尤度比 (χ2)検定 によるDIFの検出:
DIFのタイプ比較するモデル
uniform DIF baseline model vs. uniform DIF
non-uniform DIF uniform DIF vs. non-uniform DIF
total DIF baseline model vs. non-uniform DIF
1) baseline model
3) non-uniform DIF
2) uniform DIF
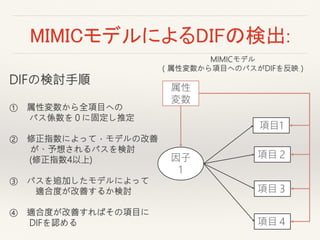
groupFagroupaFabku
groupaFabku
Fabku
ki
ki
ki
*log
log
log
221
21
1
特性値と群の交互作用項
群の (主)効果
25.
効果量 (DIFの程度)の指標:
pseudo R2(擬似決定係数): 分散説明率R2の代替指標
Zumbo (1999) の基準 効果量の解釈
0.13未満 無視して良い(negligible)
0.13以上0.26未満 中程度 (moderate)
0.26以上 大きい (large)
Zumbo BD (1999). A Handbook on the Theory and Methods of Differential Item Functioning (DIF): Logistic Regression Modeling as a Unitary Framework for
Binary and Likert-Type (Ordinal) Item Scores. Directorate of Human Resources Research and Evaluation, Department of National Defense, Ottawa, ON.
Db =
(bbaseline model - buniformn )
buniformn
10%以上が実用的 (practical)に意味のある効
果
(Crane et al. 2004)
Δ β : 属性変数の回帰係数の変化率
Crane PK, van Belle G, Larson EB (2004). “Test Bias in a Cognitive Test: Differential Item Functioning in the CASI.”
Statistics in Medicine, 23, 241–256.
ロジスティック回帰 vs
MIMIC
❖ 大抵MIMICモデルとOLSは同様の結果になる。
❖2値モデルでは, OLSよりMIMICモデルの方がやや良い。
❖ 多値モデルかつ標本サイズが小さい時は、MIMICモデルの方が良い
Stark, S., Chernshenko, O. S., & Drasgow, F. (2006). Detecting differential item functioning with confirmatory factor
analysis and item response theory: Toward a unified strategy. Journal of Applied Psychology, 91(6), 1292–1306
29.
記載例2
❖ 方法の節: IRTOLSの場合
QualLife Res (2015) 24:1491–1501 DOI 10.1007/s11136-014-0870-
DIF was analyzed with the R software package Lordif [31]. The
Lordif utilizes an ordinal logistic regression framework, and the
graded response (GR) model is used for IRT trait estimation
[32]. Two criteria were considered to detect meaningful DIF in the
current study: (1) < 0.13 pseudo R2 statistic [33] and (2) 10 %
changes in beta [31, 34, 35].
もっと詳しく書くなら右も参考になる→
使用したソフトウェア
DIF検出に用いた統計モデル
IRTの特性値の推定に使用した統計モデル
DIFの検出基準
Qual Life Res (2014) 23:239–244
30.
記載例2
Of the 132tests performed (22 items by 6 confounding factors), 50 exhibited overall DIF (Table
4 ). Following Zumbo’s DIF classification, no items were flagged for moderate or large DIF
magnitudes. Some items were flagged for negligible DIF magnitudes: three items for gender
(items 2, 3, and 4), … (中略)…, 18 items for geographical area (1–13, 15–17, 20, and 22). Given
the negligible DIF magnitudes, all 22 items were preserved in the final item bank.
Qual Life Res (2015) 24:1491–1501 DOI
10.1007/s11136-014-0870-x
❖ 結果の節: IRTOLSの場合
各項目の検定結果と効果量を,
検討したグループ変数ごとに表記
効果量を,基準に基づいて解釈
31.
記載例1
❖ 方法の節: MIMICmodel
❖ 結果の節: MIMIC model
Another important assumption of CCFA is no differential item functioning (DIF). This assumption was
tested for each item of the two PROMIS measures using the multiple indicator multiple cause
(MIMIC) model [25 –28], in regard to gender and age, each adjusted for the other. The MIMIC model
