Download as PDF, PPTX















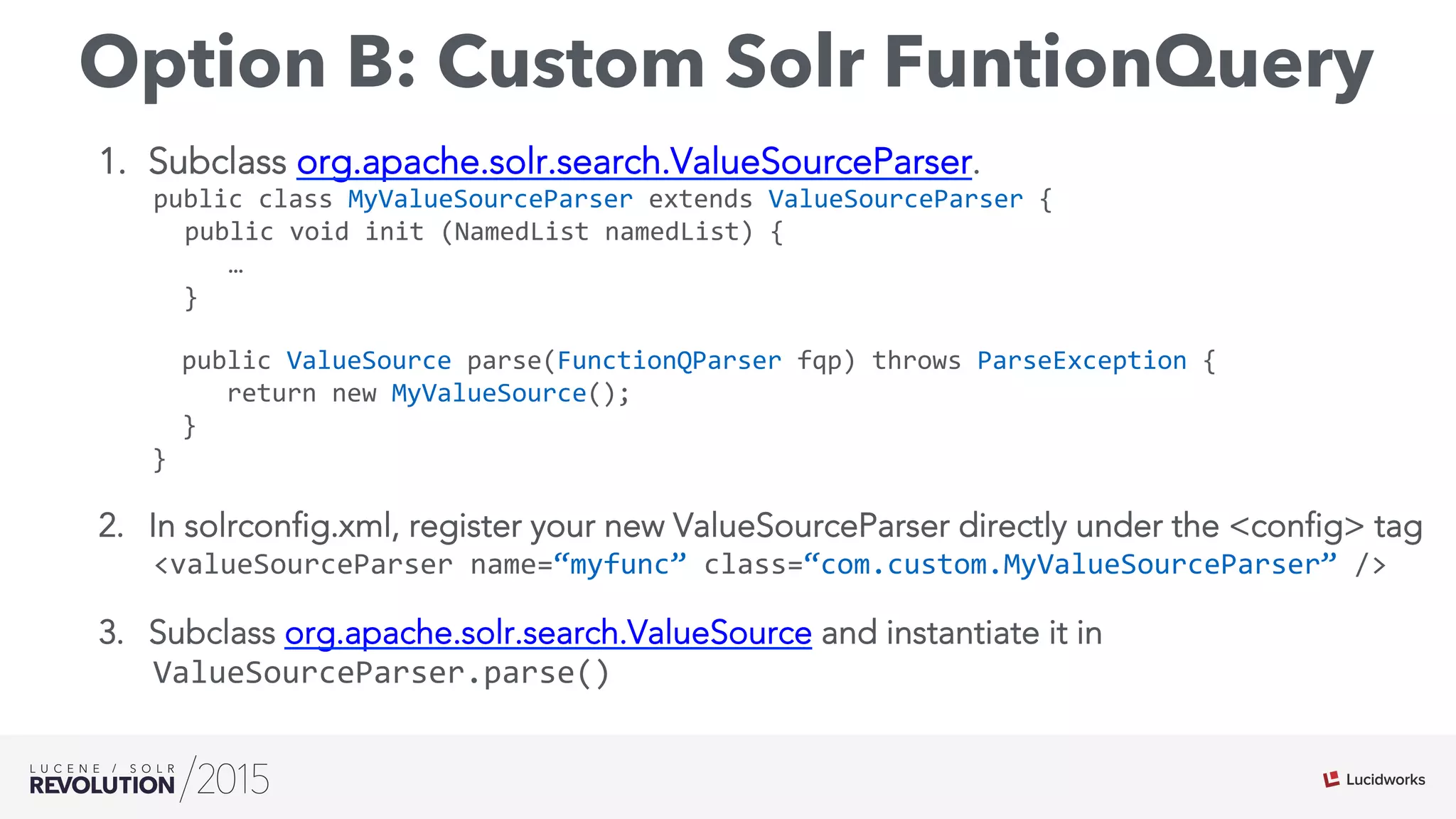




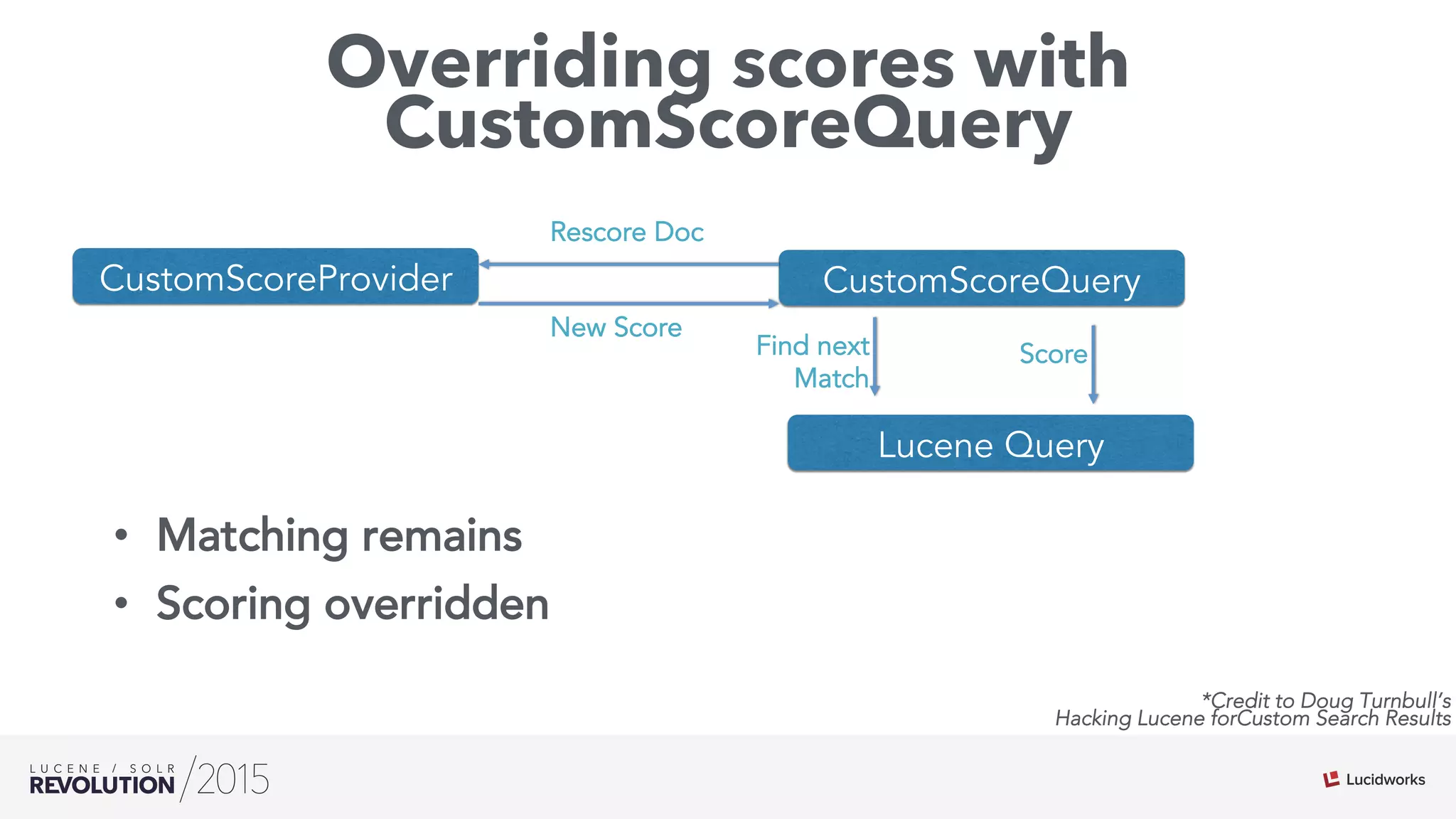

![Implementing CustomScoreQuery
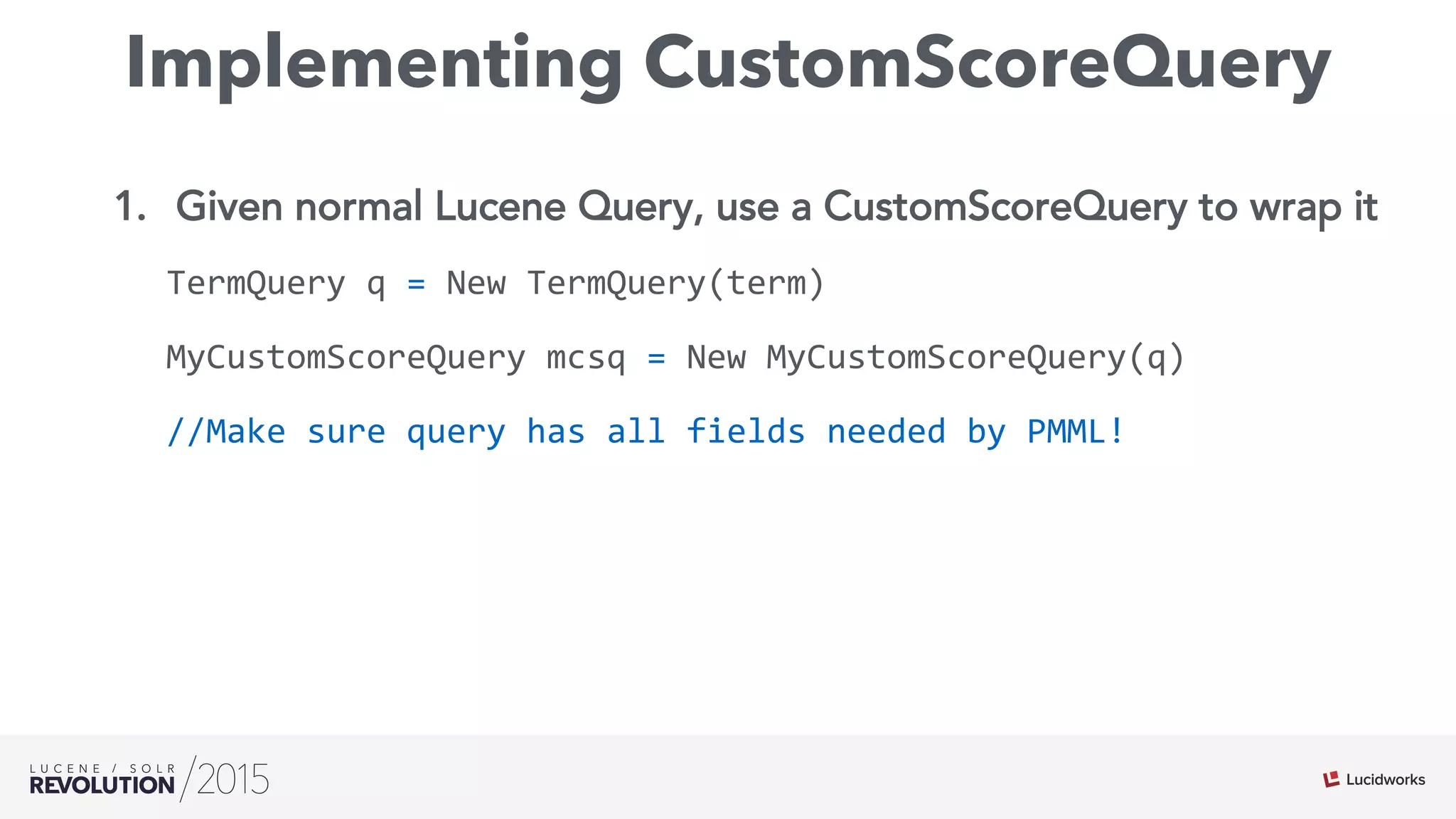
