Downloaded 130 times




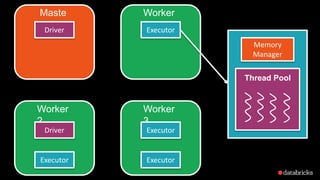
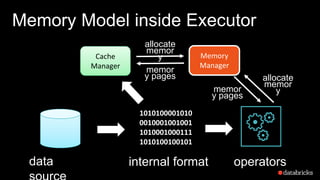
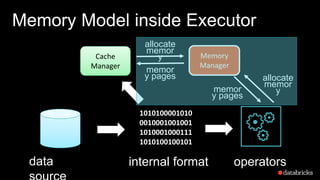


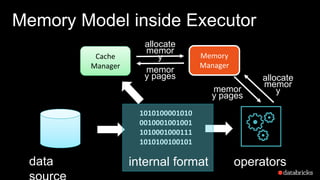
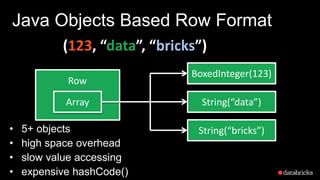




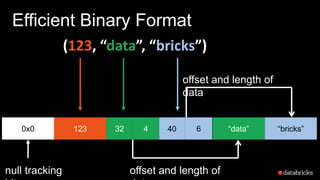
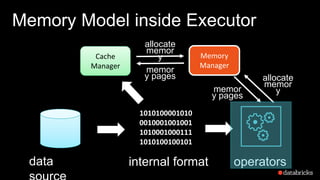


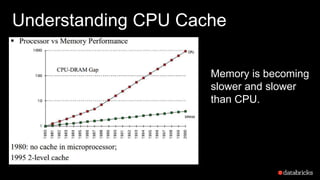


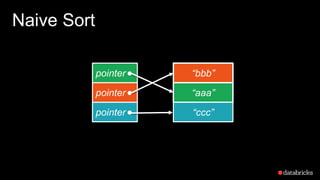

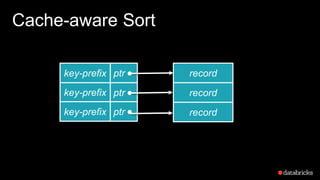

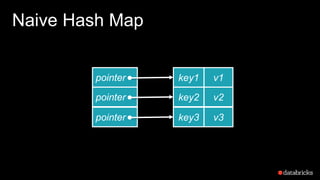
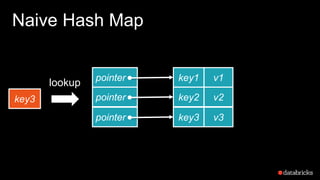
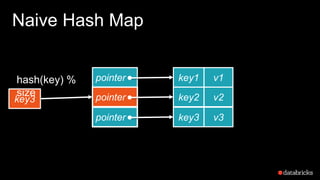
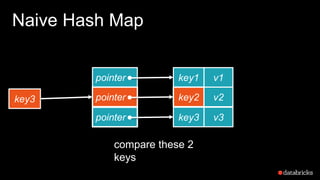
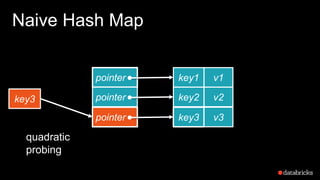
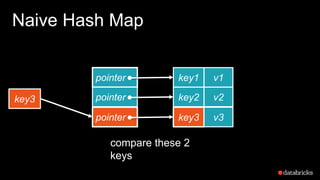

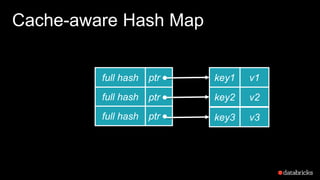
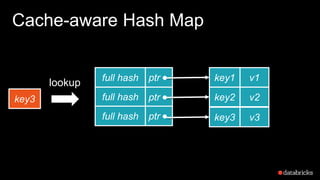
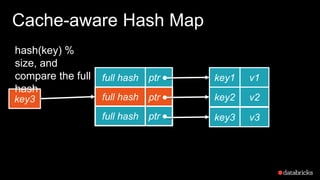
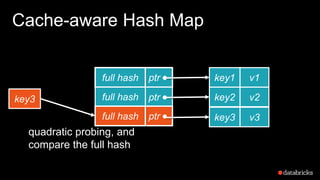
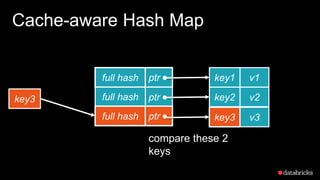


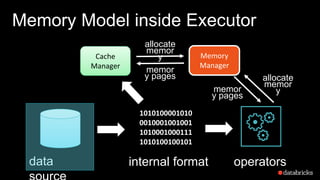




The document presents insights into Spark's memory model, focusing on memory allocation, cache management, and efficient data processing strategies. It highlights the use of binary formats and cache-aware data structures to enhance performance and reduce garbage collection overhead. Future work includes improvements in serialization formats and the introduction of a columnar execution engine.























































