enables examining DIF even for a continuous variable (e.g., age) that has small within-group sample
sizes [25 ]. Significant direct effect of a grouping variable (e.g., age, gender) on an item indicates
DIF of the item. A DIF implies that a given item was not interpreted in a conceptually similar manner by
respondents with different individual characteristics (e.g., age and gender).
As the DIF tests for all the items were
conducted simultaneously, there was no need
to make adjustment for multiplicity of
comparison. None of the DIF tests were
statistically significant.
平均/平均法(mean / meanmethod)
a =
aY
aX
form X form Y
識別度
(a)
困難度
(b)
識別度
(a)
困難度
(b)
item3 1.20 -1.30 2.60 -1.15
item4 .60 -.10 1.20 -0.55
item5 1.70 .90 3.40 -0.05
平均 1.17 -0.17 2.4 -0.58
標準偏差 0.55 1.10 1.11 0.55
α=2.4/1.17=2.05
β=-0.17-2.05*0.55 =-1.30
b = bX -a *bY
識別度母数の平均からαを算出
mean/sigma法と同様にβを算出
44.
項目特性曲線法
❖ Haebara法
2つの尺度の項目特性曲線間の差が最小になるαとβを推定する
❖ Stocking& Lord法
SLdiff (qi ) pij (qXi;aXj,
j:V
å bXj )- pij (qXi;
aYj
a
,
j:V
å abYj + b)
é
ë
ê
ê
ù
û
ú
ú
2
Hcrit(qi ) =
j:V
å pij (qXi;aXj,bXj )- pij (qJi;
aYj
a
,abYj +b)
é
ë
ê
ù
û
ú
2
尺度Xの項目特性曲線 等価した尺度Yの項目特性曲線
尺度Xのテスト特性曲線 等価した尺度Yのテスト特性曲線
2つの尺度のテスト特性曲線間の差が最小になるαとβを推定する
基本的に,項目特性曲線に基づく方法が良いが,
複数の方法で感度解析的にやるのが良い
記載例1
❖ 結果の節: PROMIS尺度に他の尺度の項目母数を等価
Table3 displays the legacy instrument item parameters obtained from the fixed-
parameter calibrations. For each instrument pair, the test characteristic curves
(TCCs) of the separate calibrations using linking constants were nearly identical to
the TCCs of the fixed calibrations. In fact, for each comparison between the TCCs,
the expected raw score value differed by less than 1 point across thetas ranging
from 4 to 4. Because of the close similarity of the different IRT solutions, we
report only the results of the fixed-parameter estimates.
識別度 困難度
Figure 3 displaysthe linking functions for the CES-D,
PHQ-9, and BDI-II that map their raw summed
scores (the vertical axis) to the PROMIS
Depression metric (the horizontal axis). Traditional
cutoff scores for the legacy measures are indicated
on their respective functions and projected onto the
PROMIS metric. Some of the thresholds for possible
or moderate depression on the CES-D and BDI-II
differ from one another. In fact, the threshold for
moderate depression according to the CES-D (about
0.5 SD above the PROMIS population mean) was
equivalent to the threshold for mild depression by
the BDI-II. However, the thresholds for moderate
depression for the BDI-II and PHQ-9 were very
similar to each other (about 1 SD above the PROMIS
population mean). This is validating the tentative
threshold PROMIS has set on the Depression
measure of 60, or 1 SD above the population mean
(Cella et al., 2008).
記載例2
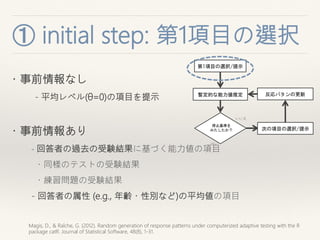
① initial step:第1項目の選
択
Magis, D., & Raîche, G. (2012). Random generation of response patterns under computerized adaptive testing with the R
