Downloaded 12 times


















This document discusses harnessing cloud computing for analyzing large neuroimaging datasets. It describes using the Amazon cloud to run the Configurable Pipeline for the Analysis of Connectomes (CPAC) on over 1,000 neuroimaging datasets. Running CPAC in the cloud provides scalable resources without hardware costs and allows processing many datasets in parallel. The results show cloud computing can significantly reduce costs and processing time compared to traditional computing for large neuroimaging projects.
Presentation introduction to harnessing cloud computing for high-capacity neuroimaging data analysis.
Discusses characterizing connectomes, identifying disease biomarkers, and redefining mental health.
Introduces the concept of connectomics as a form of Big Data.
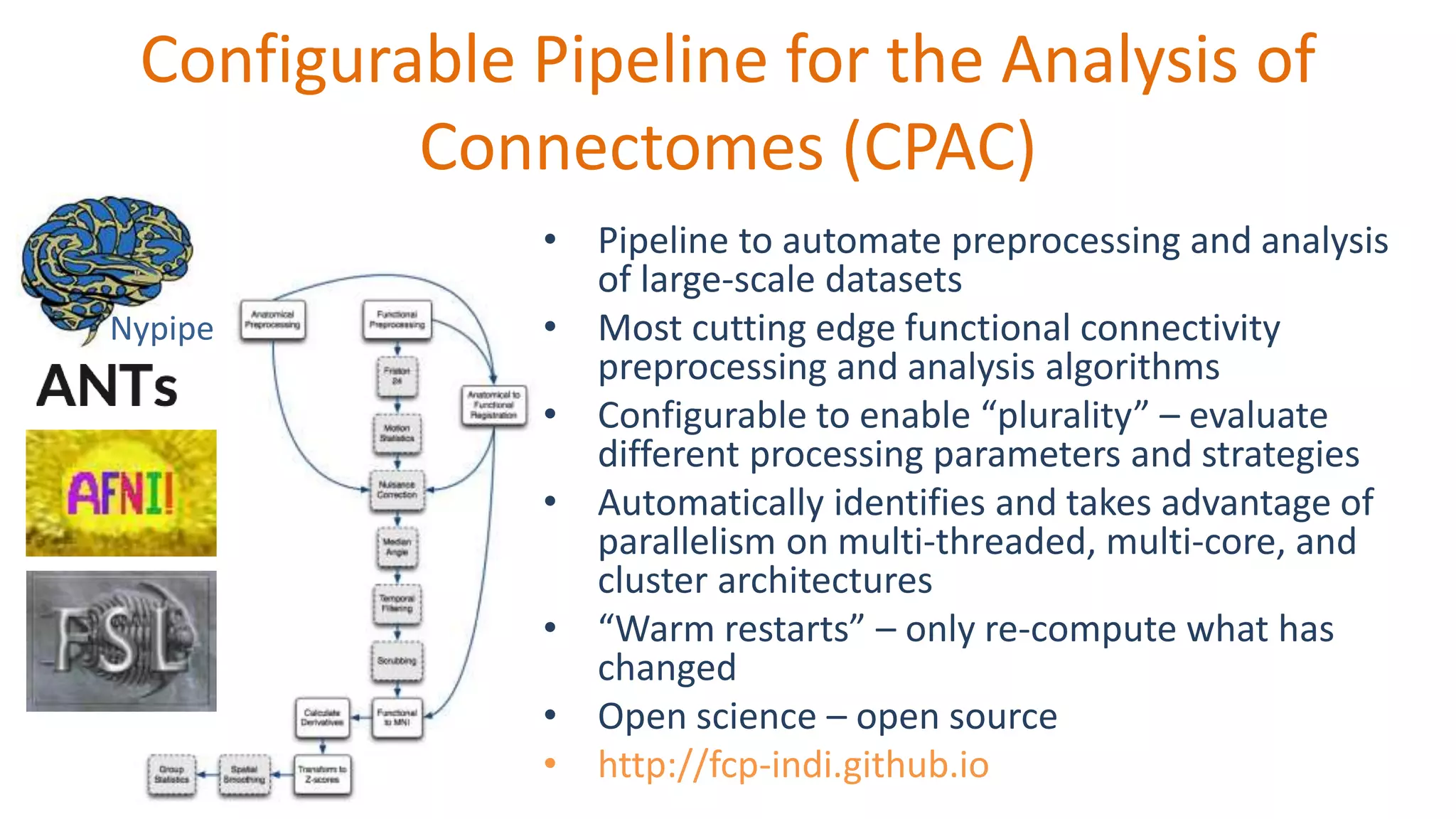
Details on CPAC, a pipeline for automating analysis of large datasets with advanced algorithms.
