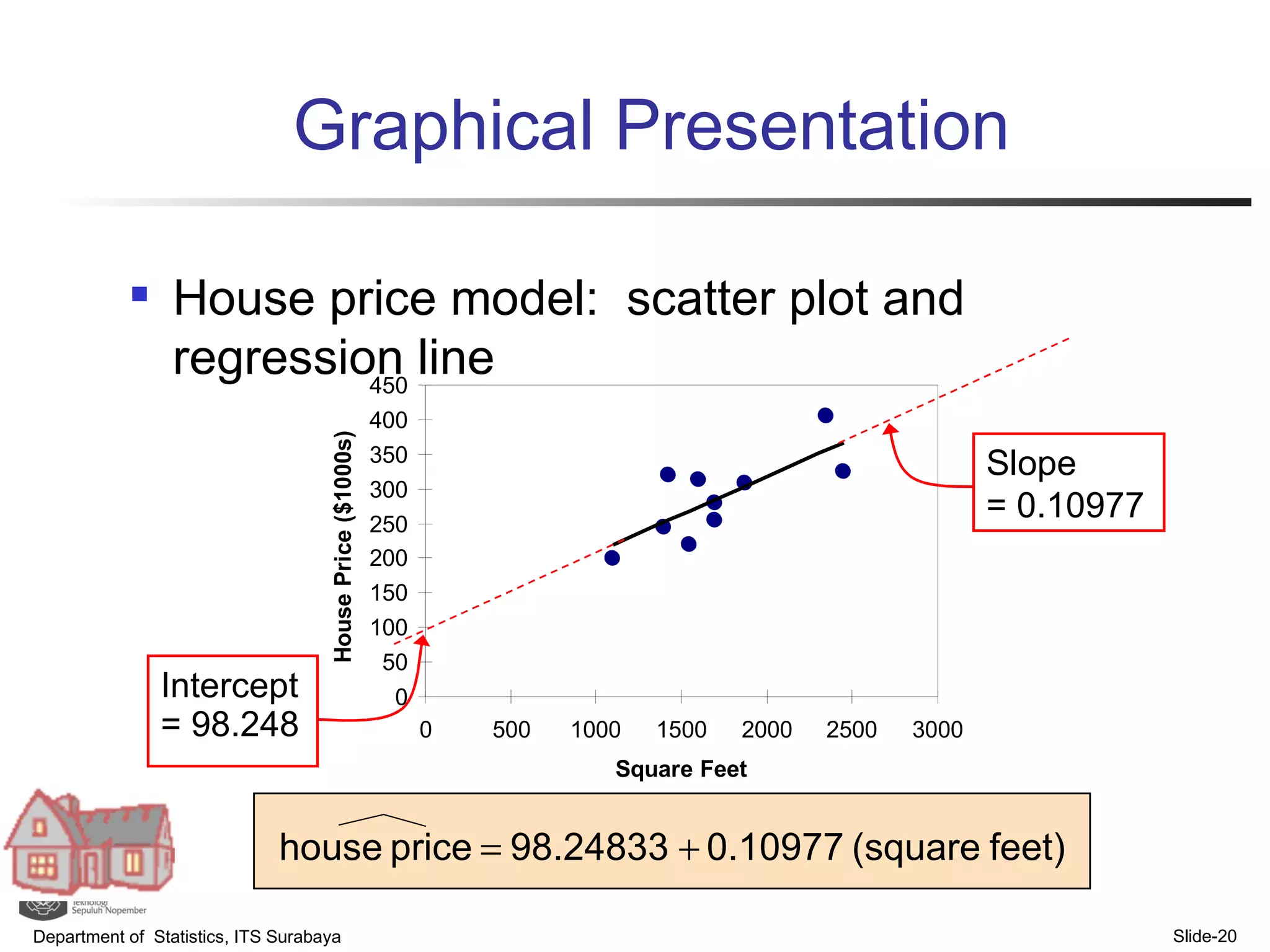
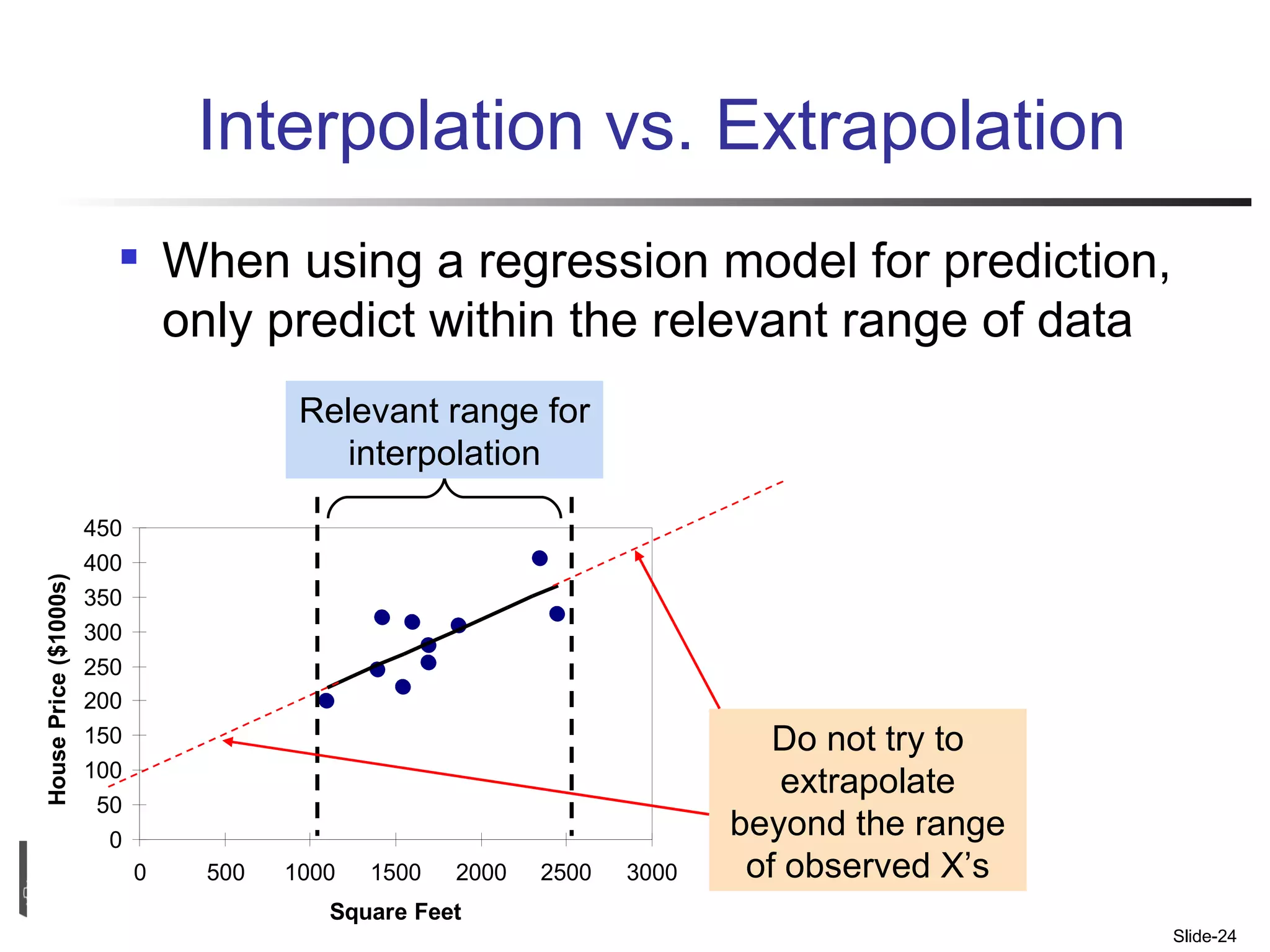
