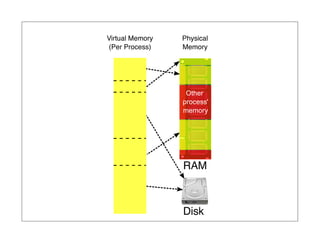
The document discusses various topics related to using MongoDB including schema design, indexing, concurrency, and durability. For schema design, it recommends using small document sizes and separating documents that grow unbounded into multiple collections. For indexing, it emphasizes ensuring queries use indexes and introduces sparse indexes and index-only queries. It notes concurrency is coarse-grained currently but being improved. For durability, it discusses storage, journaling, replication, and write concerns.








![// Sample: user with followers
{ _id: ObjectId("4e94886ebd15f15834ff63c4"),
name: 'Kyle'
followers: [
{ user_id: ObjectId("4e94875fbd15f15834ff63c3")
name: 'arussell' },
{ user_id: ObjectId("4e94875fbd15f15834ff63c4")
name: 'bsmith' }
]
}](https://image.slidesharecdn.com/mongodb-in-anger-boston-rb-2011-111024113008-phpapp01/85/Mongodb-in-anger-boston-rb-2011-9-320.jpg)