Outlines advantages of computing in the Amazon Cloud, including cost-effectiveness and scalability.
Describes EC2 instances, the hardware used for processing.
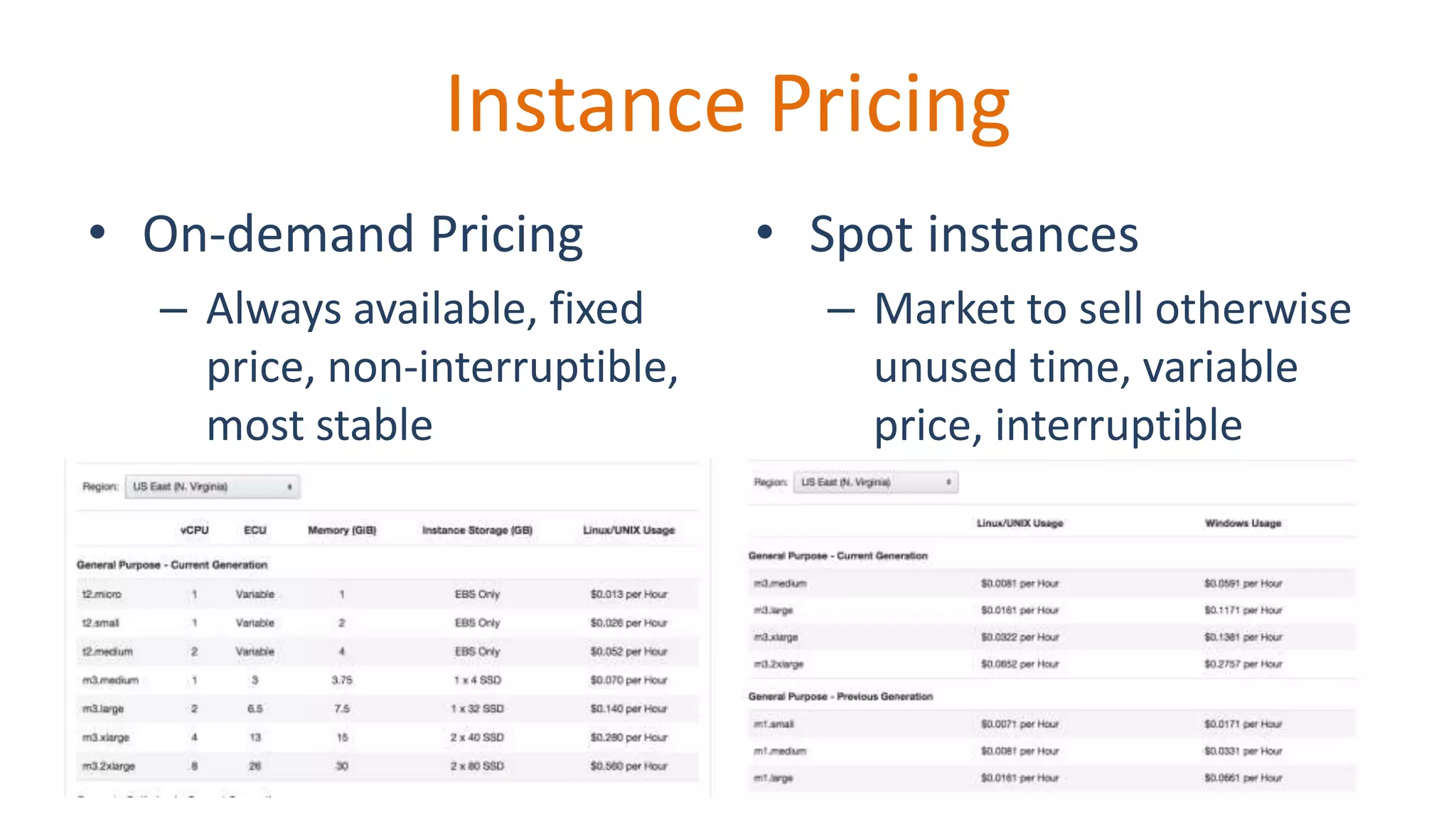
Explains on-demand and spot instance pricing options.