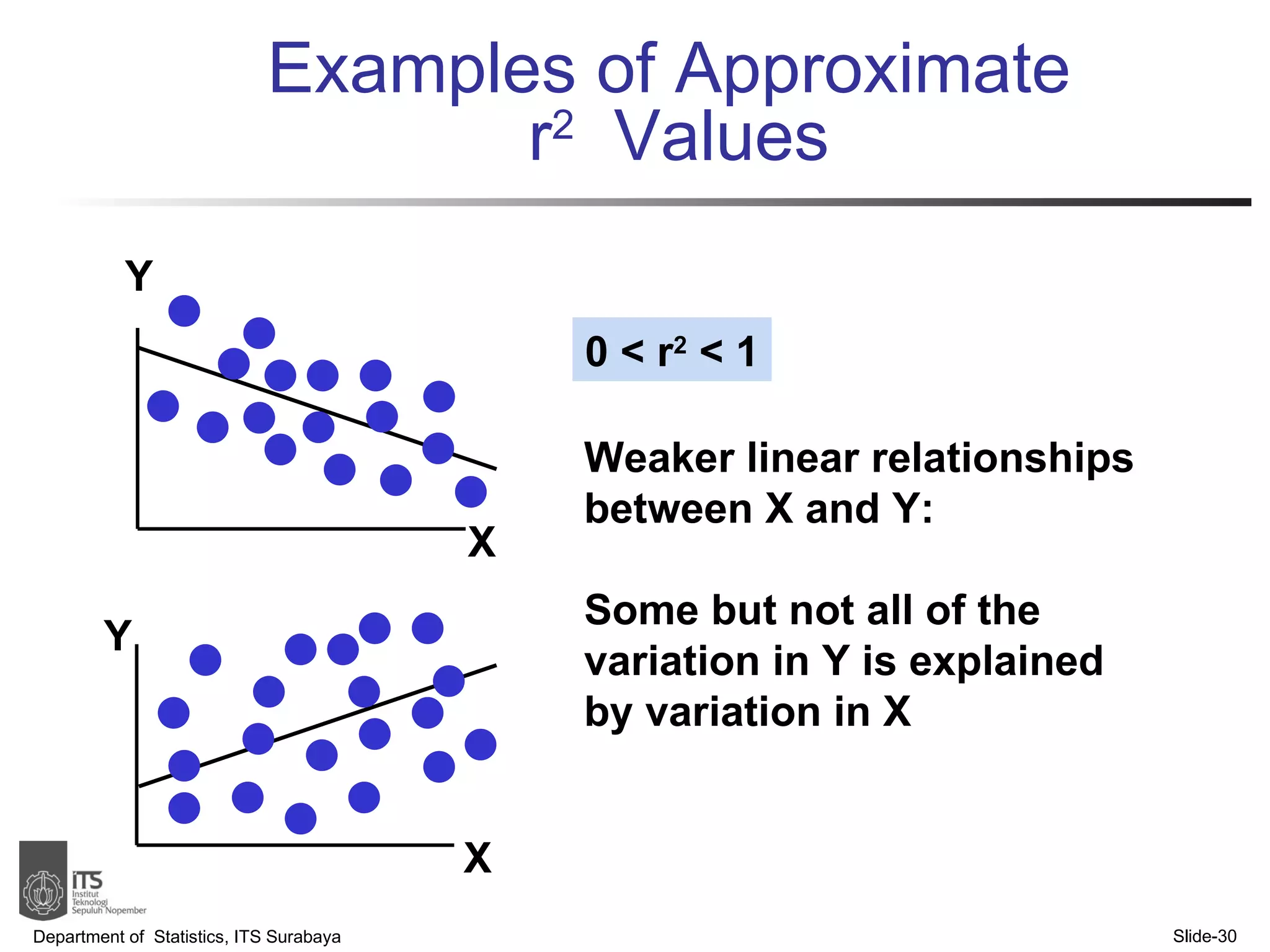
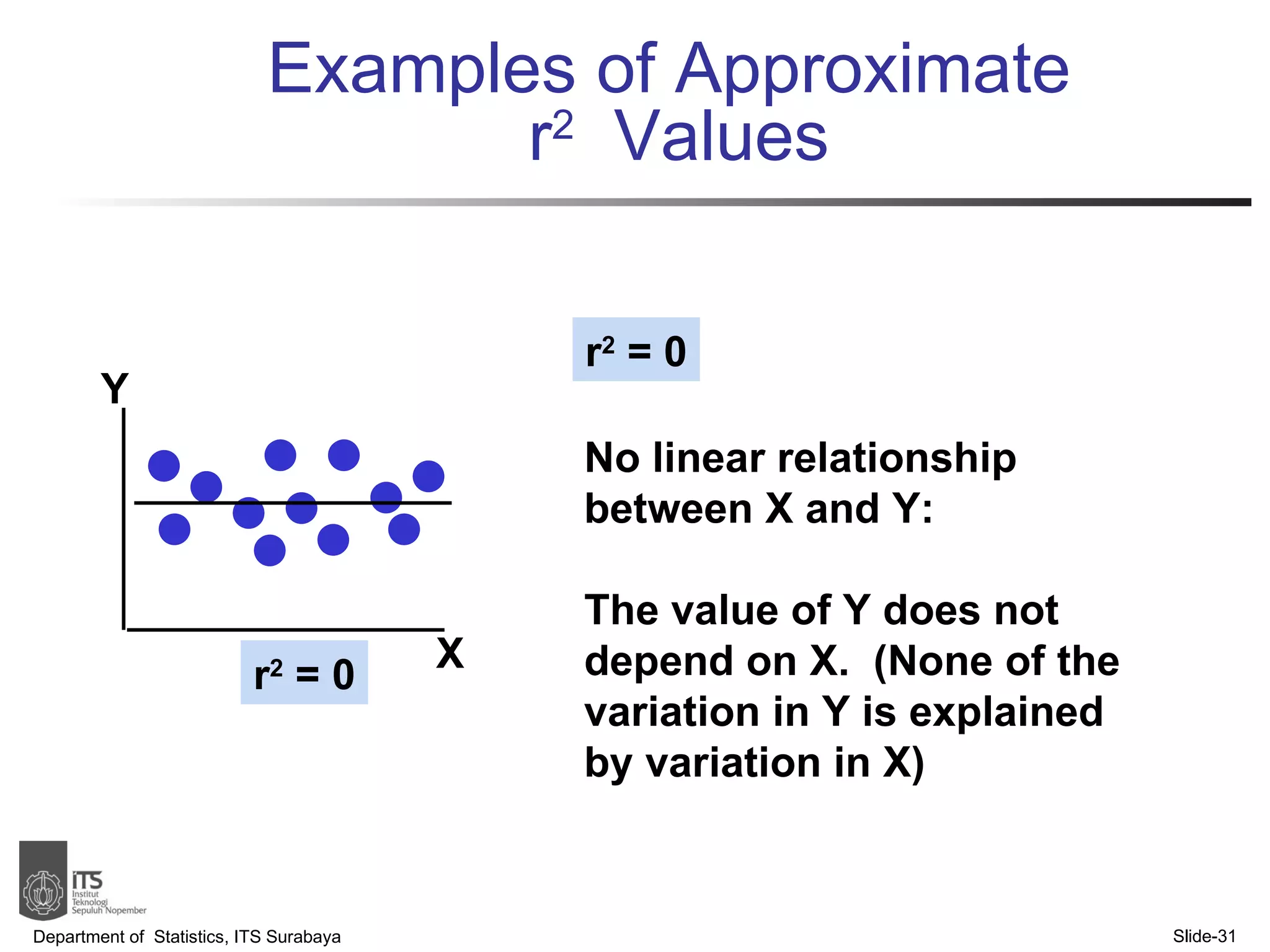
