




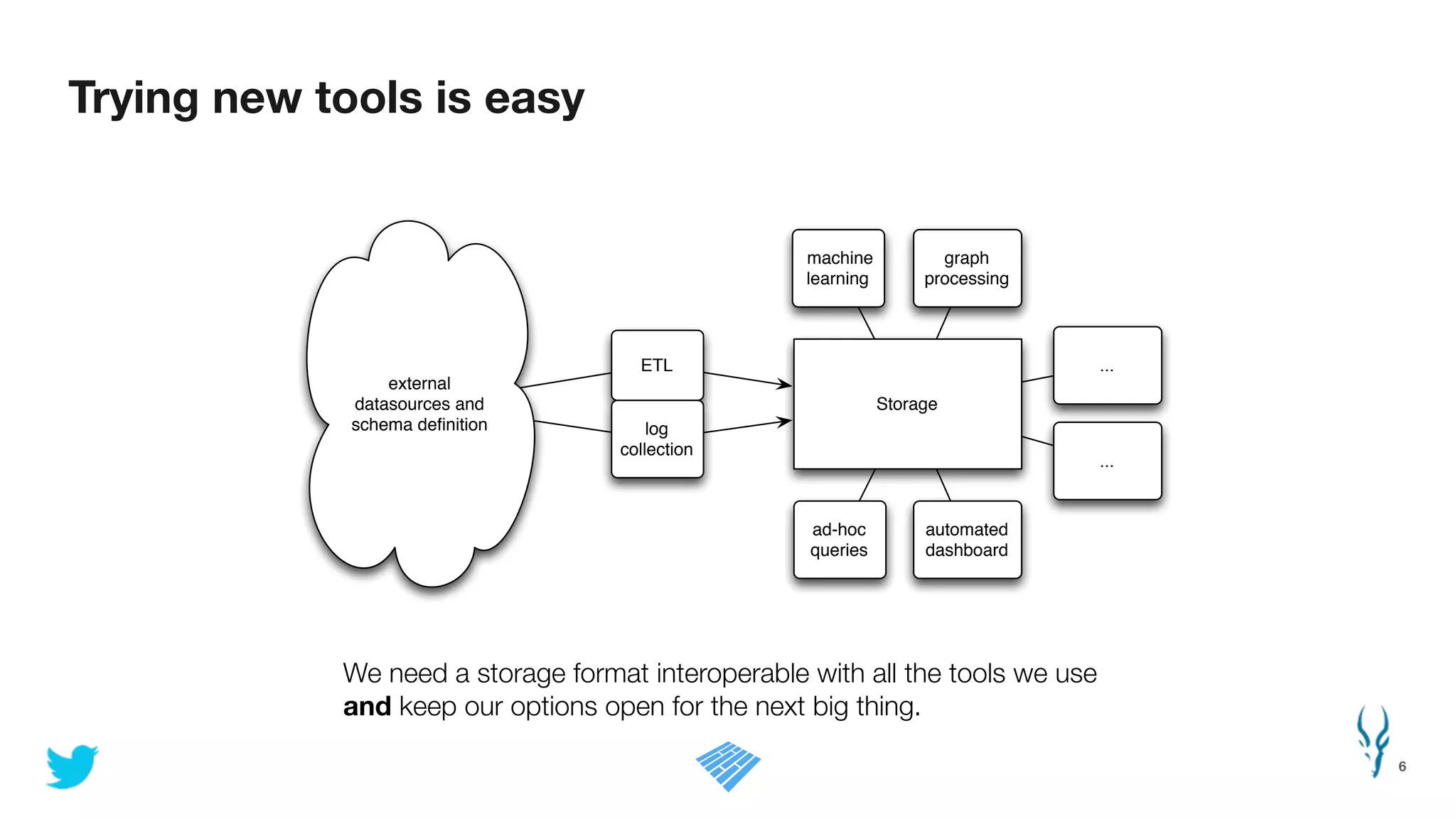










![Binary packing designed for CPU efficiency
27
better:
orvalues = 0!
for (int i = 0; i<values.length; ++i) {!
orvalues |= values[i]!
}!
max = maxbit(orvalues)!
see paper:
“Decoding billions of integers per second through vectorization”
by Daniel Lemire and Leonid Boytsov
Unpredictable branch! Loop => Very predictable branch
naive maxbit:
max = 0!
for (int i = 0; i<values.length; ++i) {!
current = maxbit(values[i])!
if (current > max) max = current!
}!
even better:
orvalues = 0!
orvalues |= values[0]!