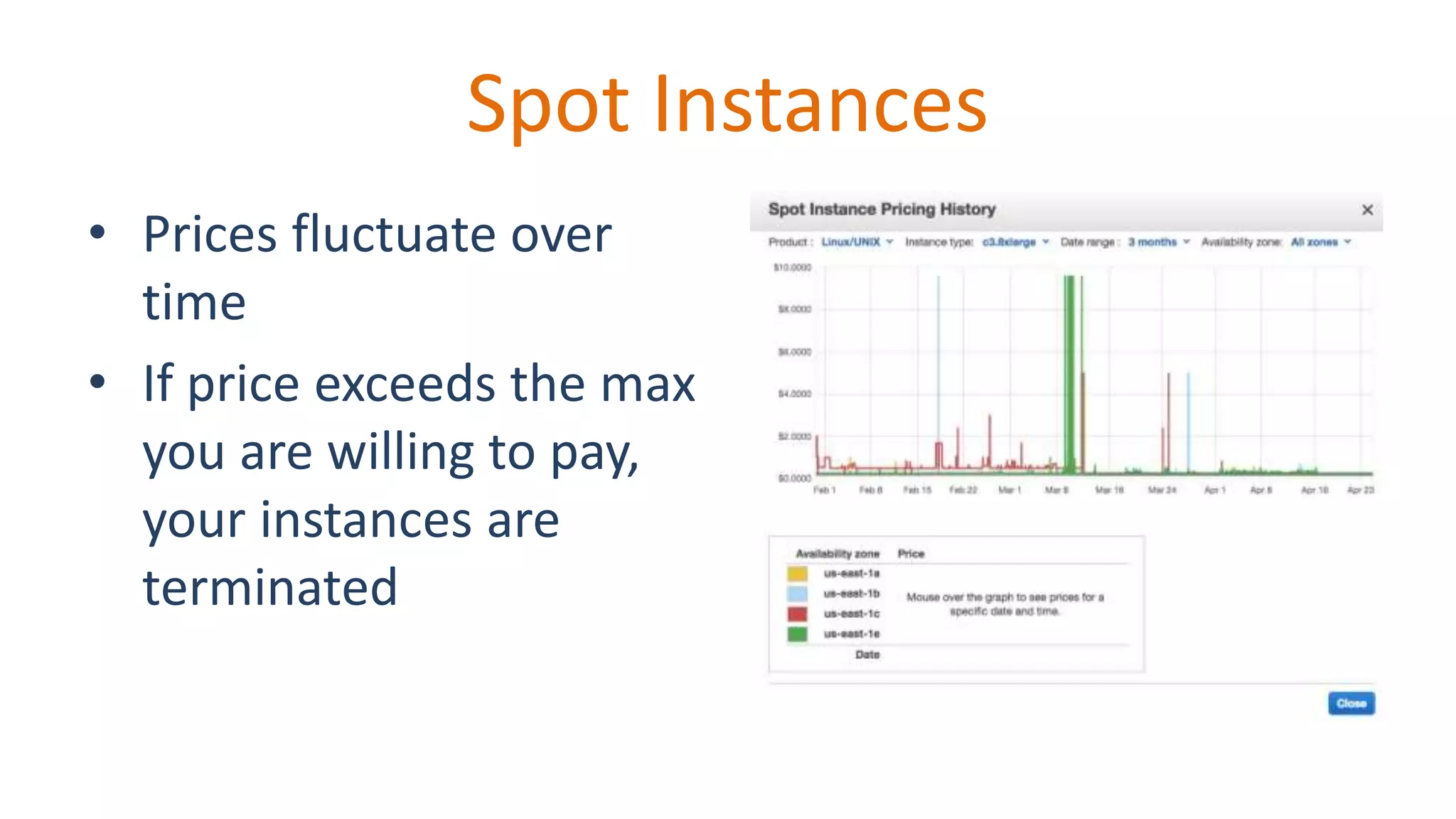
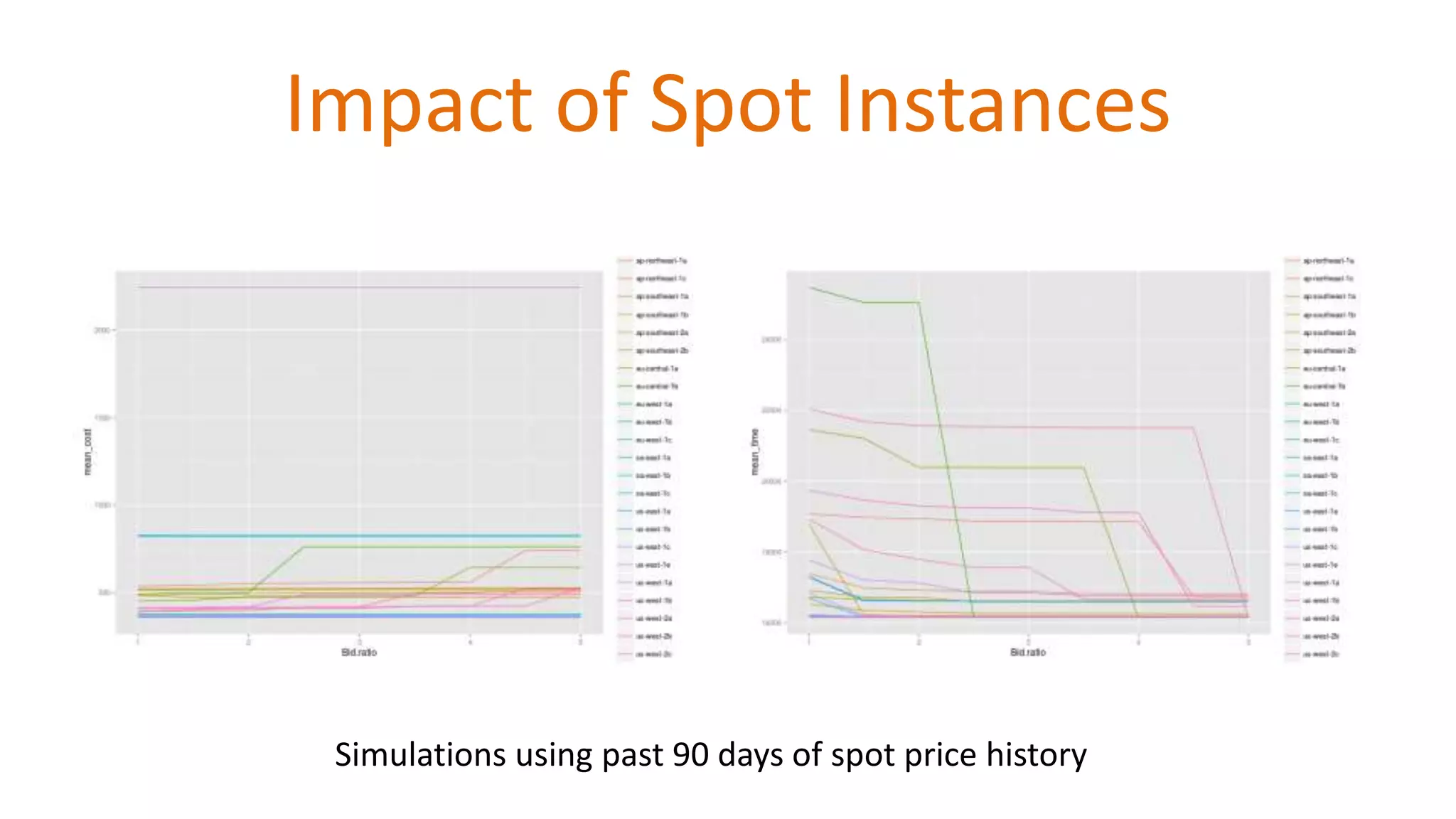
Details how spot instance prices can change and impact processing.
Comparison of S3 and EBS storage types, their costs, and use cases.
Examines AWS data transfer pricing and conditions.
Describes Amazon Machine Images and their role in processing environments.
Introduces StarCluster for managing compute nodes on AWS.
Highlights the C-PAC Amazon Machine Image.