package catR. Journal of Statistical Software, 48(8), 1-31.
・事前情報なし
- 平均レベル(θ=0)の項目を提示
・事前情報あり
- 回答者の過去の受験結果に基づく能力値の項目
・同様のテストの受験結果
・練習問題の受験結果
- 回答者の属性 (e.g., 年齢・性別など)の平均値の項目
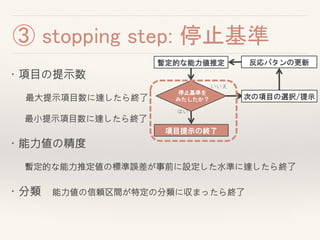
暫定的な能力値推定
次の項目の選択/提示
いいえ
第1項目の選択/提示
停止基準を
みたしたか?
はい
反応パタンの更新
60.
② test step:能力値推定/項目提
示
Magis, D., & Raîche, G. (2012). Random
generation of response patterns under
computerized adaptive testing with the R
package catR. Journal of Statistical
Software, 48(8), 1-31.
(a)直近の提示項目までの回答パタンで暫定的に能力値を推
定
(b)未提示の項目群から,暫定的な能力値と項目選択基準に
基づいて,次の提示項目を選択/提示
(c)反応パタンの更新
暫定的な能力値推定
次の項目の選択/提示
いいえ
第1項目の選択/提示
停止基準を
みたしたか?
はい
反応パタンの更新
Rコード: 等価
❖ plinkpackage
#尺度の等価 (対応表)
conversion<-plink::equate(plink.out,method=c("TSE","OSE"))
ose_scores<-data.frame(conversion$ose$scores)
tse_scores<-data.frame(conversion$tse)
tse_scores
#尺度スコア(等価後)のプロット
plot(tse_scores[,2],tse_scores[,3], type="l",xlab="T(θ) for form
X",ylab= "T(θ) for form Y",ylim=c(0,14))
Rコード: 適応型テストの運用#質問項目と回答フォーマットの作成
nitems<-29 #項目バンクの項目数
questions<-character(nitems) #質問項目を入れる箱
questions<-c("過去一週間に, 怖い思いをした (I felt frightened)","過去一週間に,ゾッとした (I felt frightened)",
"過去一週間に,緊張した時に怖かった (It scared me when I felt nervous)",
"過去一週間に,不安を感じた (I felt anxious)",
"過去一週間に,自分の不安のために助けが必要だと感じた (I felt like I needed help for my anxiety)",
"過去一週間に,自分の精神的な健康が気になった (I was concerned about my mental health)",
"過去一週間に,動揺した (I felt upset)","過去一週間に, 動悸があった (I had a racing or pounding heart)",
"過去一週間に, 普段していることが妨げられると不安になった (I was anxious if my normal routine was disturbed)",
"過去一週間に,突然にパニックを感じることがあった (I had sudden feelings of panic)",
"過去一週間に,ちょっとしたことにビクビクした (I was easily startled)",
"過去一週間に,物事に集中することが難しかった (I had trouble paying attention)",
"過去一週間に, 公共の場や(公共での)活動を避けた (I avoided public places or activities)",
"過去一週間に,落ち着かなかった (I felt fidgety)",
"過去一週間に,何か恐ろしいことが起こる感じがした (I felt something awful would happen)",
"過去一週間に, 心配を感じた (I felt worried)",
"過去一週間に,ひどく恐ろしい思いをした (I felt terrified)",
"過去一週間に, 私に対する他者の反応について心配した (I worried about other people's reaction to me)",
"過去一週間に, 自分の不安なこと以外の全てのことに集中することは難しかった。(I found it hard to focus on anything other than my
anxiety)",
"過去一週間に, 心配事に圧倒された (my worries overwhelmed me)",
"過去一週間に, 筋肉の痙攣やこわばりがあった (I had twitching or trembling muscles)",
"過去一週間に, 緊張した/神経質になった (I felt nervous)",
"過去一週間に, 優柔不断だった (I felt indecisive)",
"過去一週間に,さまざまな状況で心配になった (Many situations made me worry)",
"過去一週間に, よく眠れなかった (I had difficulty sleeping)",
"過去一週間に, リラックスするのが難しかった (I had trouble relaxing)",
"過去一週間に, 落ち着かなかった (I felt uneasy)",
"過去一週間に, 緊張した (I felt tense)",
"過去一週間に, 穏やかにいることが難しかった (I had difficulty calming down)”)
choices <- matrix('', nitems, 5) #回答フォーマットを入れる箱
for(i in 1:nitems){ #回答フォーマットを入れる箱に回答フォーマットを格納
choices[i,] <-c("全くない","たまに","しばしば","よく", "いつも")
}
df <- data.frame(Questions=questions, Option=choices, Type='radio')