…!
orvalues |= values[32]!
max = maxbit(orvalues)
no branching at all!](https://image.slidesharecdn.com/hadoopsummit-140630160016-phpapp01/75/Efficient-Data-Storage-for-Analytics-with-Apache-Parquet-2-0-27-2048.jpg)
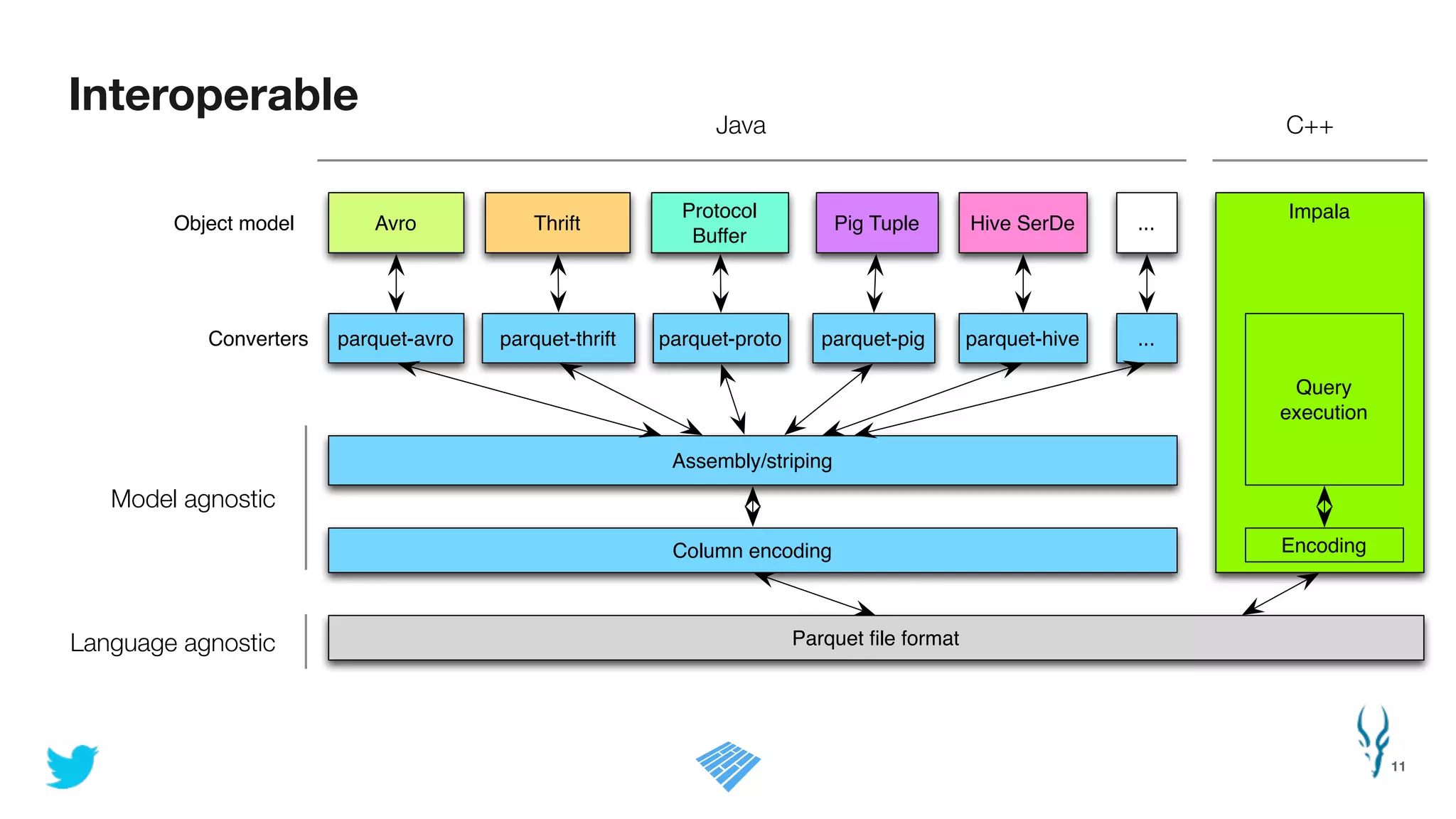
![Binary unpacking designed for CPU efficiency
28
!
int j = 0!
while (int i = 0; i < output.length; i += 32) {!
maxbit = input[j]!
unpack_32_values(values, i, out, j + 1, maxbit);!
j += 1 + maxbit!