2. Rescore each doc with IndexReader and docID
public
float
customScore(int
doc,
float
subQueryScore,
float
valSrcScores[])
throws
IOException
{
//Lucene
reader
IndexReader
r
=
context.reader();
Terms
tv
=
r.getTermVector(doc,
_field);
TermsEnum
tenum
=
null;
tenum
=
tv.iterator(tenum);
//convert
the
iterator
order
to
fields
needed
by
model
TermsEnum
tenumPMML
=
tenum2PMML(tenum,
evaluator.getActiveFields());](https://image.slidesharecdn.com/rev2015hudelgadofinal-151015220607-lva1-app6892/75/Lucene-Solr-Revolution-2015-Where-Search-Meets-Machine-Learning-43-2048.jpg)



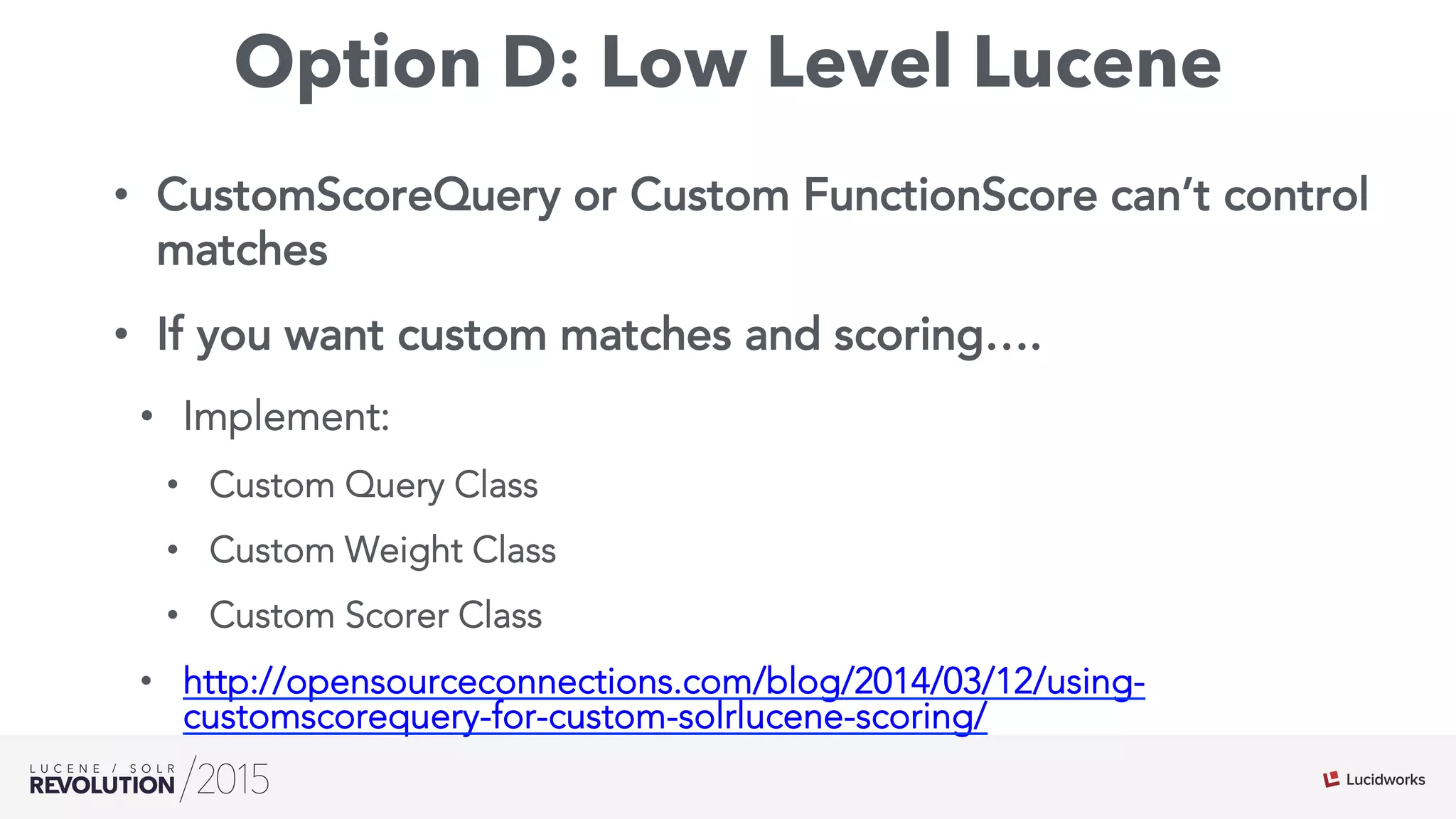





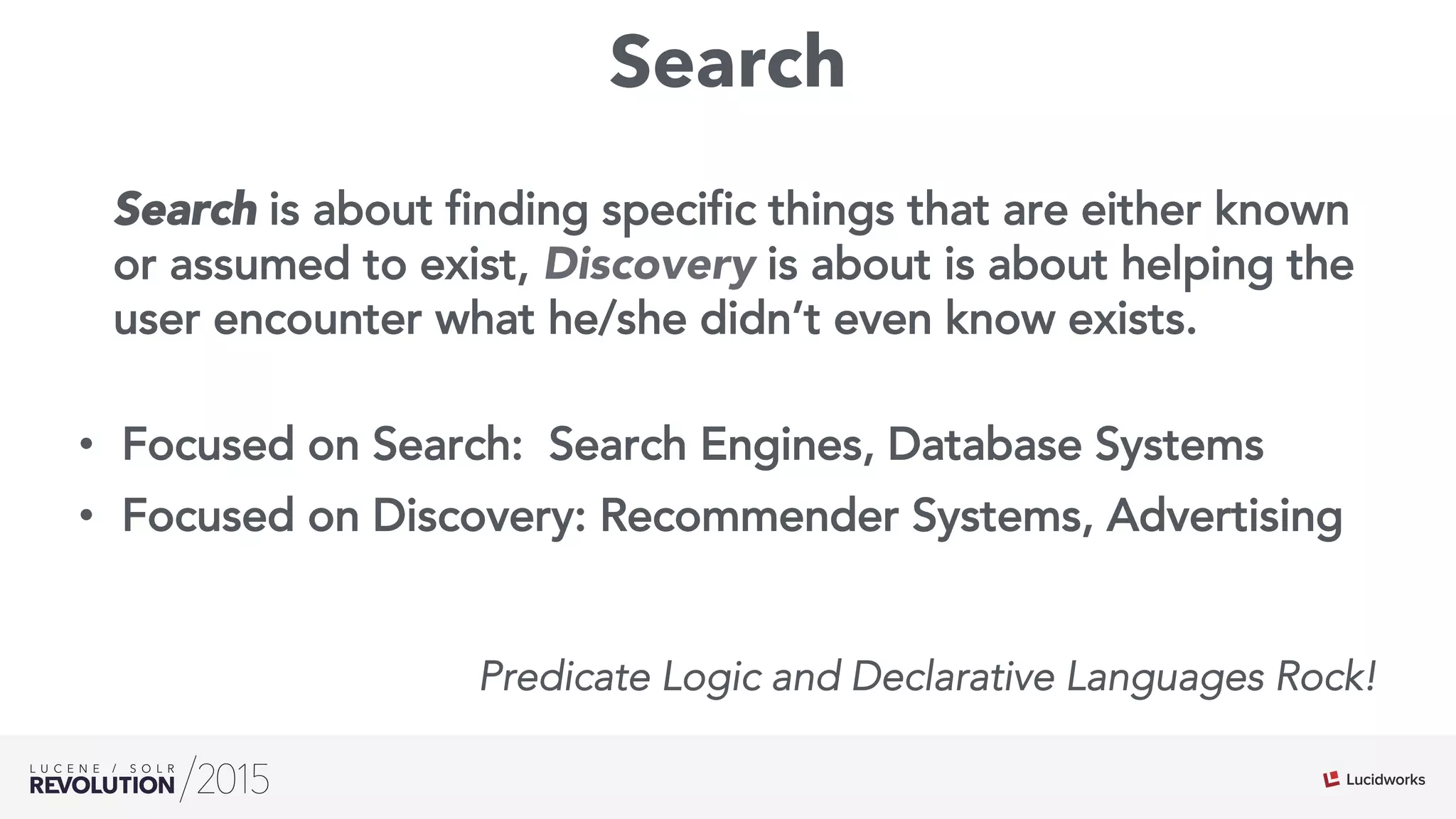
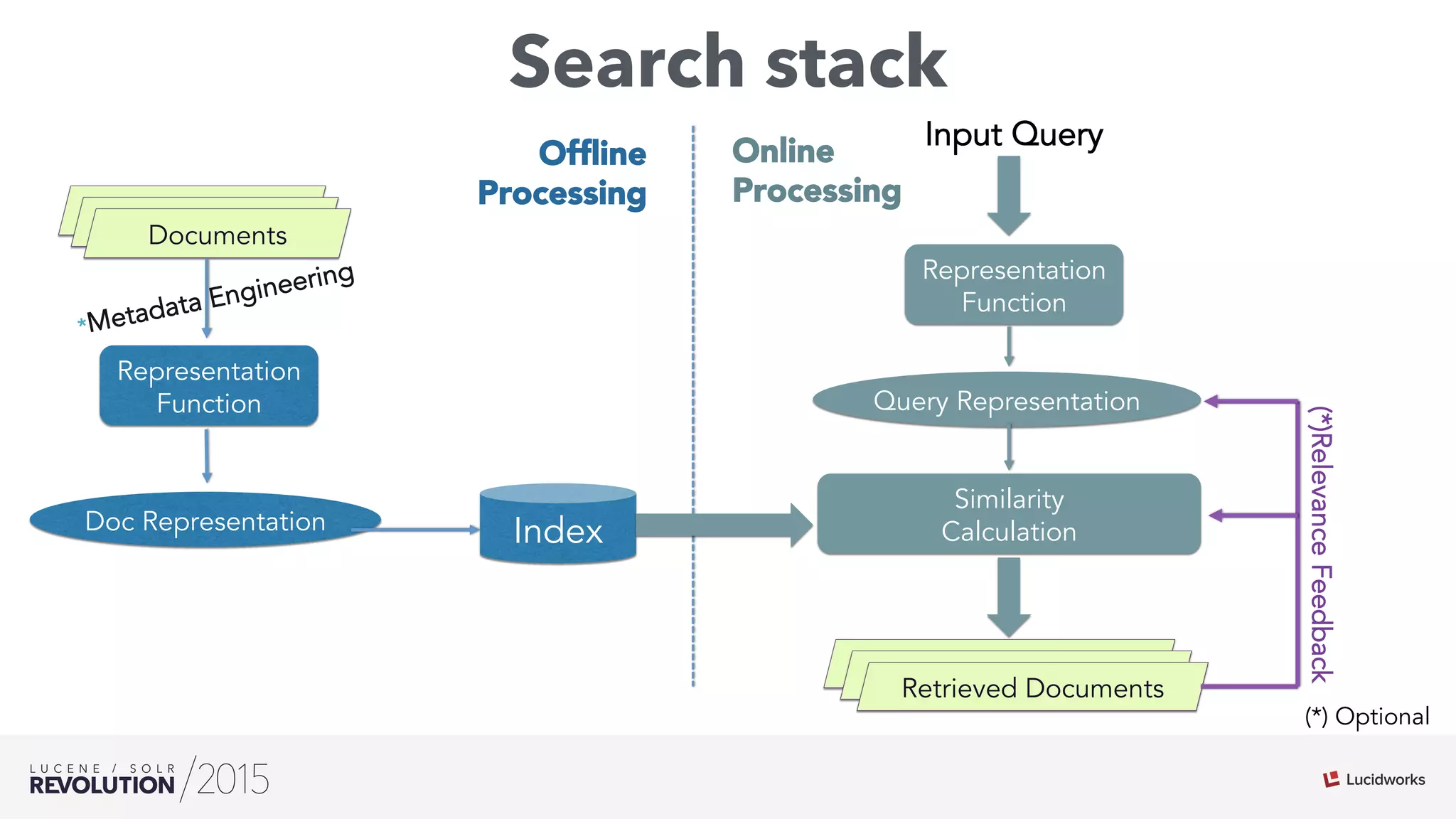
