Downloaded 33 times
![[course site]
Javier Ruiz Hidalgo
javier.ruiz@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Methodology
Day 6 Lecture 2
#DLUPC](https://image.slidesharecdn.com/dlai2017d6l2methodology-171113090926/85/Methodology-DLAI-D6L2-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-320.jpg)
![[course site]
Javier Ruiz Hidalgo
javier.ruiz@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Methodology
Day 6 Lecture 2
#DLUPC](https://image.slidesharecdn.com/dlai2017d6l2methodology-171113090926/75/Methodology-DLAI-D6L2-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-2048.jpg)



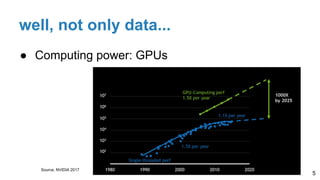

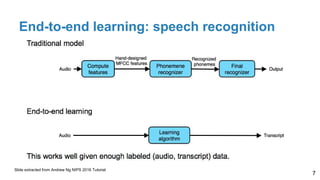
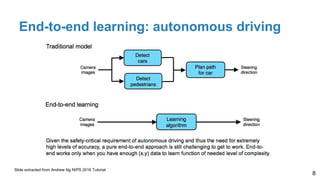




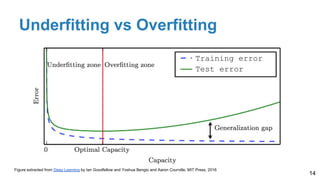
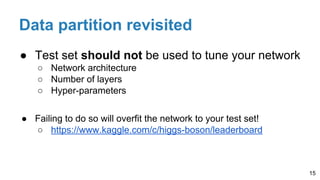




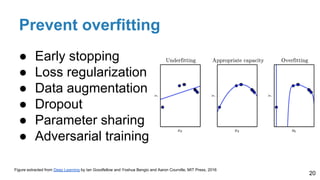
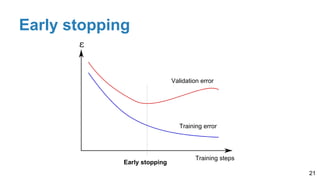
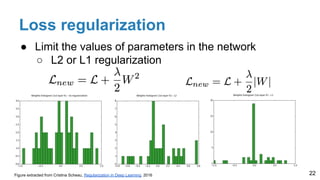




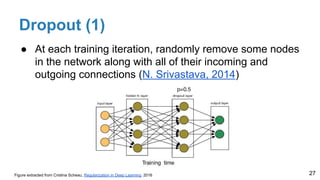
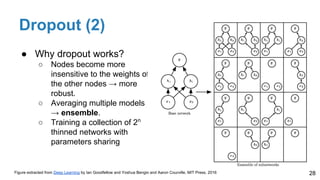
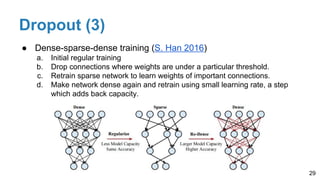
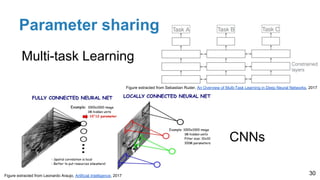

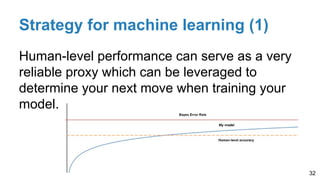
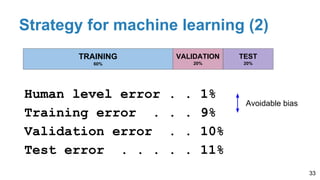


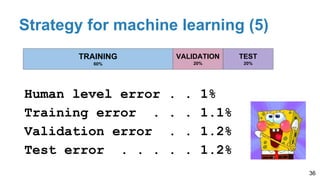
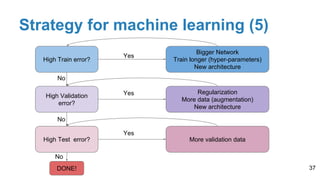



The document is a lecture outline by Javier Ruiz Hidalgo on deep learning methodologies, focusing on data partitioning for training, validation, and testing, alongside strategies to prevent overfitting. It discusses the importance of network capacity, generalization, and techniques such as dropout, early stopping, and data augmentation. Additionally, it highlights the necessity of appropriate data handling to avoid biases and ensure accurate predictions in machine learning models.
















![[PR12] PR-063: Peephole predicting network performance before training](https://cdn.slidesharecdn.com/ss_thumbnails/peepholepredictingnetworkperformance-180130162632-thumbnail.jpg?width=640&height=640&fit=bounds)




































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