![IRTに基づく尺度構成/運用のメリット
異質な集団間の得点を比較可能
異なる尺度間の得点を比較可能
測定精度を詳細に確認可能
特性値に応じて実施する尺度を制御可能
受験者ごとに最適な問題を瞬時に選び出題できる
豊田 (2012) 項目反応理論 [入門編] 第二版 朝倉書店](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-6-320.jpg)




![pj (qi ) =
exp[Daj (qi -bj )]
1+exp[Daj (qi -bj )]
回答が2値変数のモデル
❖ 2母数ロジスティックモデル
θ = 特性値
ability parameter
a = 識別度母数
discrimination parameter
b = 困難度母数
difficulty or location parameter
D = 1.7 (定数)
constant
ある特性値の人(θi)がある項目(j)に
「はい」と答える確率
「はい(1)」「いいえ(0)」
「正答 (1)」「誤答 (0)」](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-11-320.jpg)

![回答が順序変数のモデル
❖ 段階反応モデル
p*j (qi ) =
exp[Daj (qi -b*j )]
1+exp[Daj (qi -b*j )]
「あてはまる(4)」「少しあてはまる(3)」
「どちらでもない (2)」「あまりあてはまらない (1)」
「全然あてはまらない (0)」
ある特性値で,あるカテゴリに回答する
カテゴリごとの確率
回答カテゴリごとの困難度
θ = 特性値
ability parameter
a = 識別度母数
discrimination parameter
b = 困難度母数
difficulty or location parameter](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-13-320.jpg)
![回答が順序変数のモデル
❖ 段階反応モデル
「あてはまる(4)」「少しあてはまる(3)」
「どちらでもない (2)」「あまりあてはまらない (1)」
「全然あてはまらない (0)」
a = 識別度母数 b = 困難度母数
項目特性曲線の傾き 項目特性曲線の切片
豊田 (2012) 項目反応理論 [入門編] 第二版 朝倉書店
a=1.2, b1=3, b2=0, b3=-3 a=2.4, b1=3, b2=0, b3=-3 a=1.2, b1=3, b2=0, b3=-3 a=1.2, b1=5, b2=2, b3=-1](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-14-320.jpg)
![mirtパッケージのアプリ機能
library(mirt)
data(Anxiety)#lordifパッケージ内のデータ
res<-mirt(Anxiety[,4:32], 1)
itemplot(res, shiny=T)
スライダーでパラメタを動かすと、
一緒にプロットが動くので、
項目母数の性質が良く分かる](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-15-320.jpg)












![記載例2
❖ 方法の節: IRTOLSの場合
Qual Life Res (2015) 24:1491–1501 DOI 10.1007/s11136-014-0870-
DIF was analyzed with the R software package Lordif [31]. The
Lordif utilizes an ordinal logistic regression framework, and the
graded response (GR) model is used for IRT trait estimation
[32]. Two criteria were considered to detect meaningful DIF in the
current study: (1) < 0.13 pseudo R2 statistic [33] and (2) 10 %
changes in beta [31, 34, 35].
もっと詳しく書くなら右も参考になる→
使用したソフトウェア
DIF検出に用いた統計モデル
IRTの特性値の推定に使用した統計モデル
DIFの検出基準
Qual Life Res (2014) 23:239–244](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-29-320.jpg)

![記載例1
❖ 方法の節: MIMIC model
❖ 結果の節: MIMIC model
Another important assumption of CCFA is no differential item functioning (DIF). This assumption was
tested for each item of the two PROMIS measures using the multiple indicator multiple cause
(MIMIC) model [25 –28], in regard to gender and age, each adjusted for the other. The MIMIC model
enables examining DIF even for a continuous variable (e.g., age) that has small within-group sample
sizes [25 ]. Significant direct effect of a grouping variable (e.g., age, gender) on an item indicates
DIF of the item. A DIF implies that a given item was not interpreted in a conceptually similar manner by
respondents with different individual characteristics (e.g., age and gender).
As the DIF tests for all the items were
conducted simultaneously, there was no need
to make adjustment for multiplicity of
comparison. None of the DIF tests were
statistically significant.](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-31-320.jpg)




































![Rコード: 特異項目機能
❖ 順序ロジスティックモデル: Lordif
packagelibrary(lordif) #パッケージの読み込み
data(“Anxiety”) #データの読み込み
head(Anxiety) #データ構造の確認
Age <- Anxiety$age #性別変数の格納
Resp <- Anxiety[paste("R", 1:29, sep = "")] #項目変数の格納](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-70-320.jpg)




![Rコード: 等価
❖ plink package
#データの読み込み
formX<-read.csv("Xdat.csv",header=T)
formY<-read.csv("Ydat.csv",header=T)
#各尺度IRTパラメータの推定
library(ltm)
X_irt<-grm(formX[,2:21], IRT.param = TRUE)
Y_irt<-grm(formY[,2:8], IRT.param = TRUE)
#linking
library(devtools)
#plinkはcranにないのでgithubからインストール
install_github("cran/plink")
library(plink)
#ltmによる推定結果を読み込み
X<-read.ltm(X_irt)
Y<-read.ltm(Y_irt)
#共通項目を指定
common<-matrix(0,7,2)
common[,1:2]<-1:7
colnames(common)<-c("form.X","form.Y”)"
#共通項目を指定
plink.pars <- combine.pars(list(form.Y=X, form.X=Y),
common = common)
#Stock-lord法で等価
plink.out <- plink(plink.pars, rescale = "SL",D=1.7,
grp.names=c("form.X","form.Y"))
#等価係数の出力
summary(plink.out)](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-75-320.jpg)