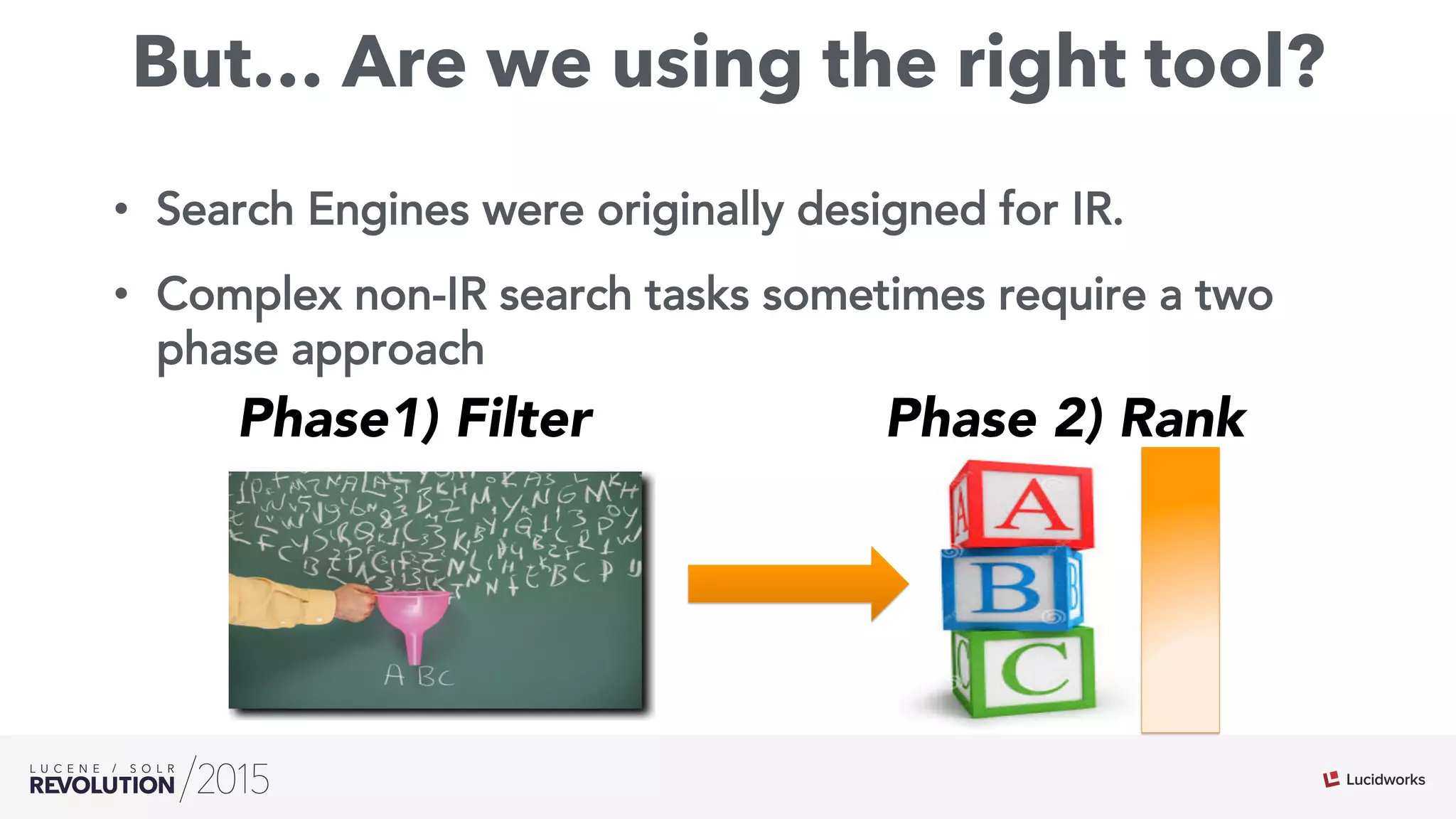
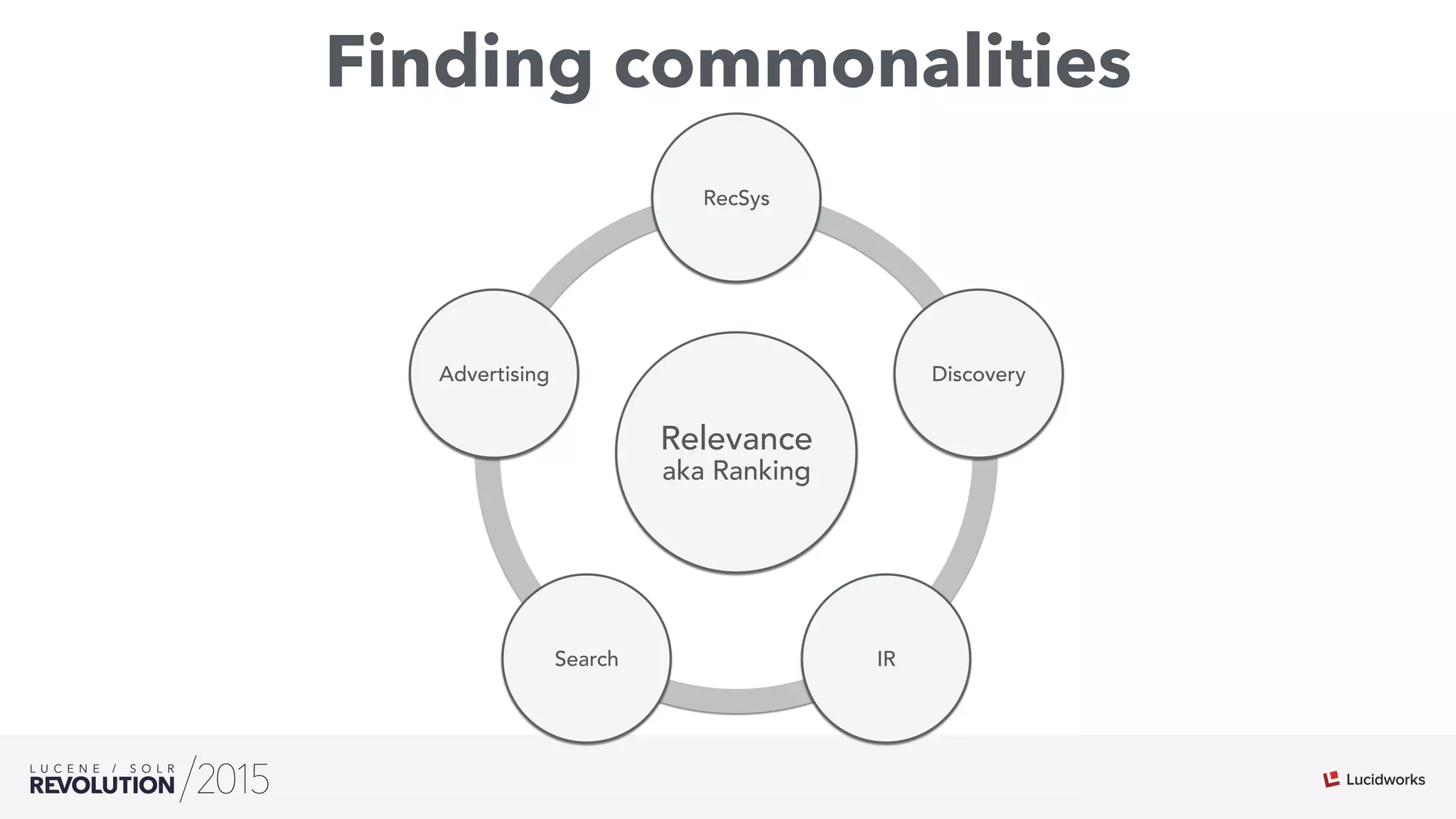
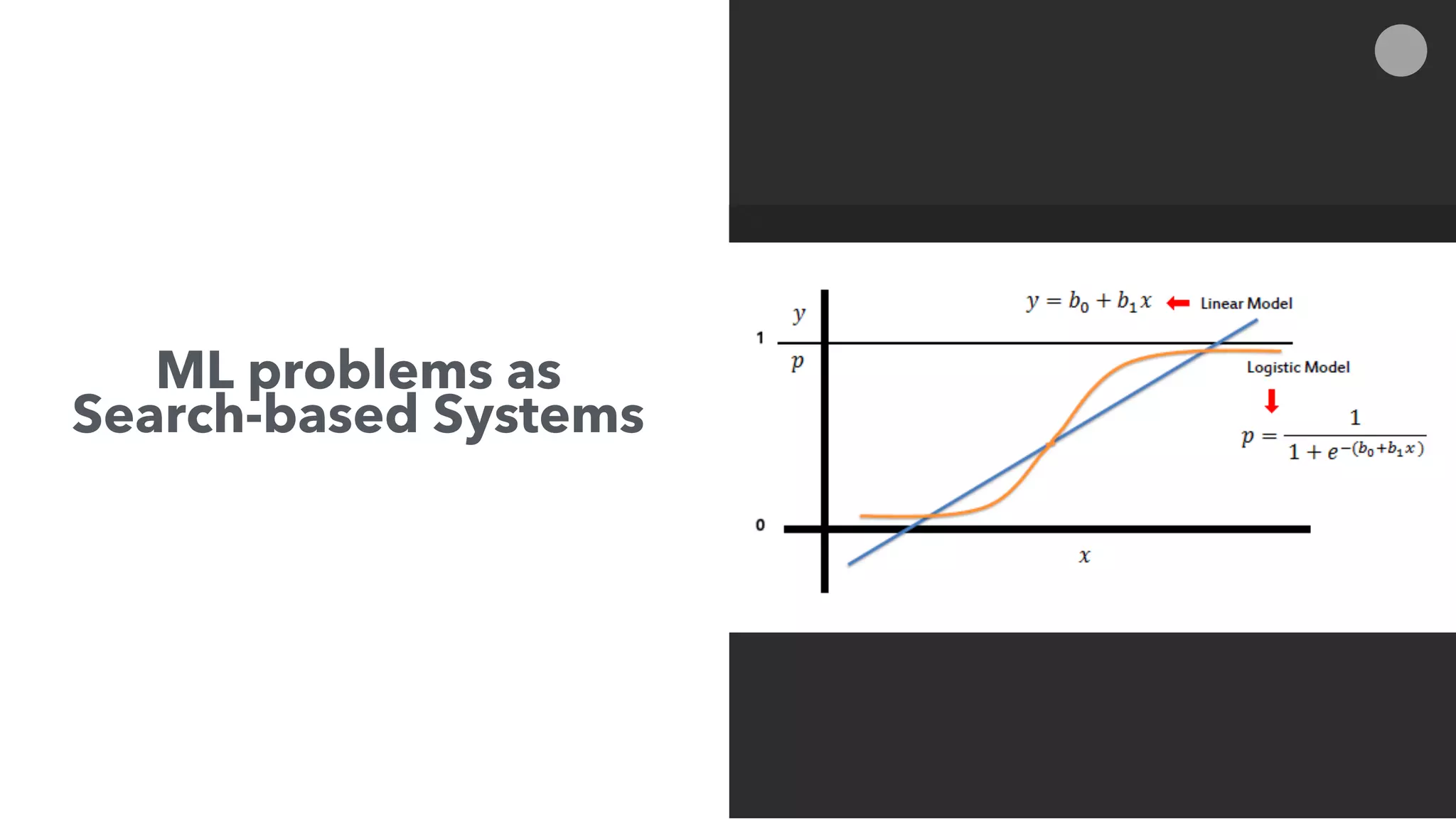
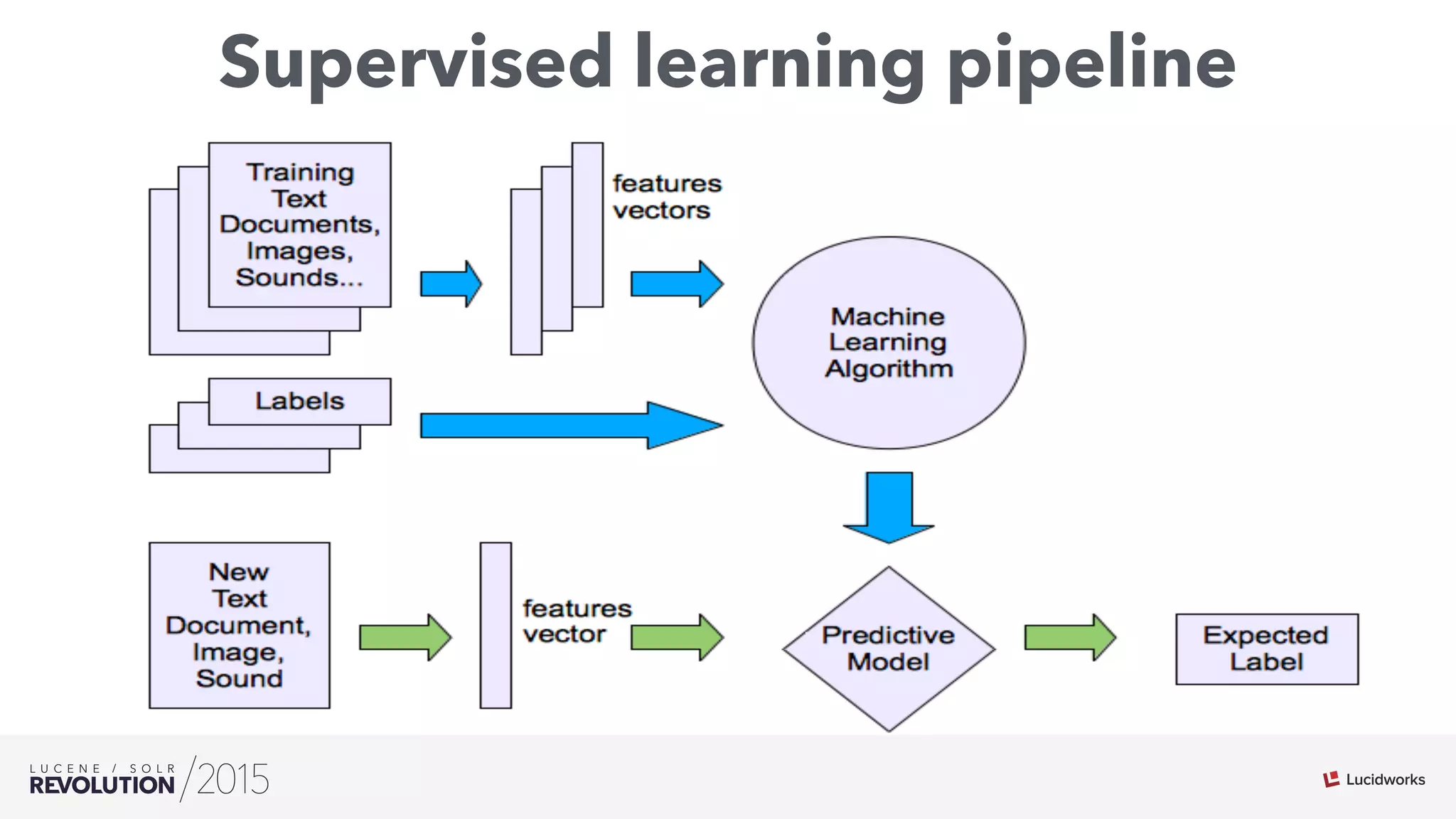
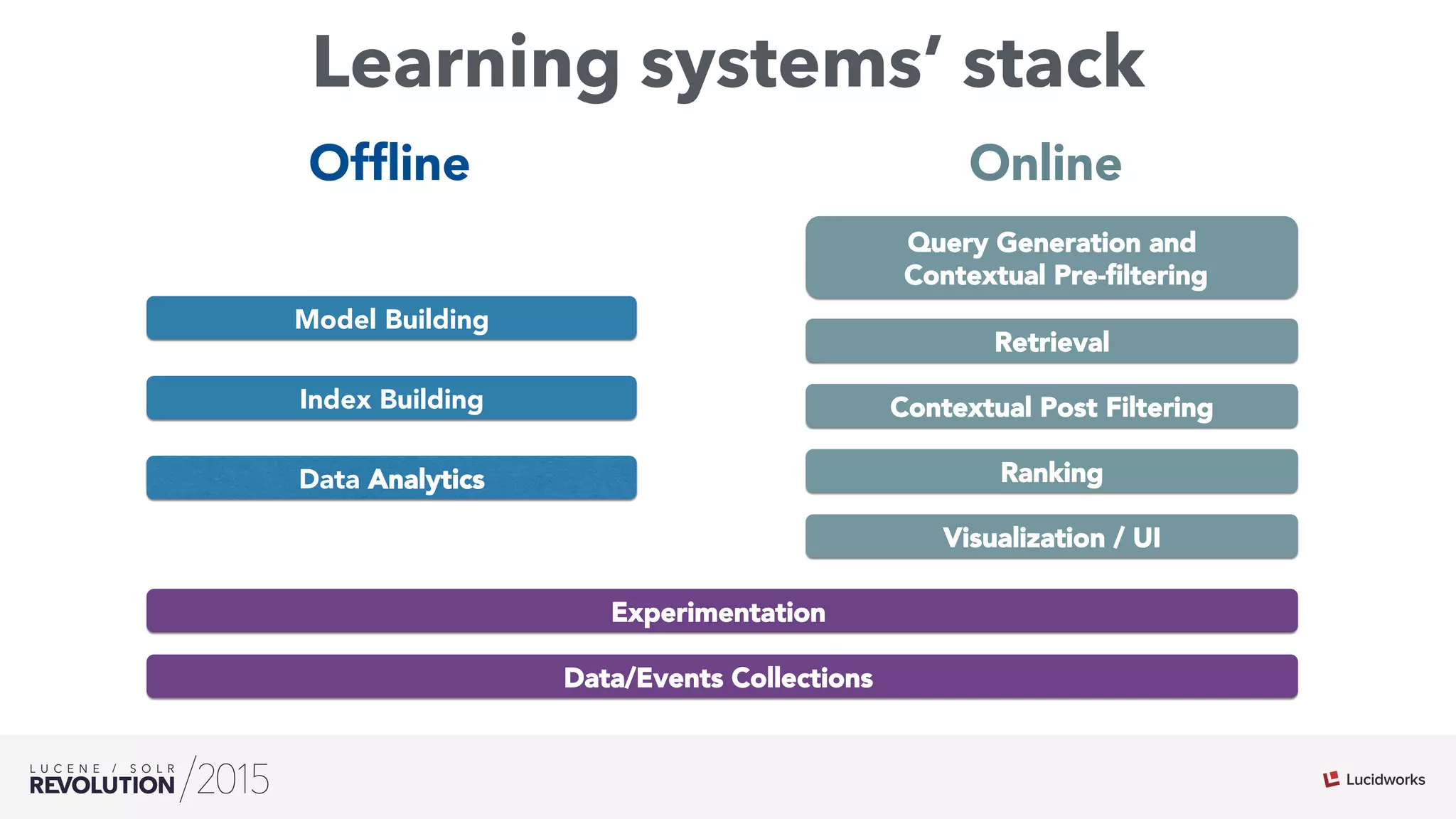