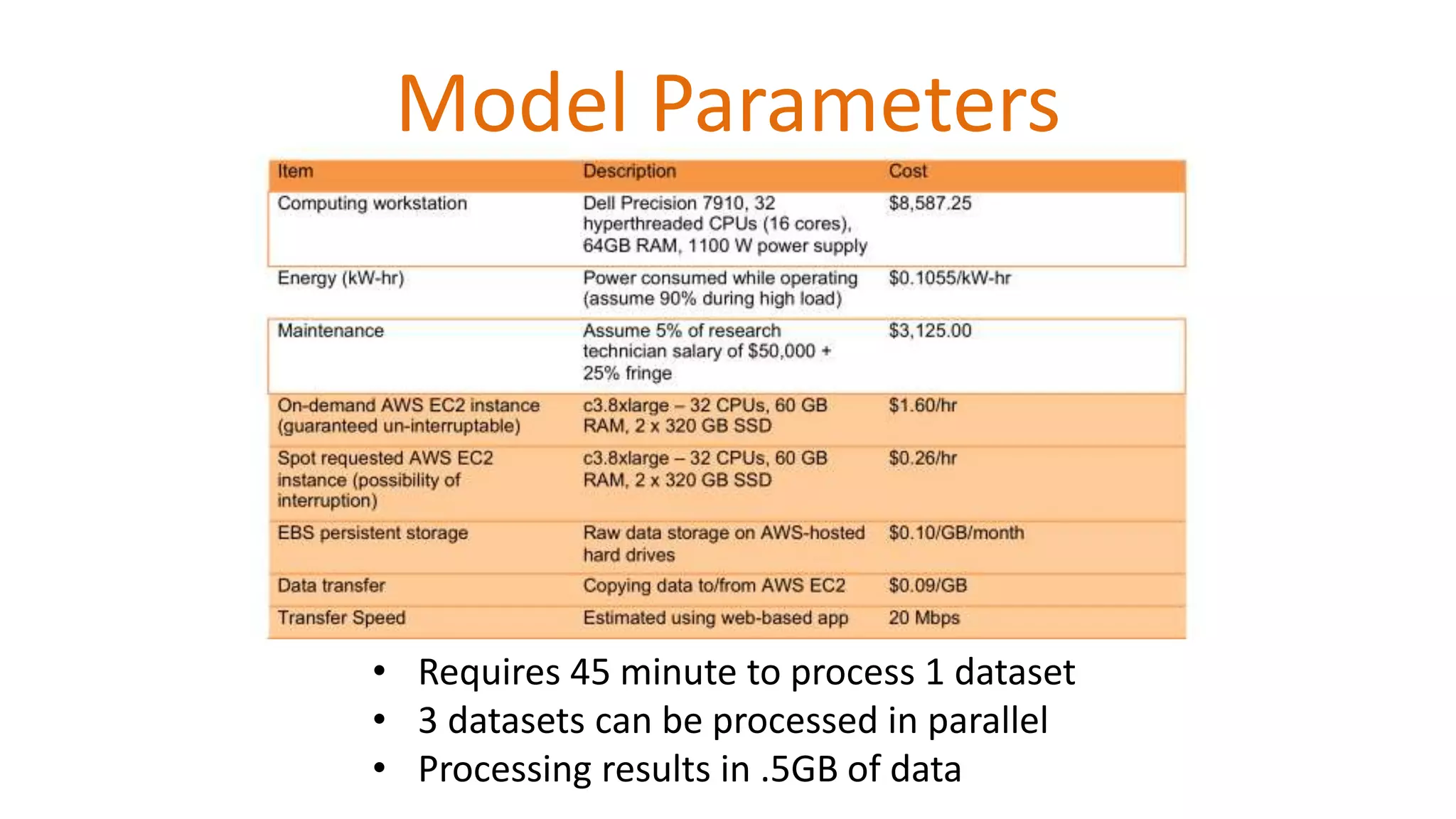
Details the preprocessing of neuroimaging datasets with C-PAC and processing times.