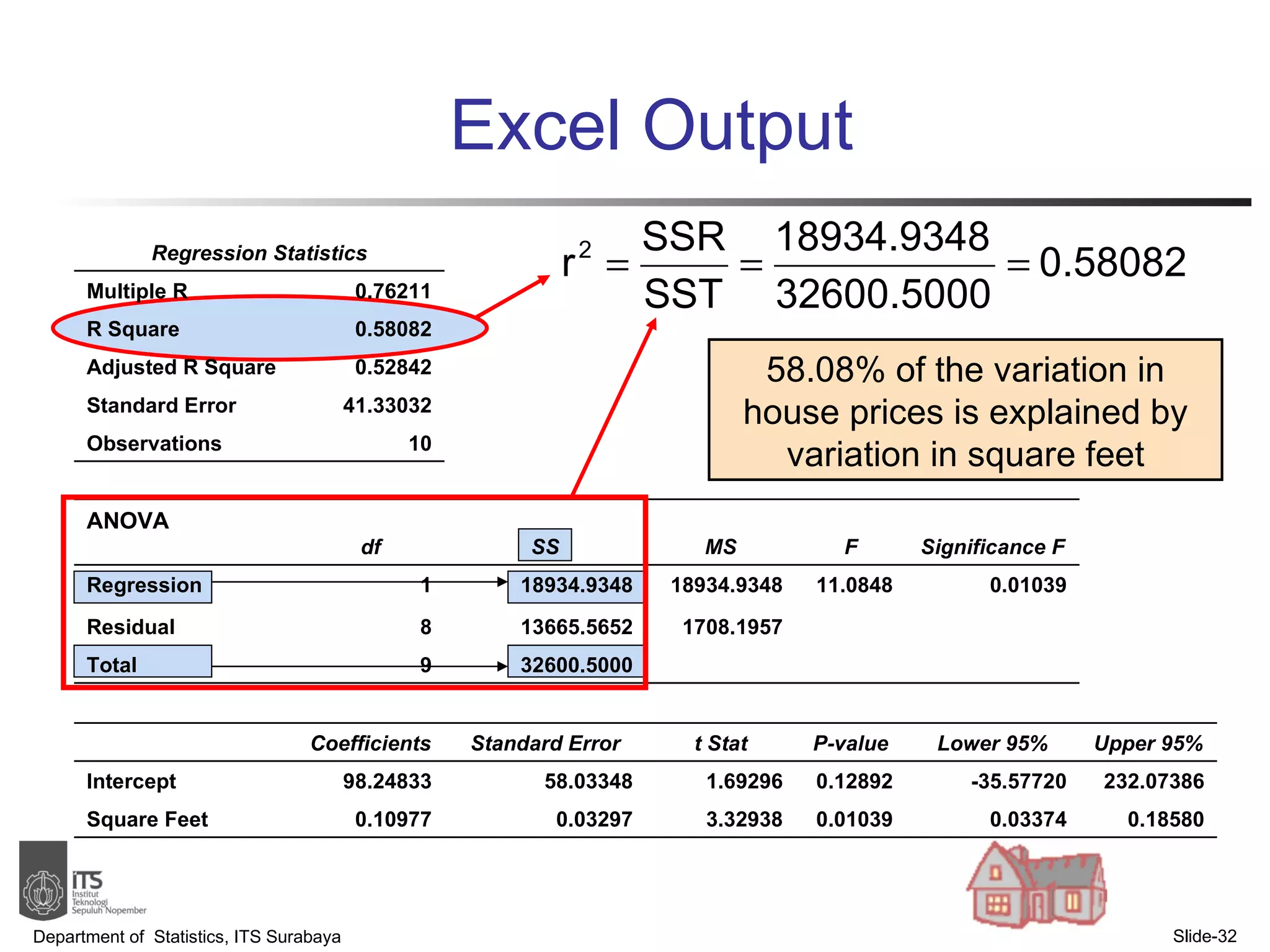
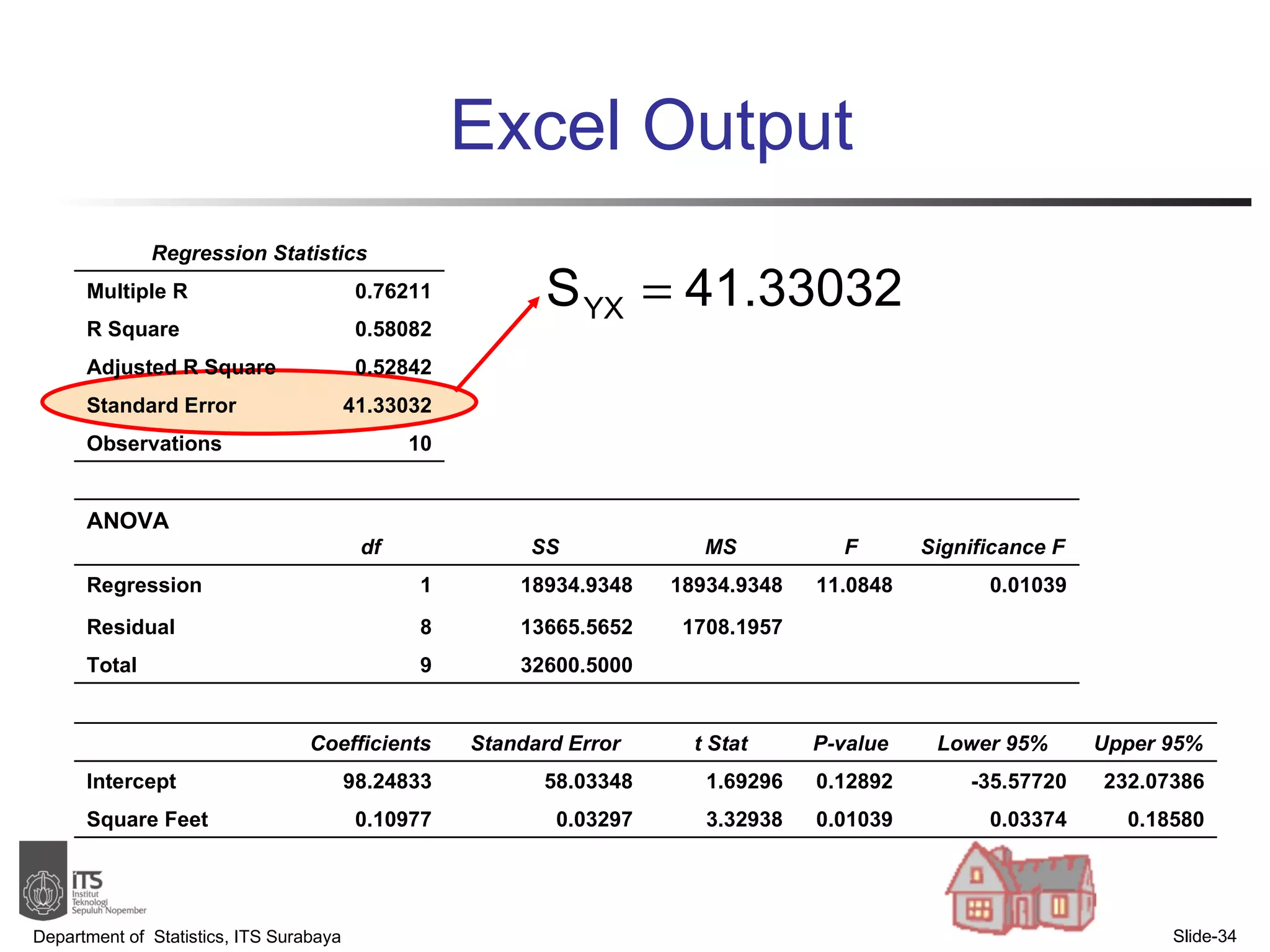
