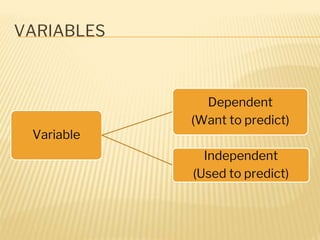
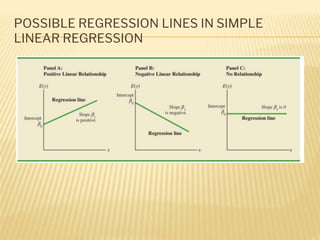
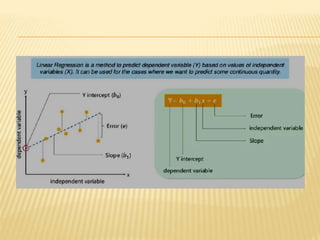
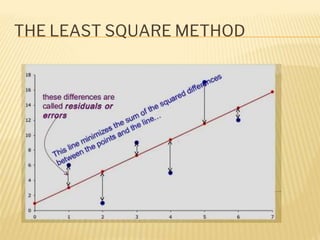
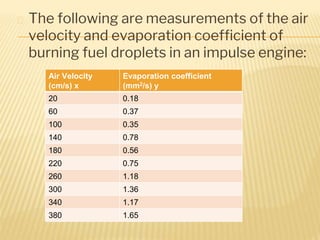
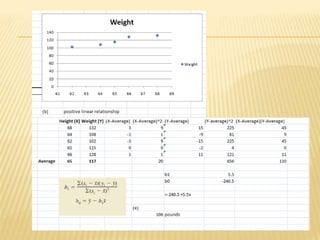
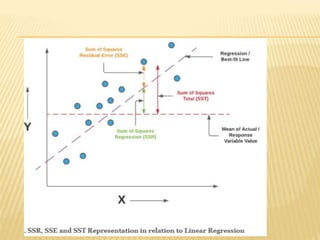
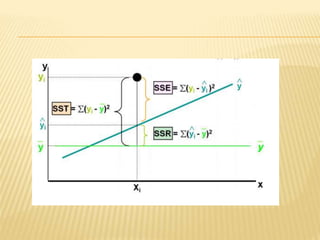
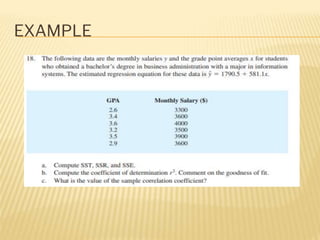
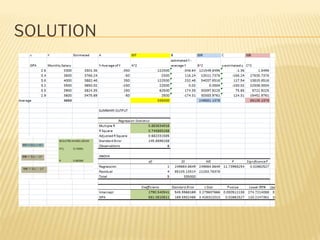
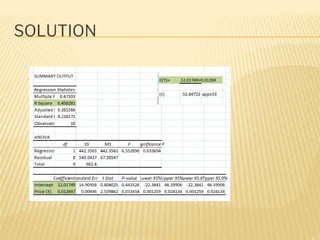
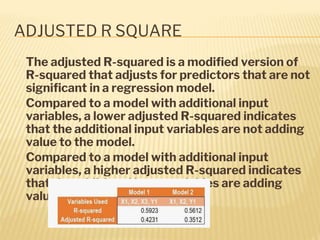
Regression analysis is used to establish relationships between variables and make predictions. It can be used to estimate dependent variables from independent variables, extend analysis to multiple variables, and show the nature of relationships. The key objectives are establishing if relationships exist and making forecasts. Regression requires interval scale data and establishes parameters and an error term in the regression equation. The least squares method chooses parameters that minimize errors between observed and estimated dependent variable values. Goodness of fit is measured by R-squared and F-tests and t-tests determine statistical significance.