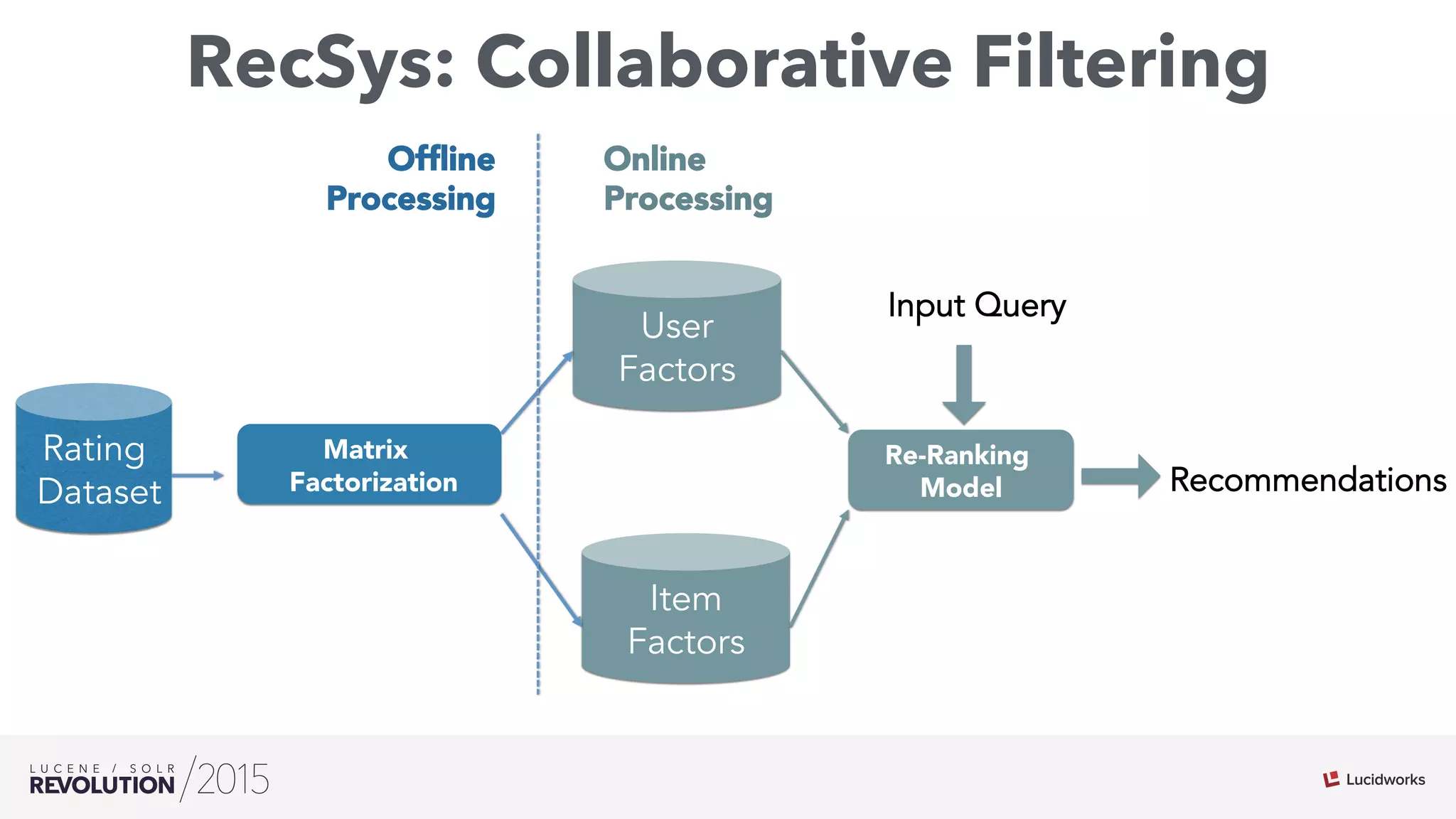
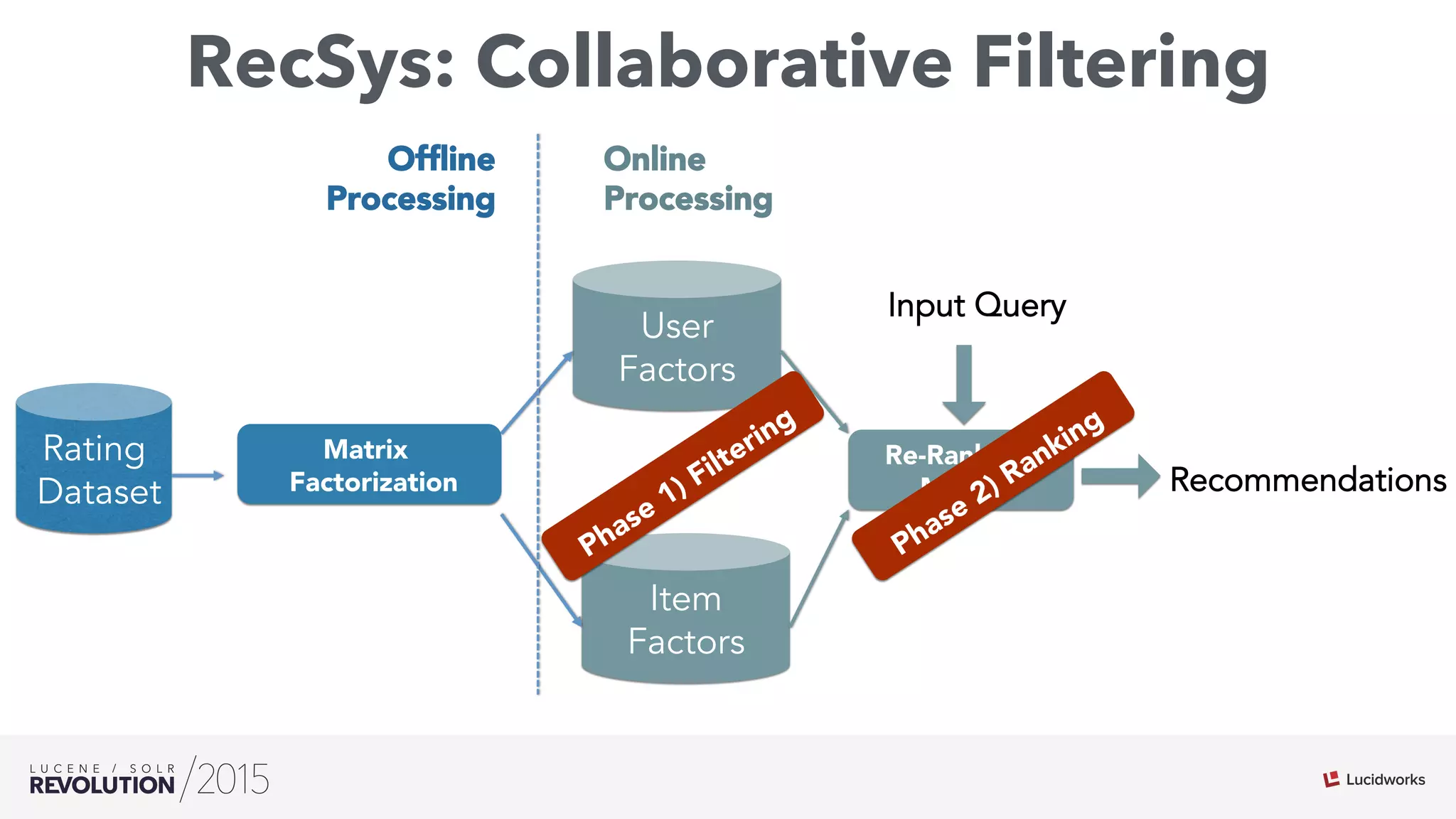
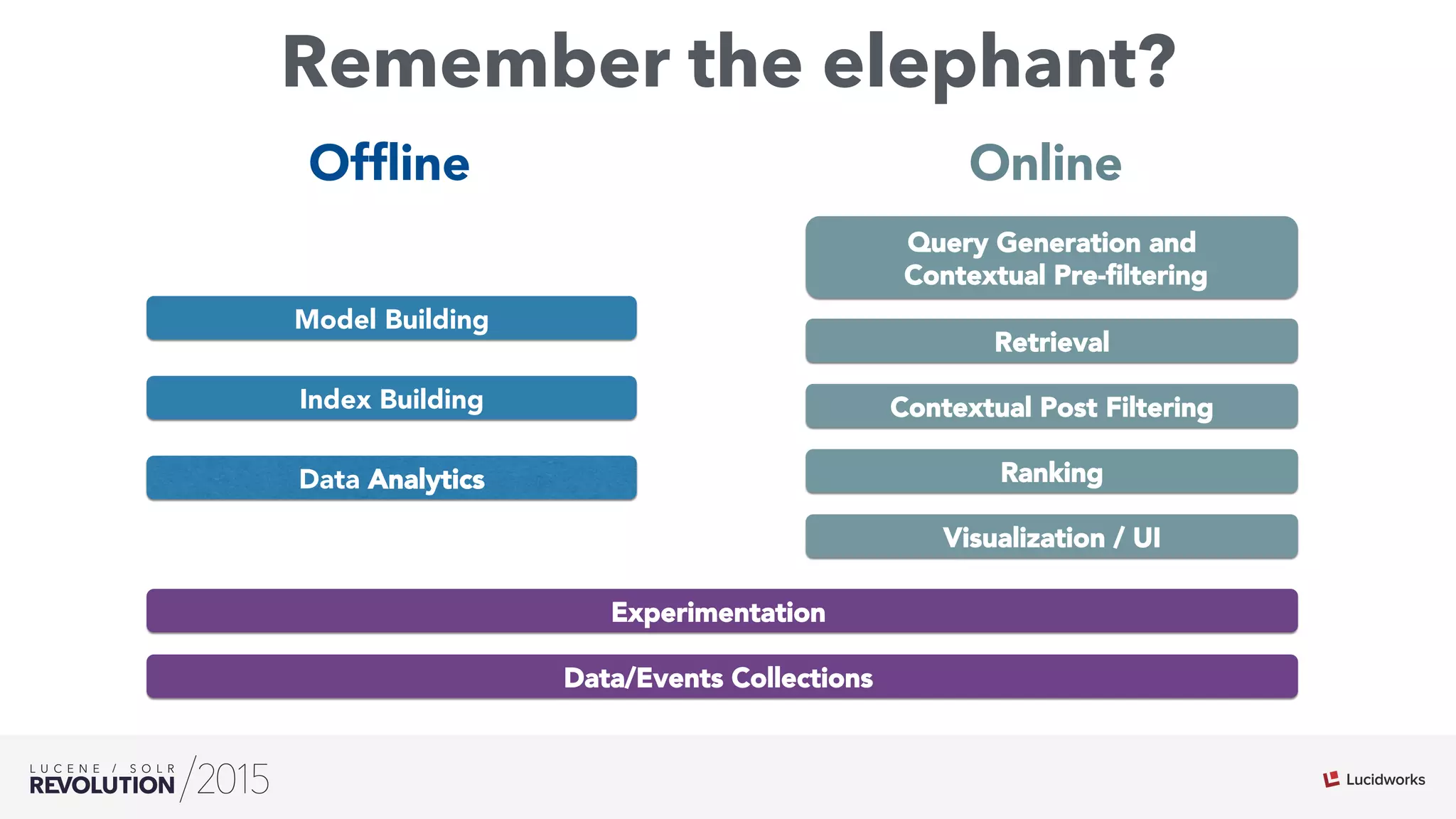
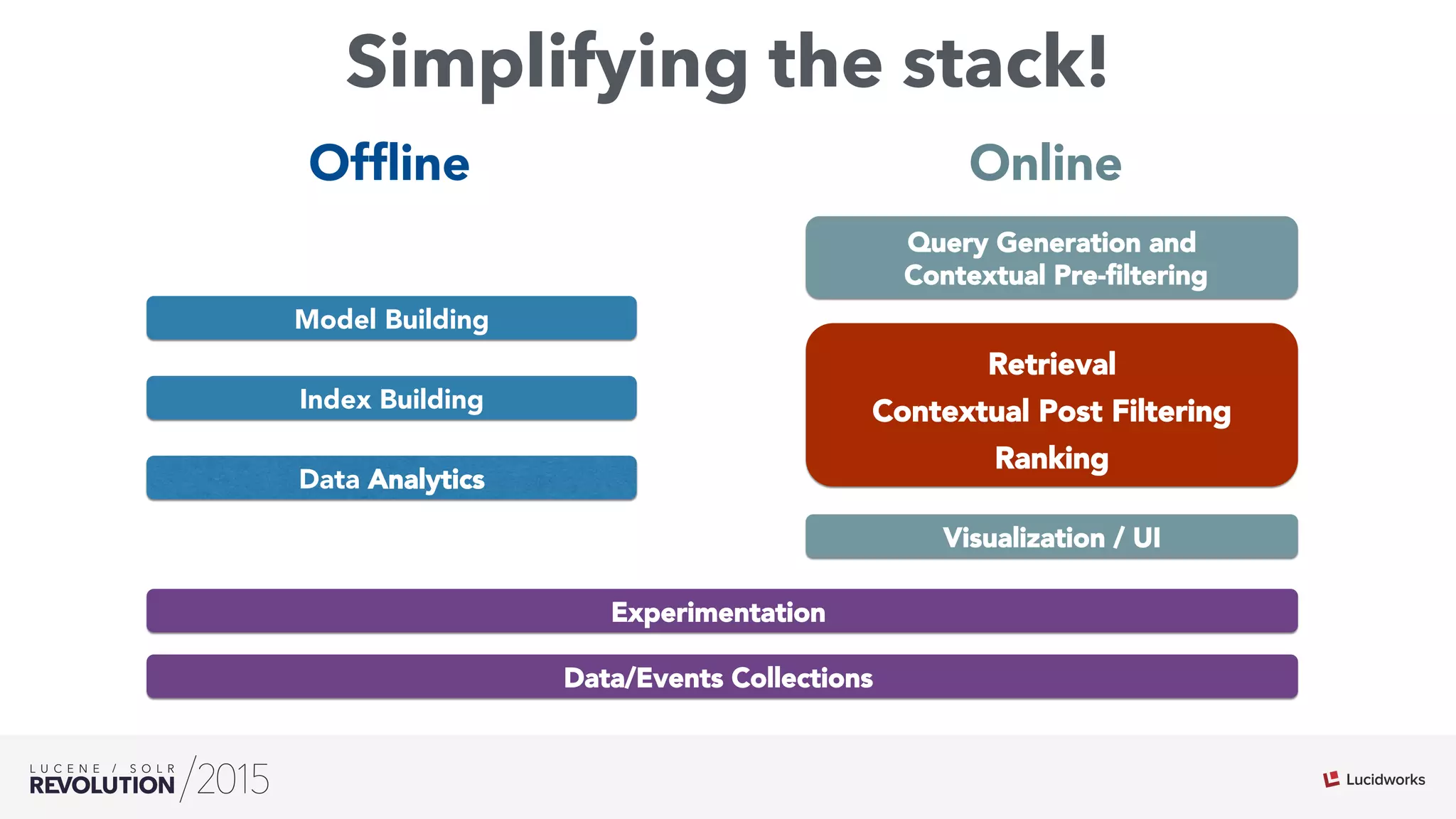