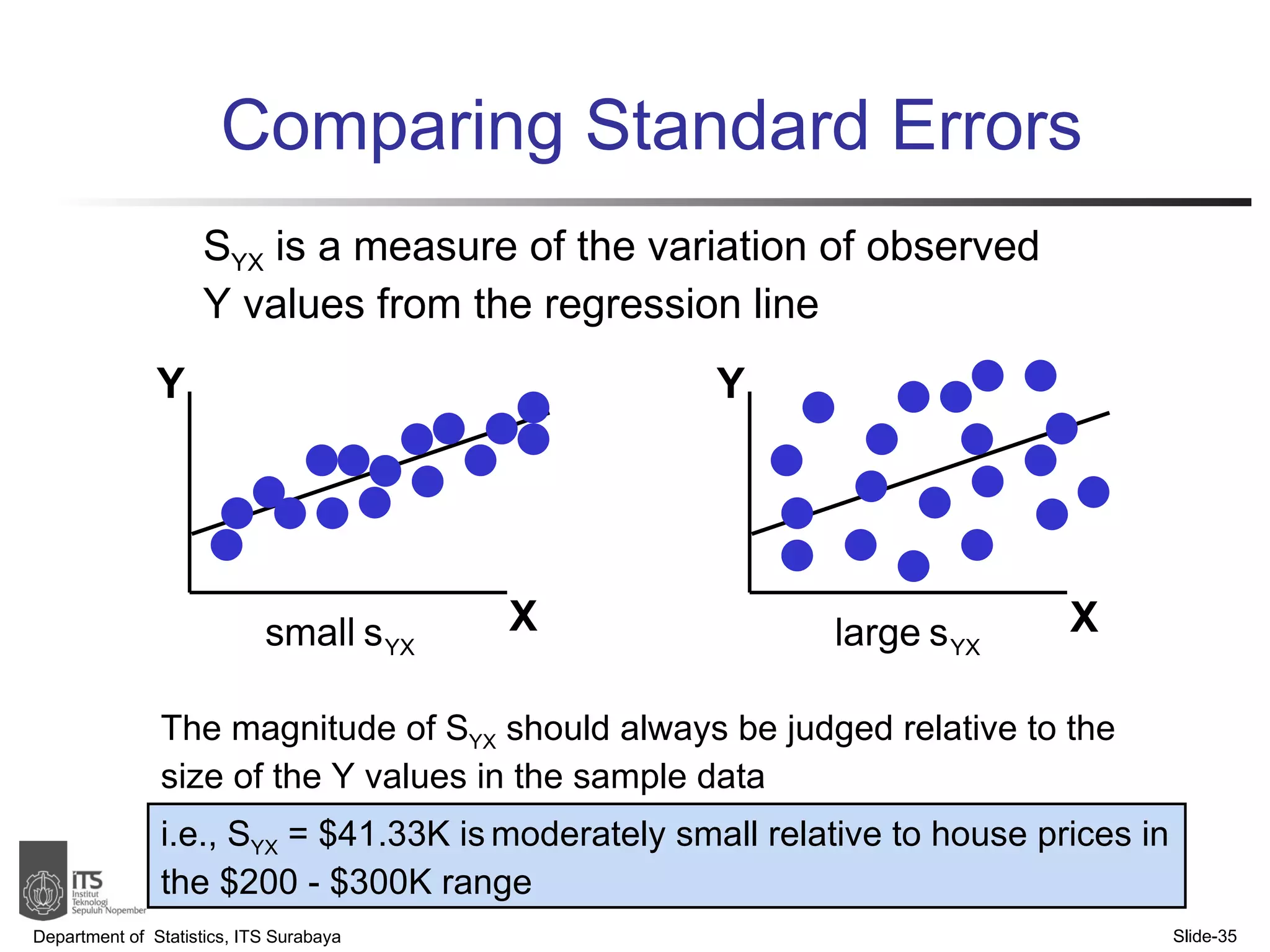
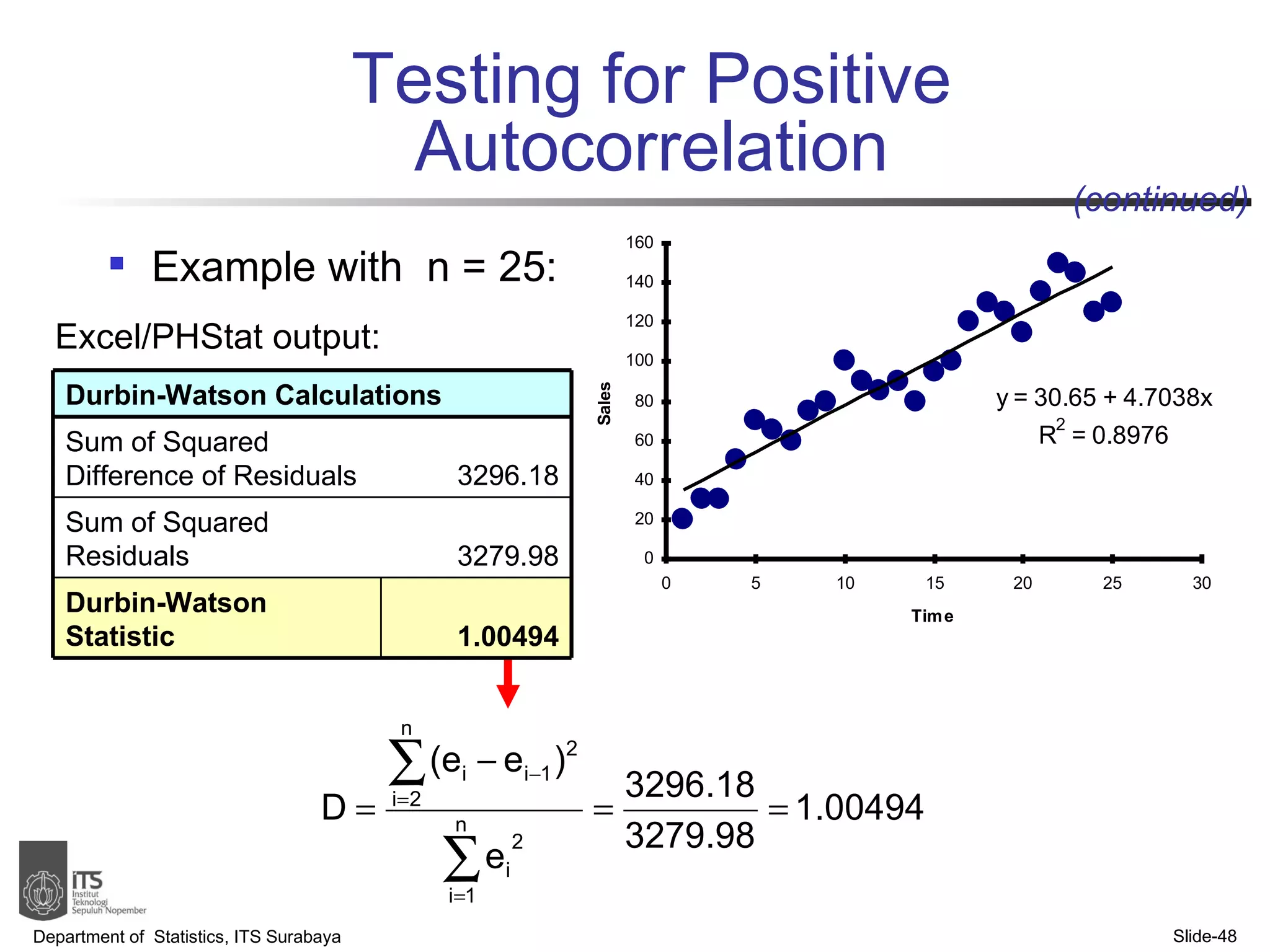