}!](https://image.slidesharecdn.com/hadoopsummit-140630160016-phpapp01/75/Efficient-Data-Storage-for-Analytics-with-Apache-Parquet-2-0-28-2048.jpg)
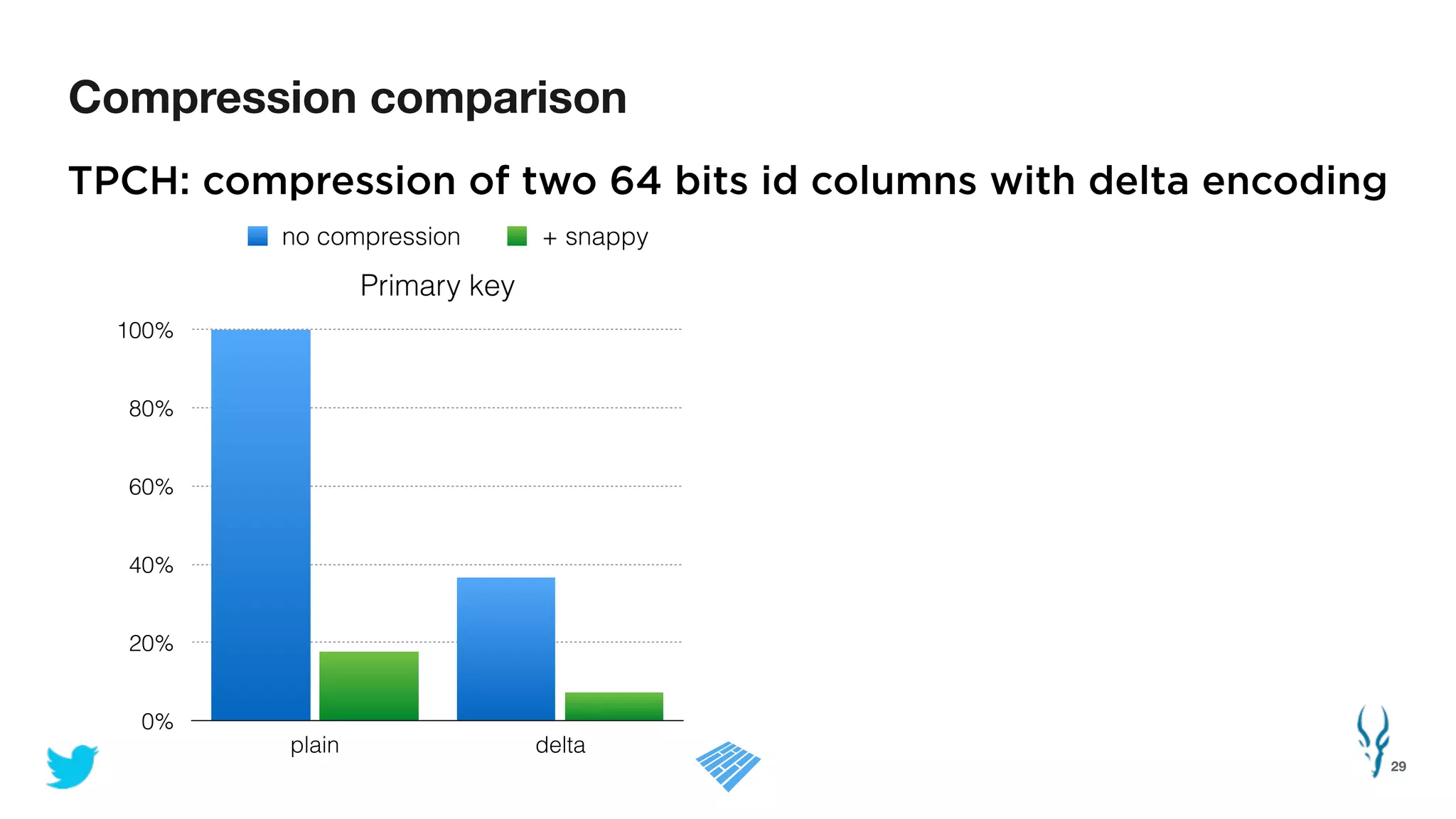