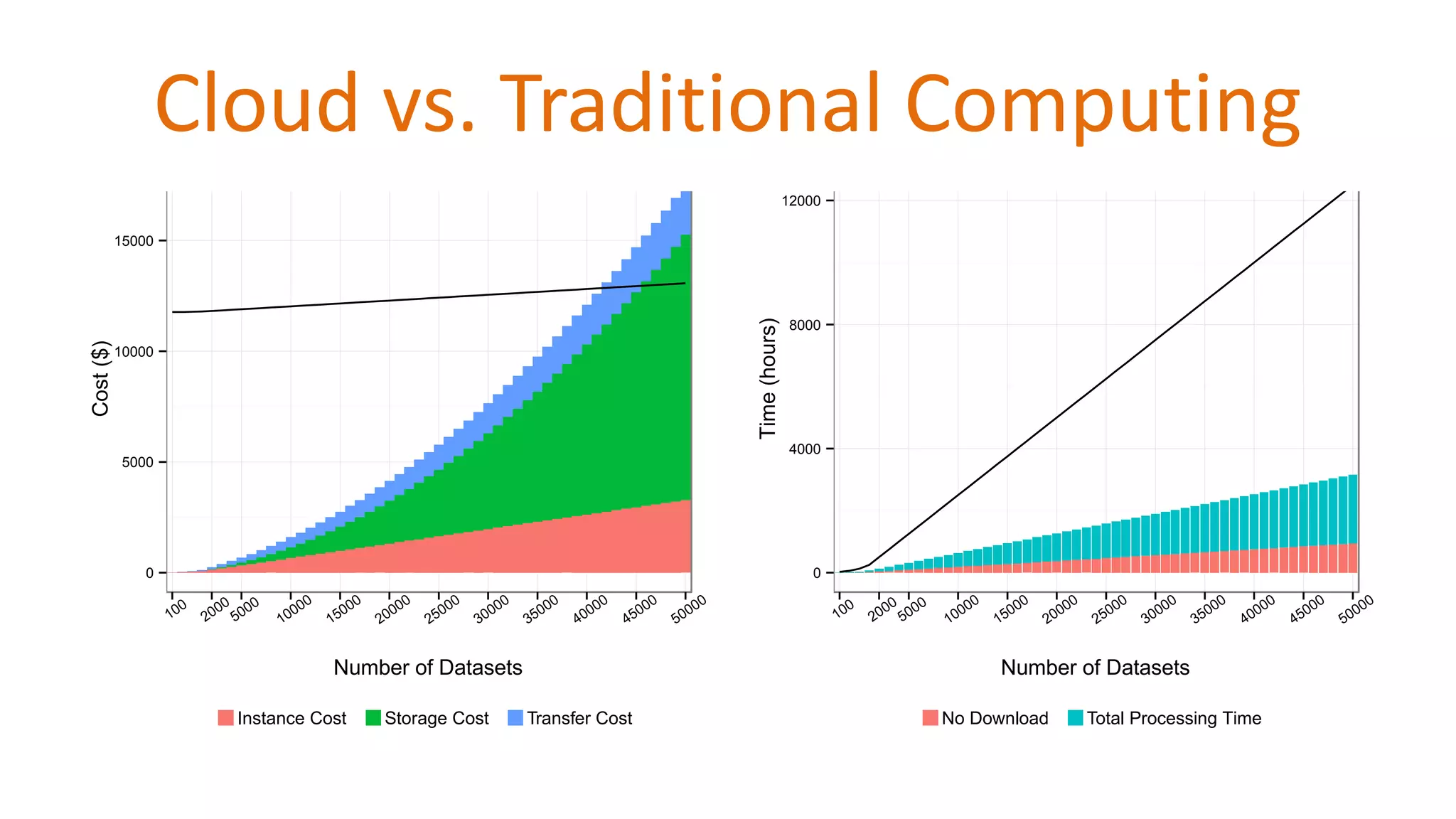
Comparison of costs and processing times in cloud vs traditional computing.
Simulated analysis of spot instance price impacts.
Brief mention of alternative pipelines in neuroimaging.
Details on AWS compliance with HIPAA and security measures.
Reiterates availability of C-PAC machine image.
Provides links to access preprocessed INDI data stored on AWS.
Information about accessing HCP data on the cloud and credits.
Acknowledges the CPAC and NDAR teams involved in the project.






























































![Big data application using hadoop in cloud [Smart Refrigerator]](https://cdn.slidesharecdn.com/ss_thumbnails/pushkarbhandari-160107183520-thumbnail.jpg?width=640&height=640&fit=bounds)