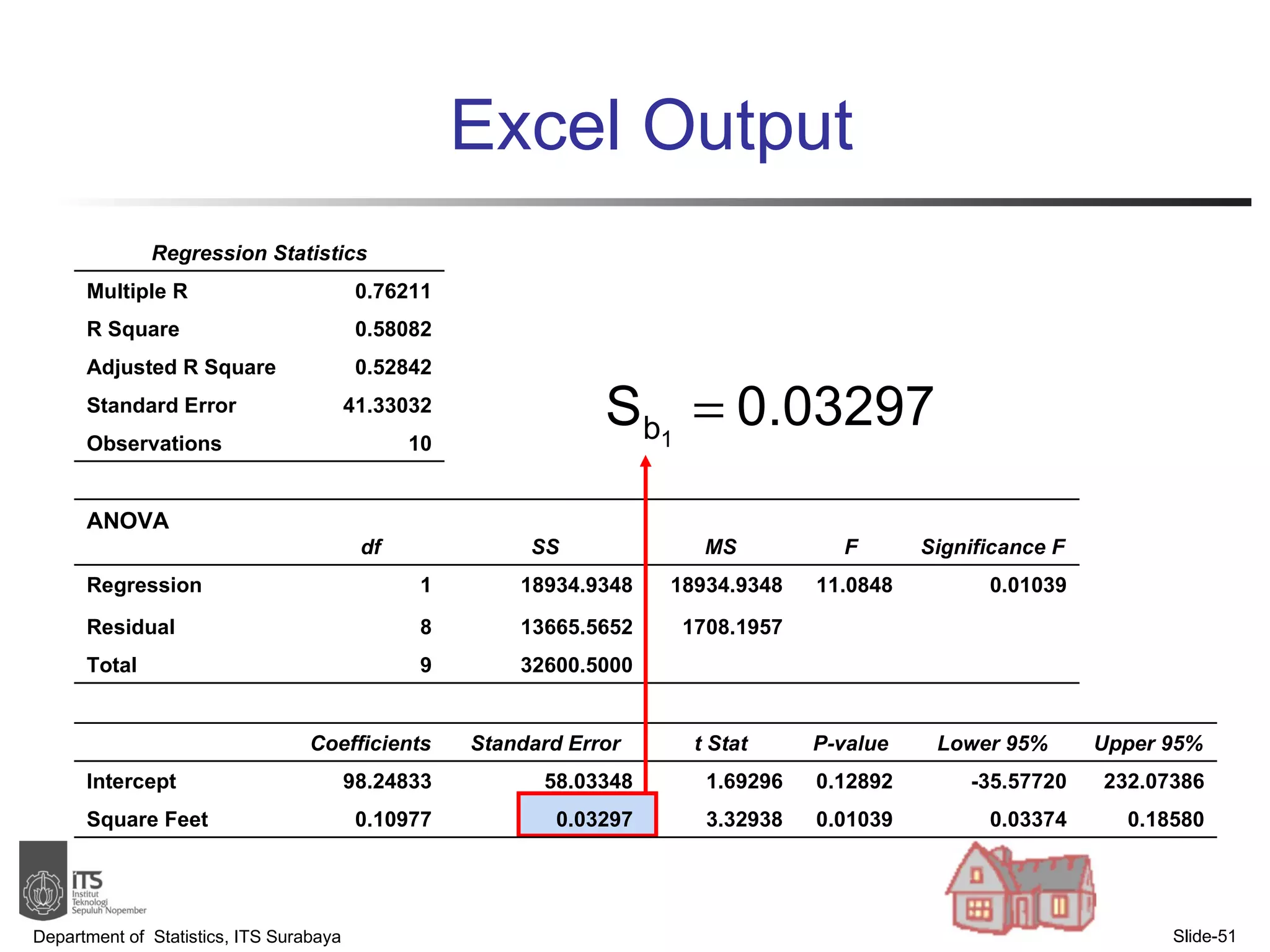
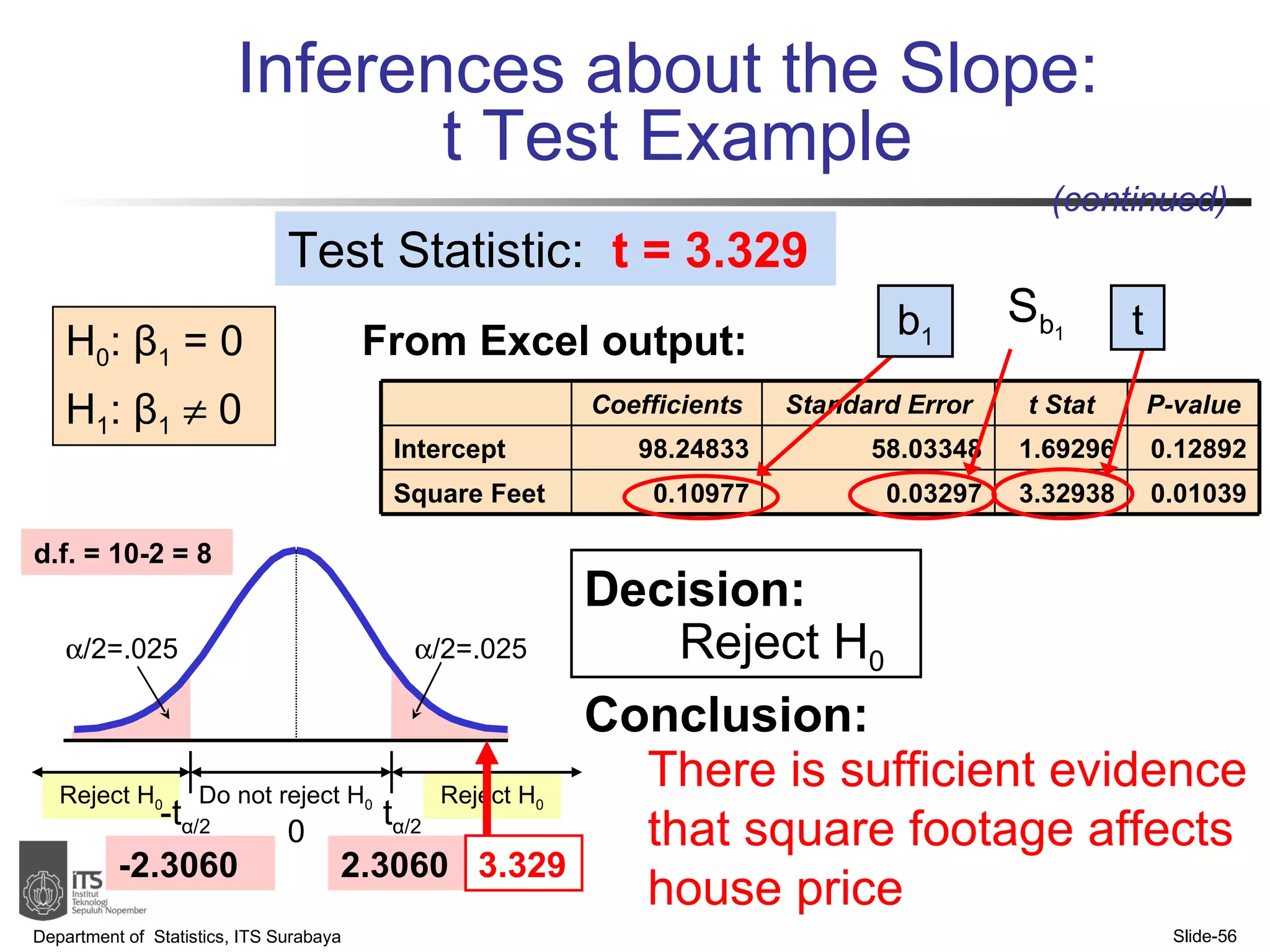