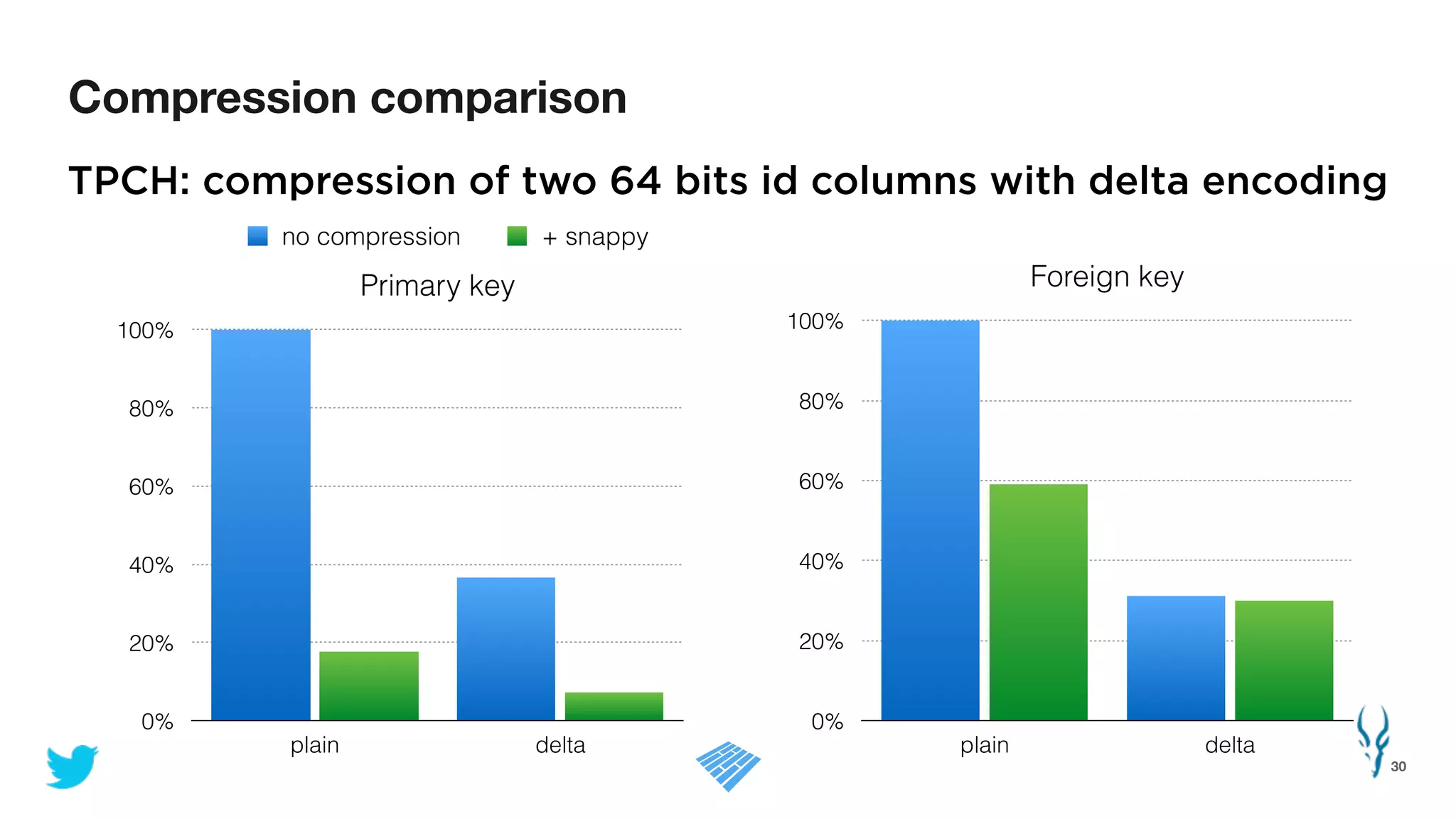
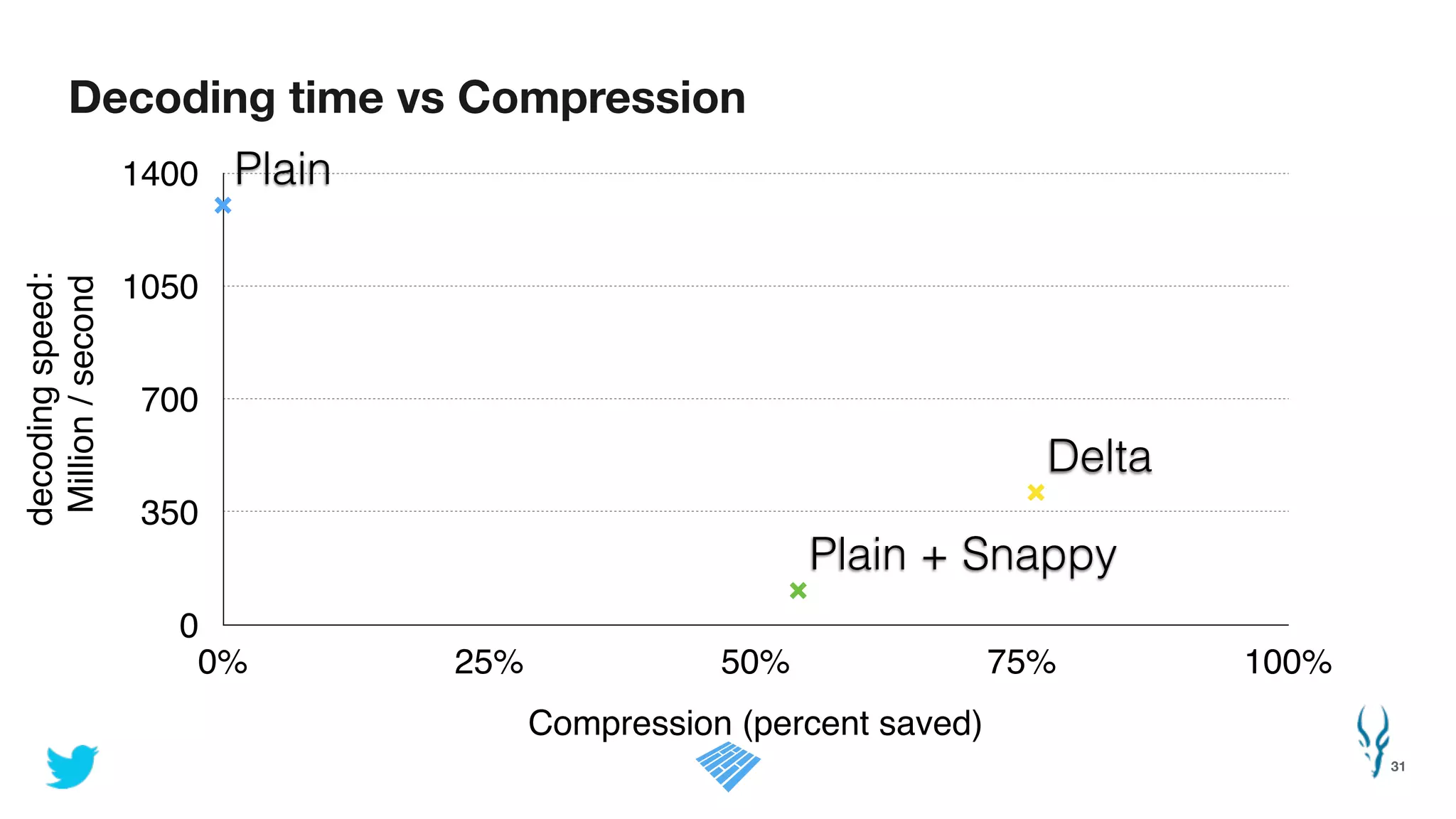

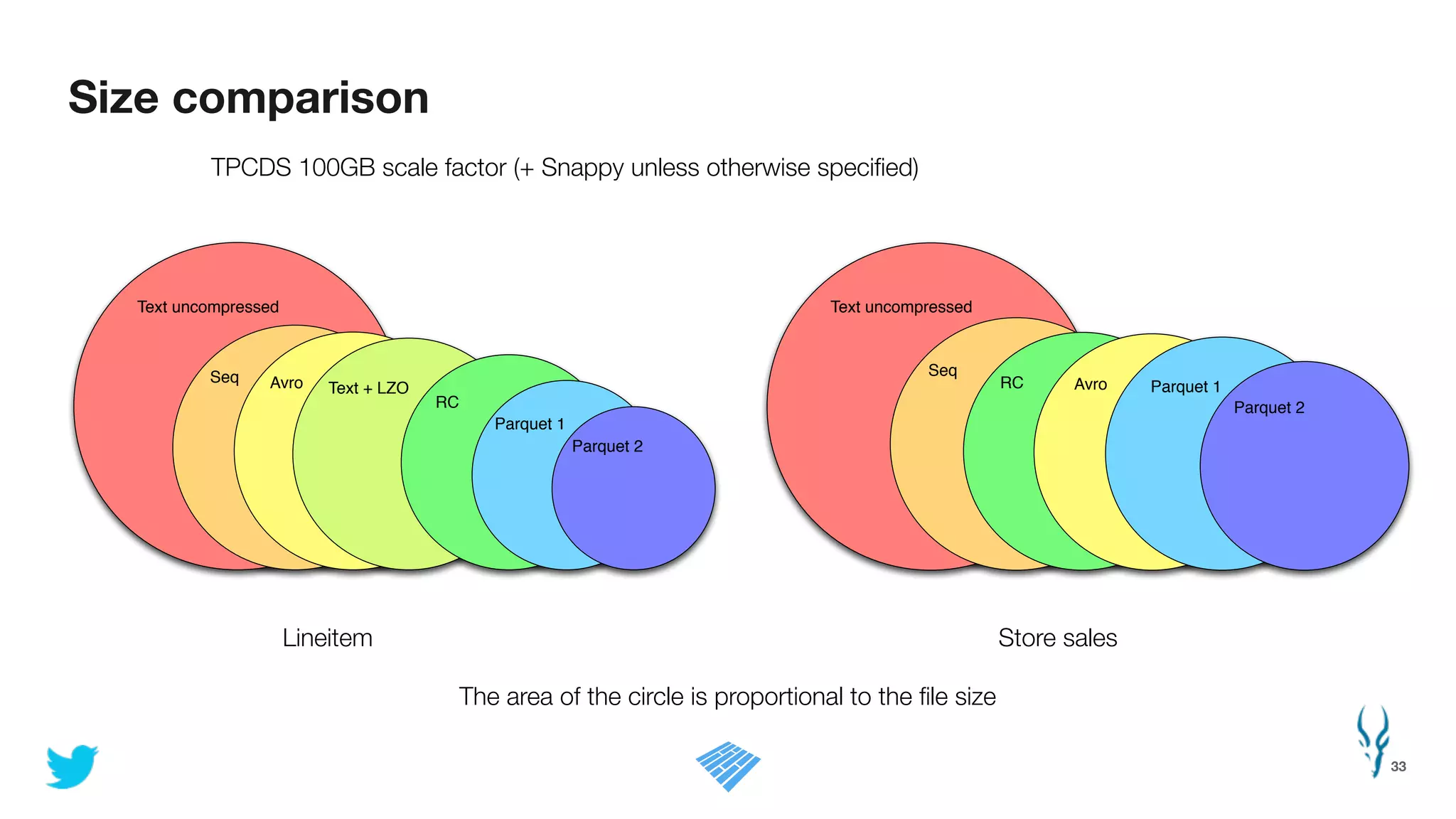
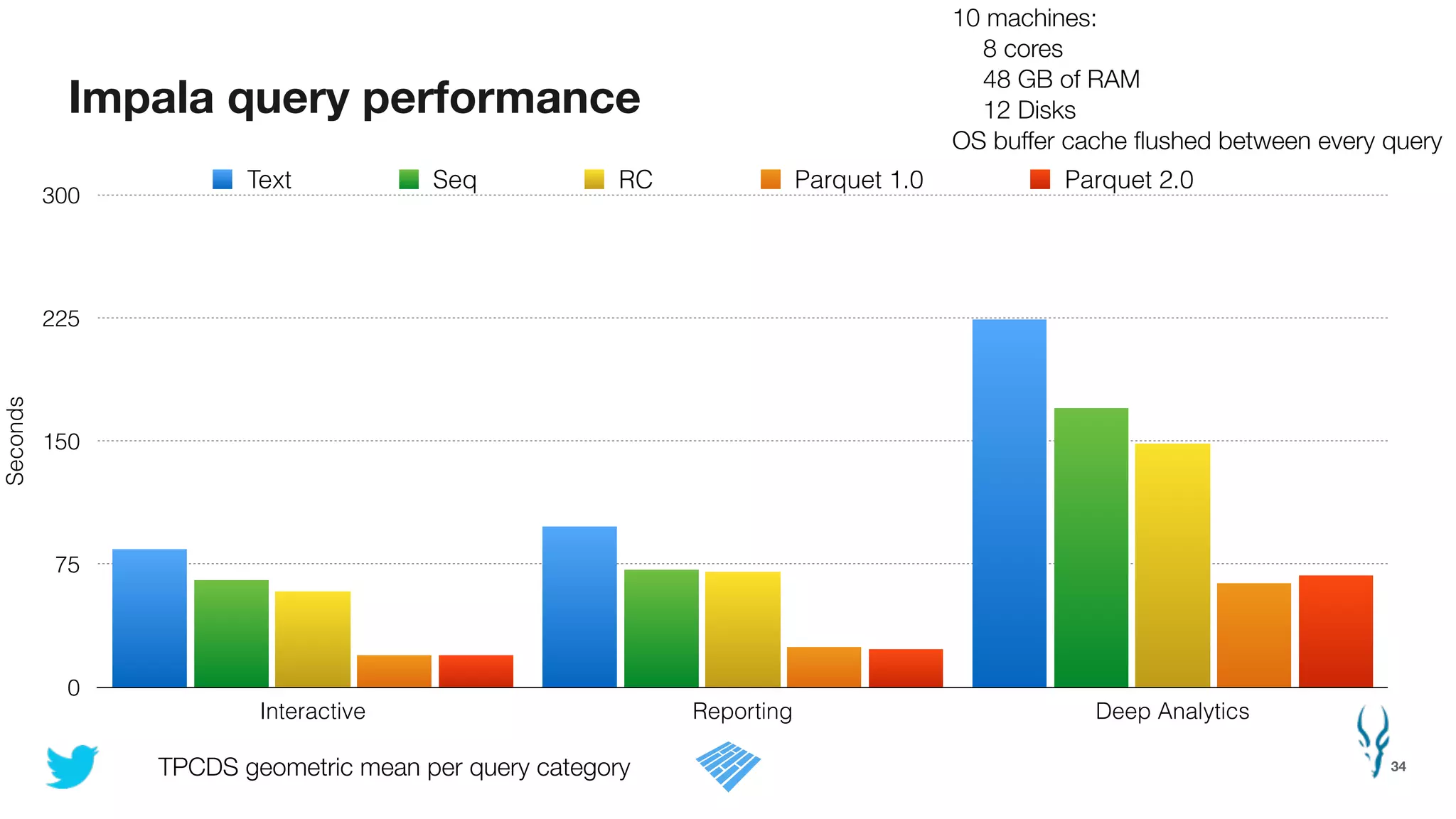



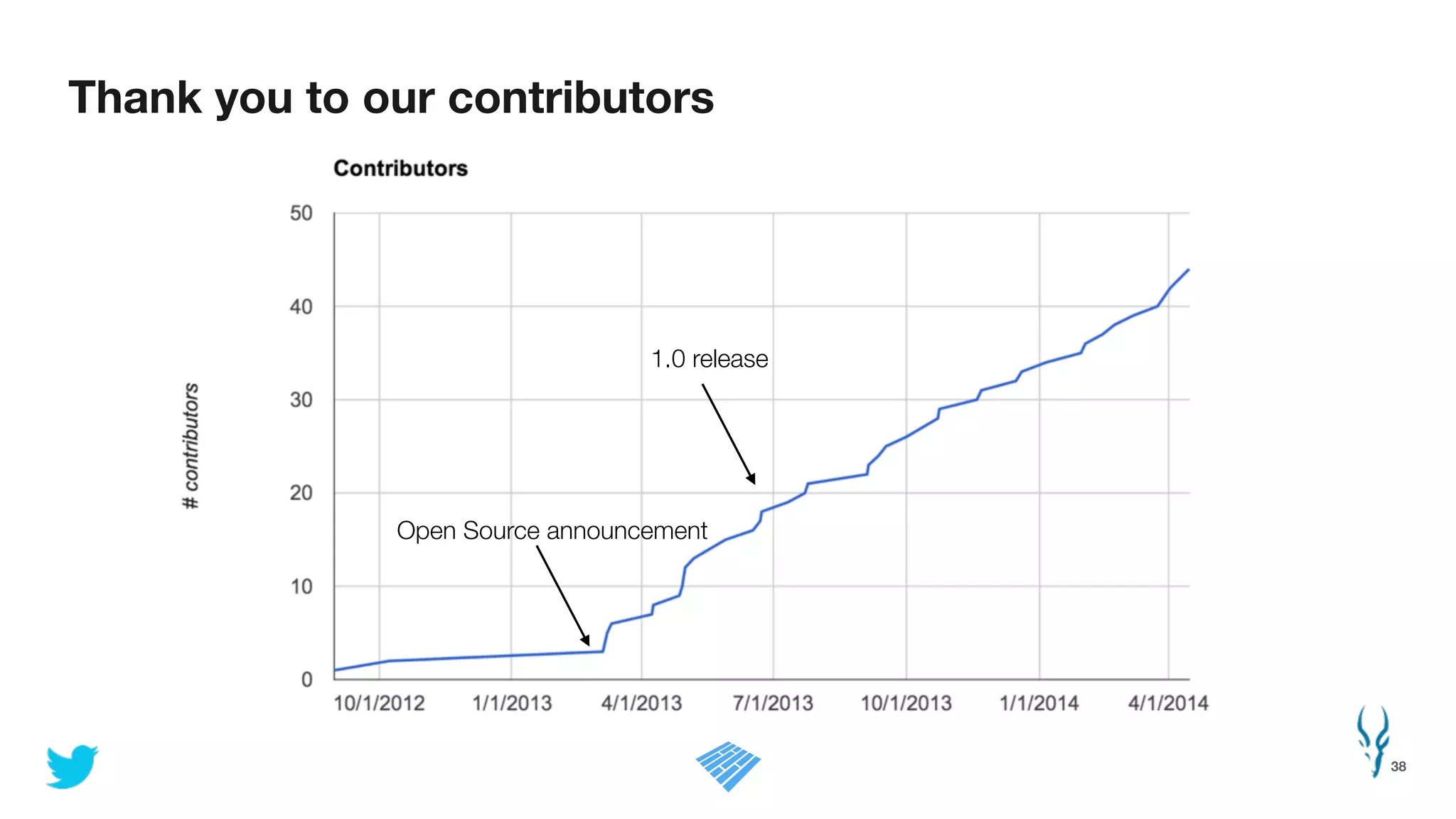