![Rコード: 等価
❖ plink package
#尺度の等価 (対応表)
conversion<-plink::equate(plink.out,method=c("TSE","OSE"))
ose_scores<-data.frame(conversion$ose$scores)
tse_scores<-data.frame(conversion$tse)
tse_scores
#尺度スコア(等価後)のプロット
plot(tse_scores[,2],tse_scores[,3], type="l",xlab="T(θ) for form
X",ylab= "T(θ) for form Y",ylim=c(0,14))](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-77-320.jpg)
![Rコード: 適応型テストの運用
❖ mirt package
library(mirtCAT)
options(stringsAsFactors = FALSE)
# 項目バンクのパラメータ推定
library(lordif)
data("Anxiety") #lordif packageのデータ
mod<-mirt(Anxiety[,4:32],1)
質問文と回答フォーマットのデータフレームを作る](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-78-320.jpg)
![Rコード: 適応型テストの運用#質問項目と回答フォーマットの作成
nitems<-29 #項目バンクの項目数
questions <-character(nitems) #質問項目を入れる箱
questions<-c("過去一週間に, 怖い思いをした (I felt frightened)","過去一週間に,ゾッとした (I felt frightened)",
"過去一週間に,緊張した時に怖かった (It scared me when I felt nervous)",
"過去一週間に,不安を感じた (I felt anxious)",
"過去一週間に,自分の不安のために助けが必要だと感じた (I felt like I needed help for my anxiety)",
"過去一週間に,自分の精神的な健康が気になった (I was concerned about my mental health)",
"過去一週間に,動揺した (I felt upset)","過去一週間に, 動悸があった (I had a racing or pounding heart)",
"過去一週間に, 普段していることが妨げられると不安になった (I was anxious if my normal routine was disturbed)",
"過去一週間に,突然にパニックを感じることがあった (I had sudden feelings of panic)",
"過去一週間に,ちょっとしたことにビクビクした (I was easily startled)",
"過去一週間に,物事に集中することが難しかった (I had trouble paying attention)",
"過去一週間に, 公共の場や(公共での)活動を避けた (I avoided public places or activities)",
"過去一週間に,落ち着かなかった (I felt fidgety)",
"過去一週間に,何か恐ろしいことが起こる感じがした (I felt something awful would happen)",
"過去一週間に, 心配を感じた (I felt worried)",
"過去一週間に,ひどく恐ろしい思いをした (I felt terrified)",
"過去一週間に, 私に対する他者の反応について心配した (I worried about other people's reaction to me)",
"過去一週間に, 自分の不安なこと以外の全てのことに集中することは難しかった。(I found it hard to focus on anything other than my
anxiety)",
"過去一週間に, 心配事に圧倒された (my worries overwhelmed me)",
"過去一週間に, 筋肉の痙攣やこわばりがあった (I had twitching or trembling muscles)",
"過去一週間に, 緊張した/神経質になった (I felt nervous)",
"過去一週間に, 優柔不断だった (I felt indecisive)",
"過去一週間に,さまざまな状況で心配になった (Many situations made me worry)",
"過去一週間に, よく眠れなかった (I had difficulty sleeping)",
"過去一週間に, リラックスするのが難しかった (I had trouble relaxing)",
"過去一週間に, 落ち着かなかった (I felt uneasy)",
"過去一週間に, 緊張した (I felt tense)",
"過去一週間に, 穏やかにいることが難しかった (I had difficulty calming down)”)
choices <- matrix('', nitems, 5) #回答フォーマットを入れる箱
for(i in 1:nitems){ #回答フォーマットを入れる箱に回答フォーマットを格納
choices[i,] <-c("全くない","たまに","しばしば","よく", "いつも")
}
df <- data.frame(Questions=questions, Option=choices, Type='radio')](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-79-320.jpg)


![Rコード: 適応型テストの運用
summary(res)
res<-round(print(result),2)
# 推定値から標準得点算出 (θ*10+50)
res<-cbind(res,summary(result)$final_estimates[1]*10+50)
colnames(res)[4]<-"T-score"
colnames(res)<-c("Answered items","θ","θ.SE","T-score")
res
plot(result)](https://image.slidesharecdn.com/require0725takebayashipres-150725120516-lva1-app6891/85/slide-82-320.jpg)































