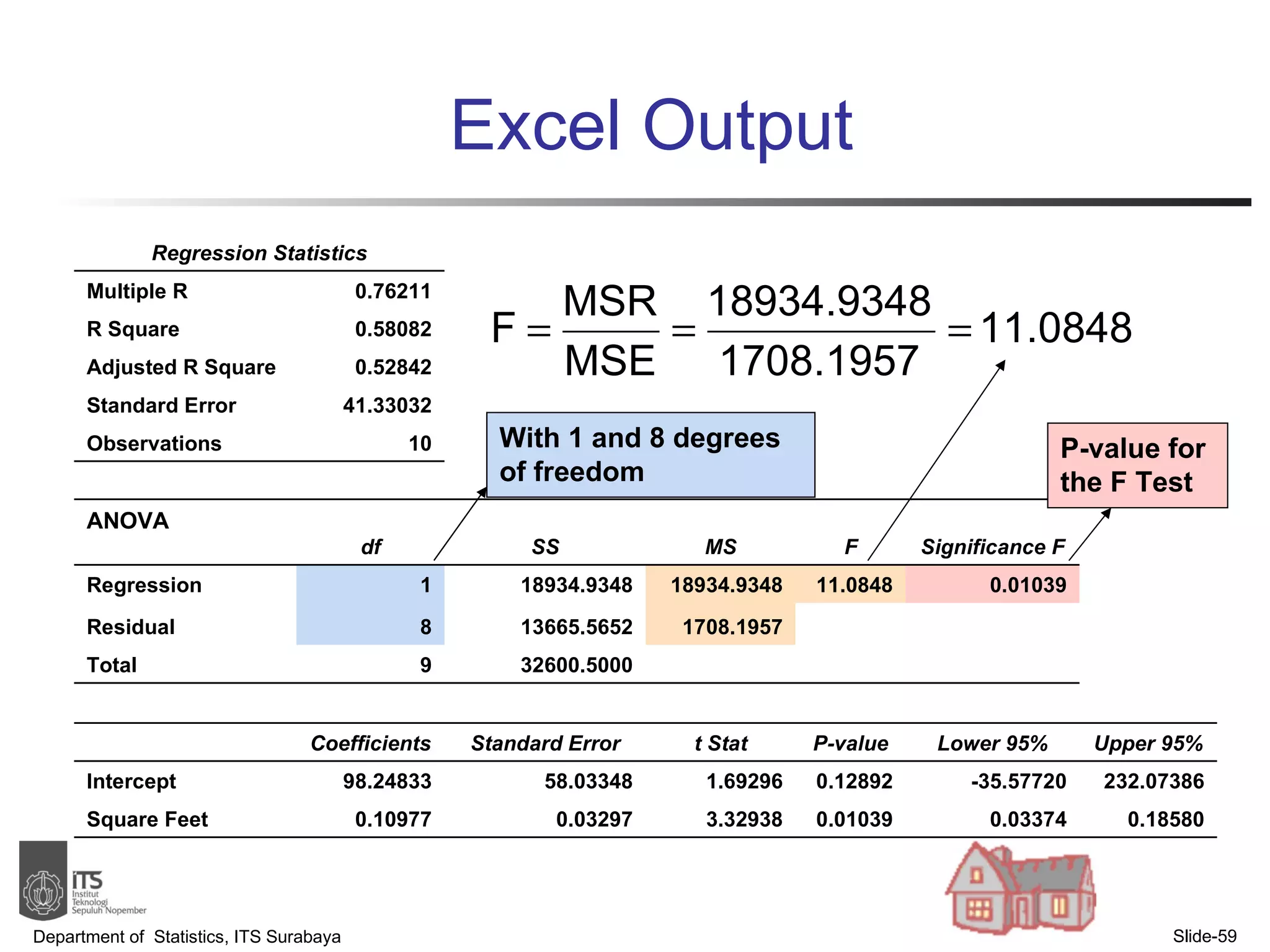
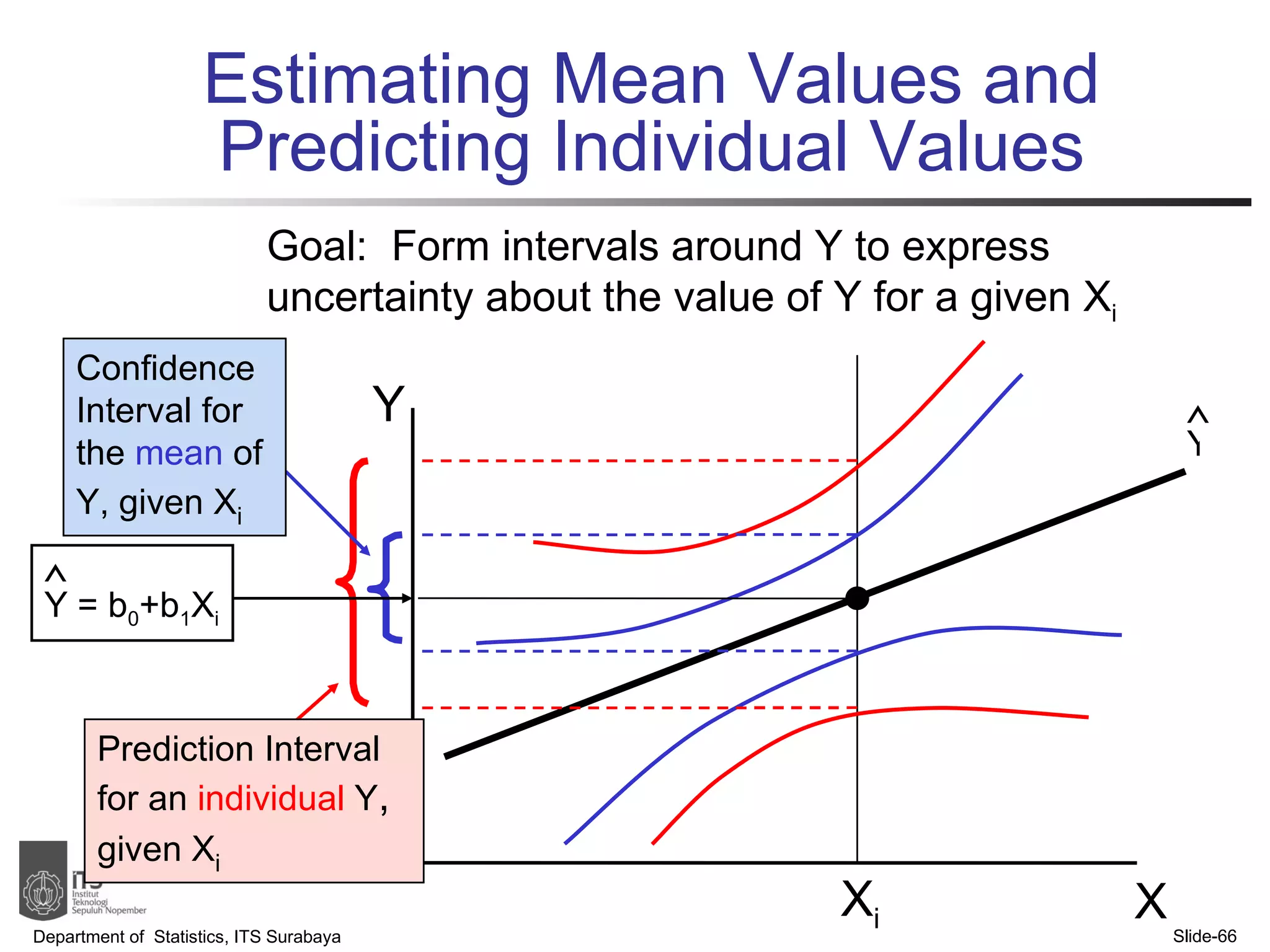