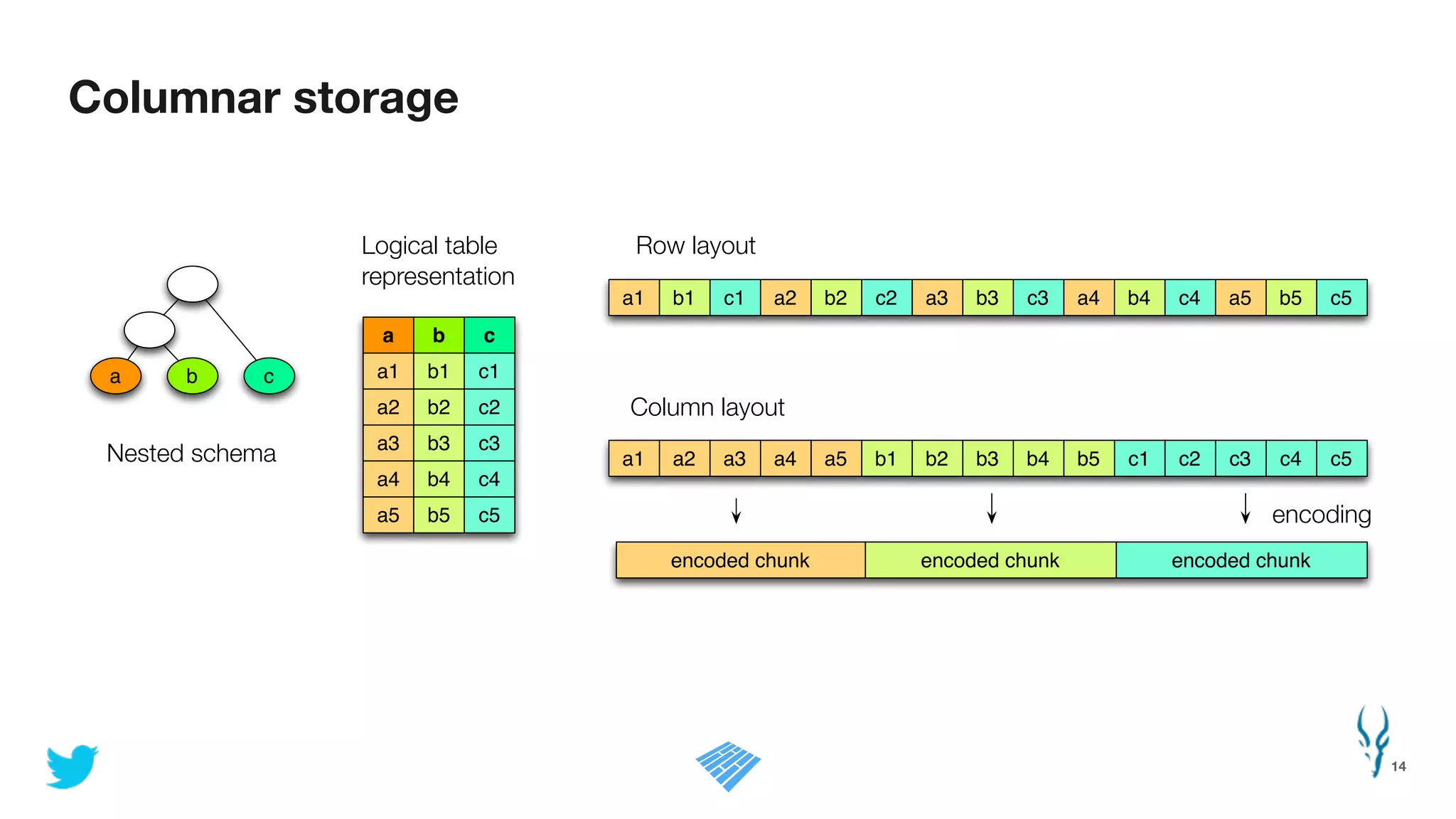
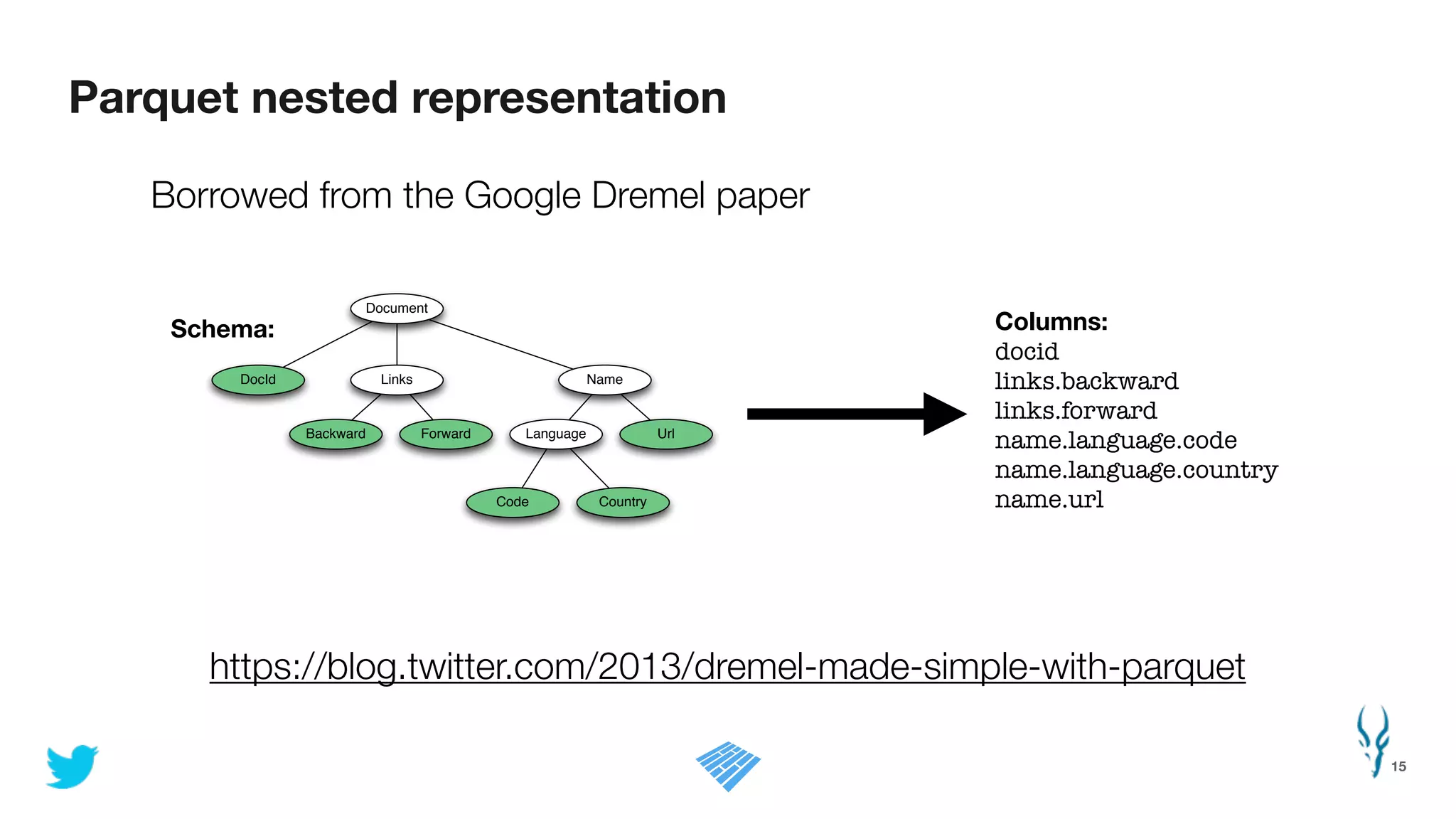
Apache Parquet is an open-source columnar storage format for efficient data storage and analytics. It provides efficient compression and encoding techniques that enable fast scans and queries of large datasets. Parquet 2.0 improves on these efficiencies through enhancements like delta encoding, binary packing designed for CPU efficiency, and predicate pushdown using statistics. Benchmark results show Parquet provides much better compression and query performance than row-oriented formats on big data workloads. The project is developed as an open-source community with contributions from many organizations.









































































