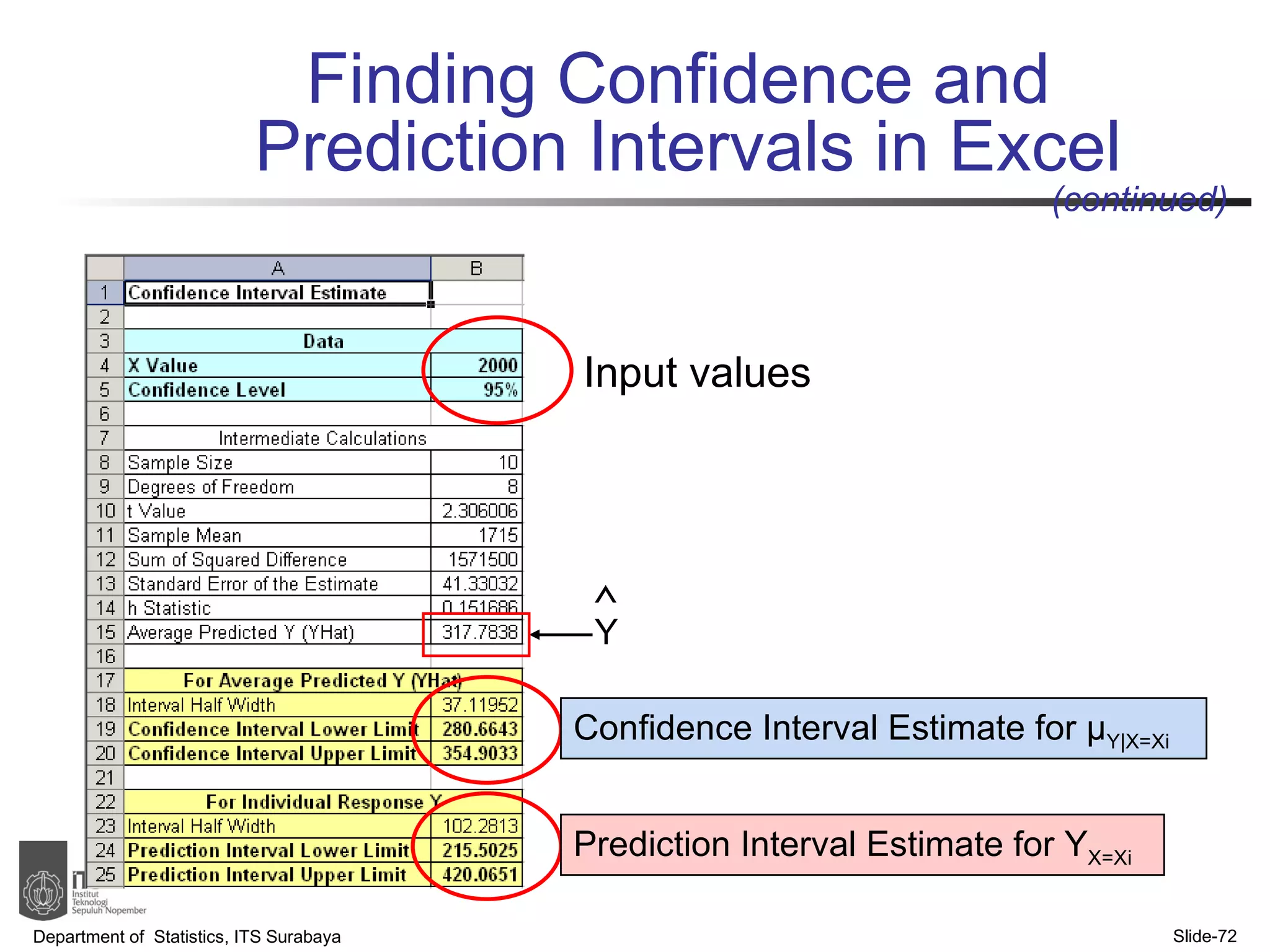
- Examples are provided to demonstrate simple linear regression analysis using data on house prices and sizes.