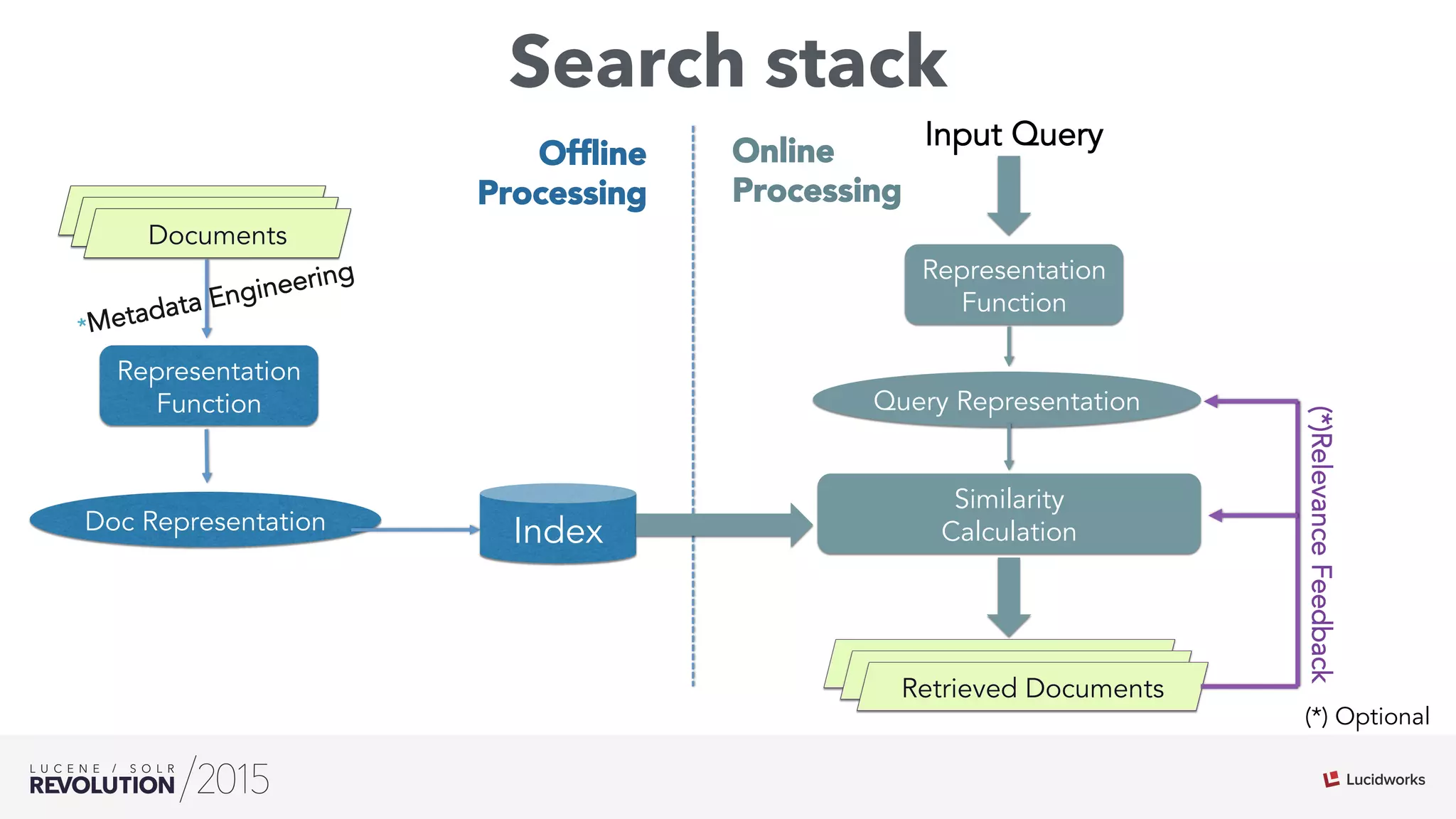
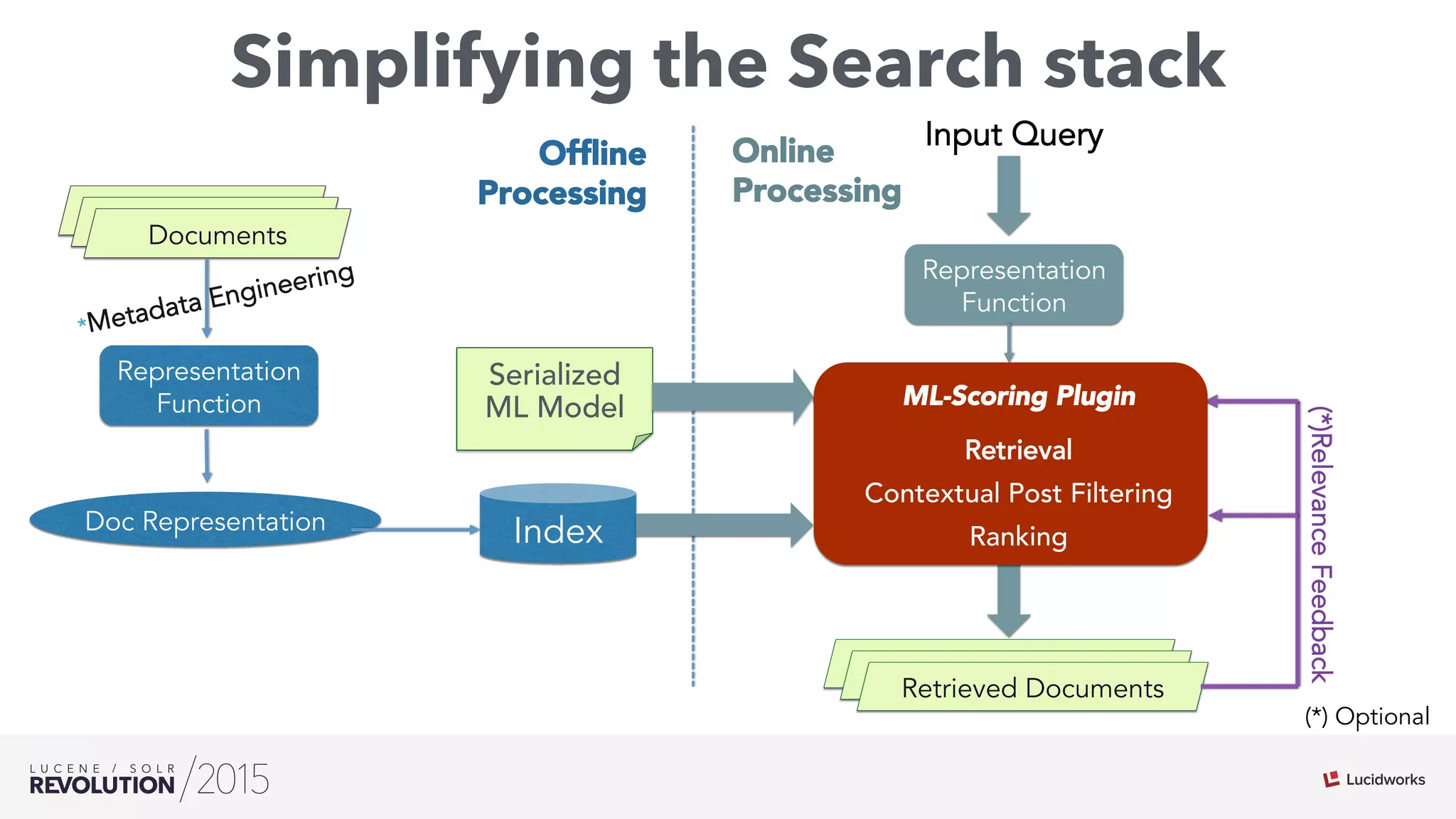
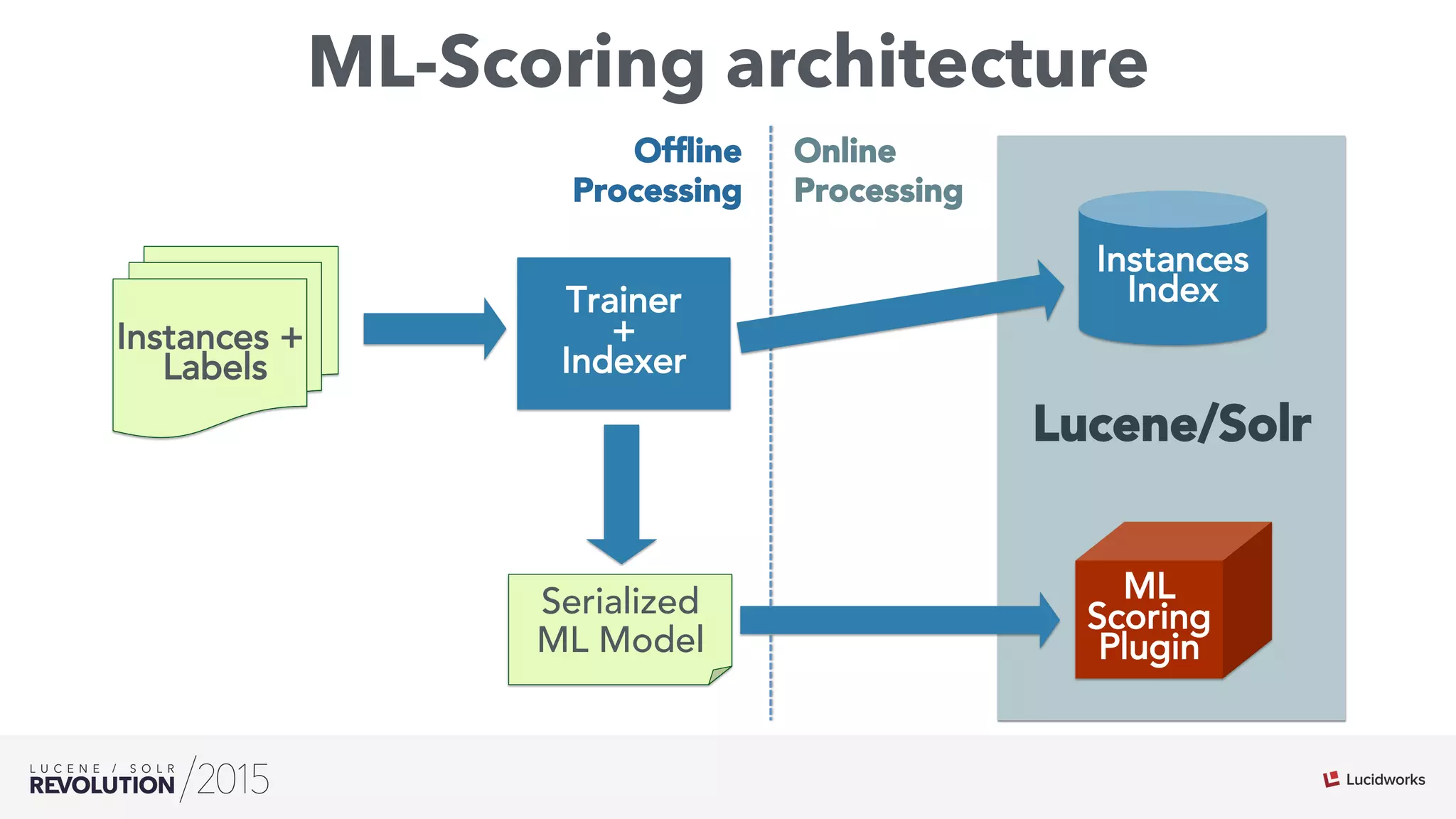
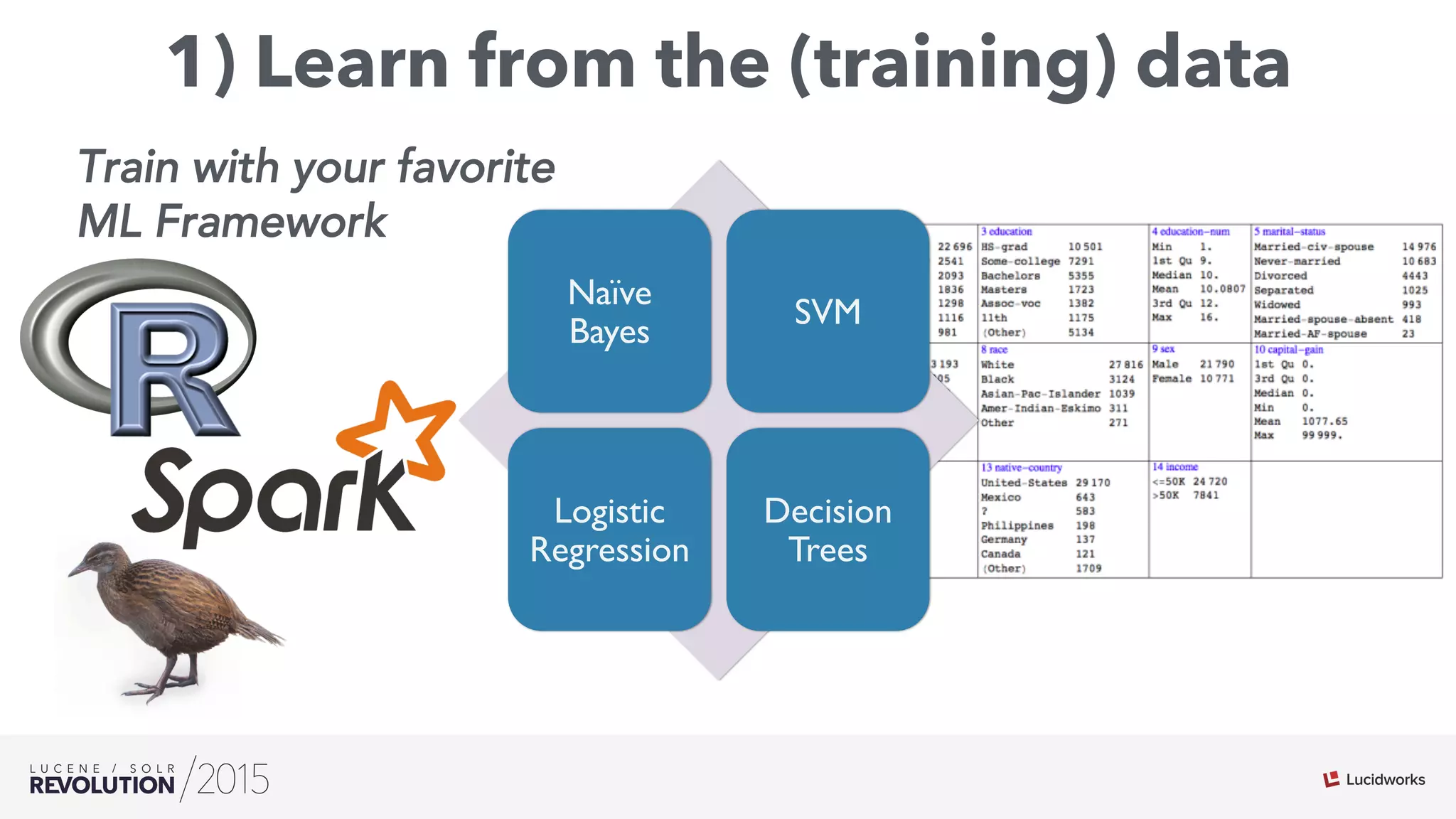
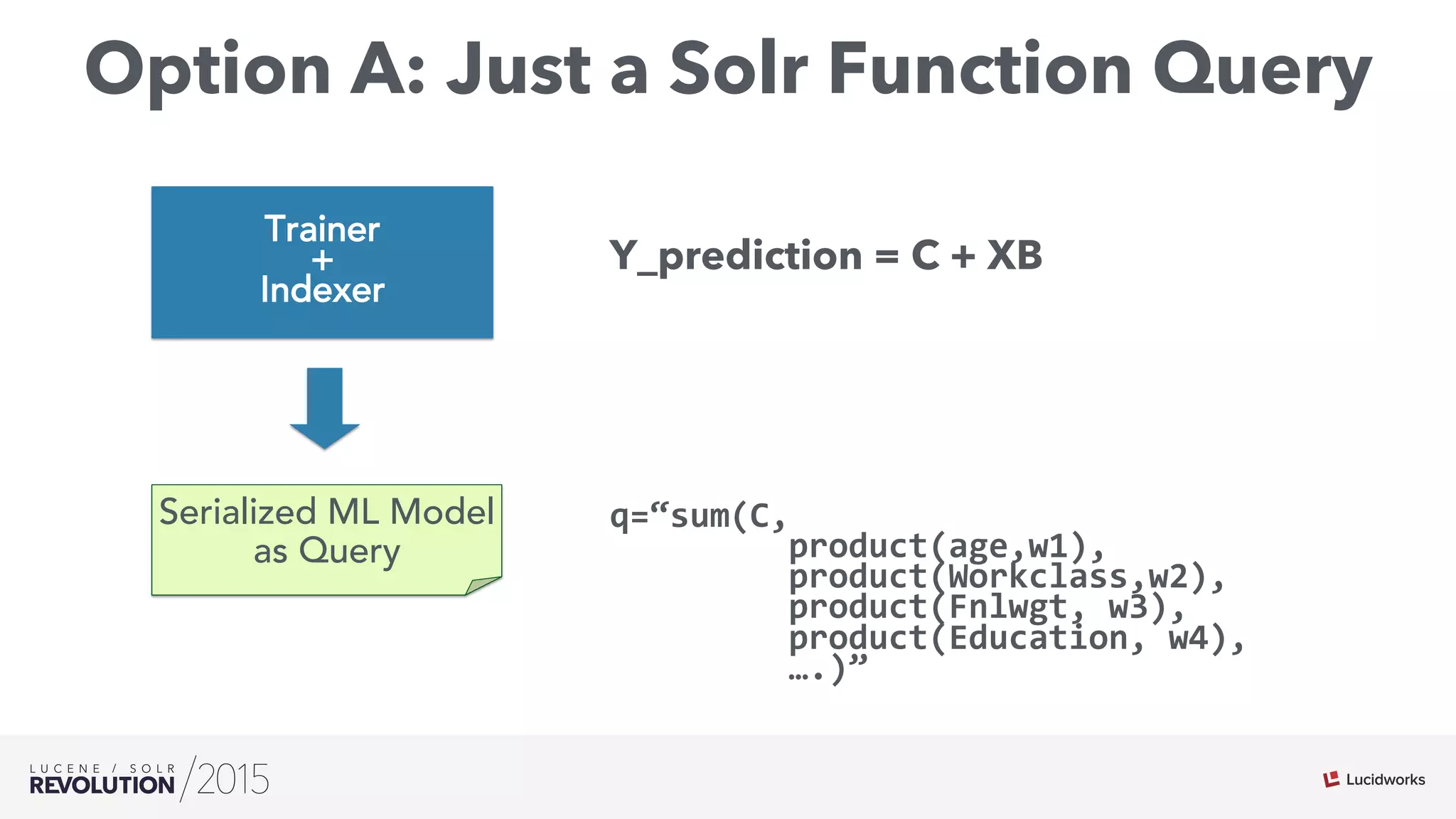
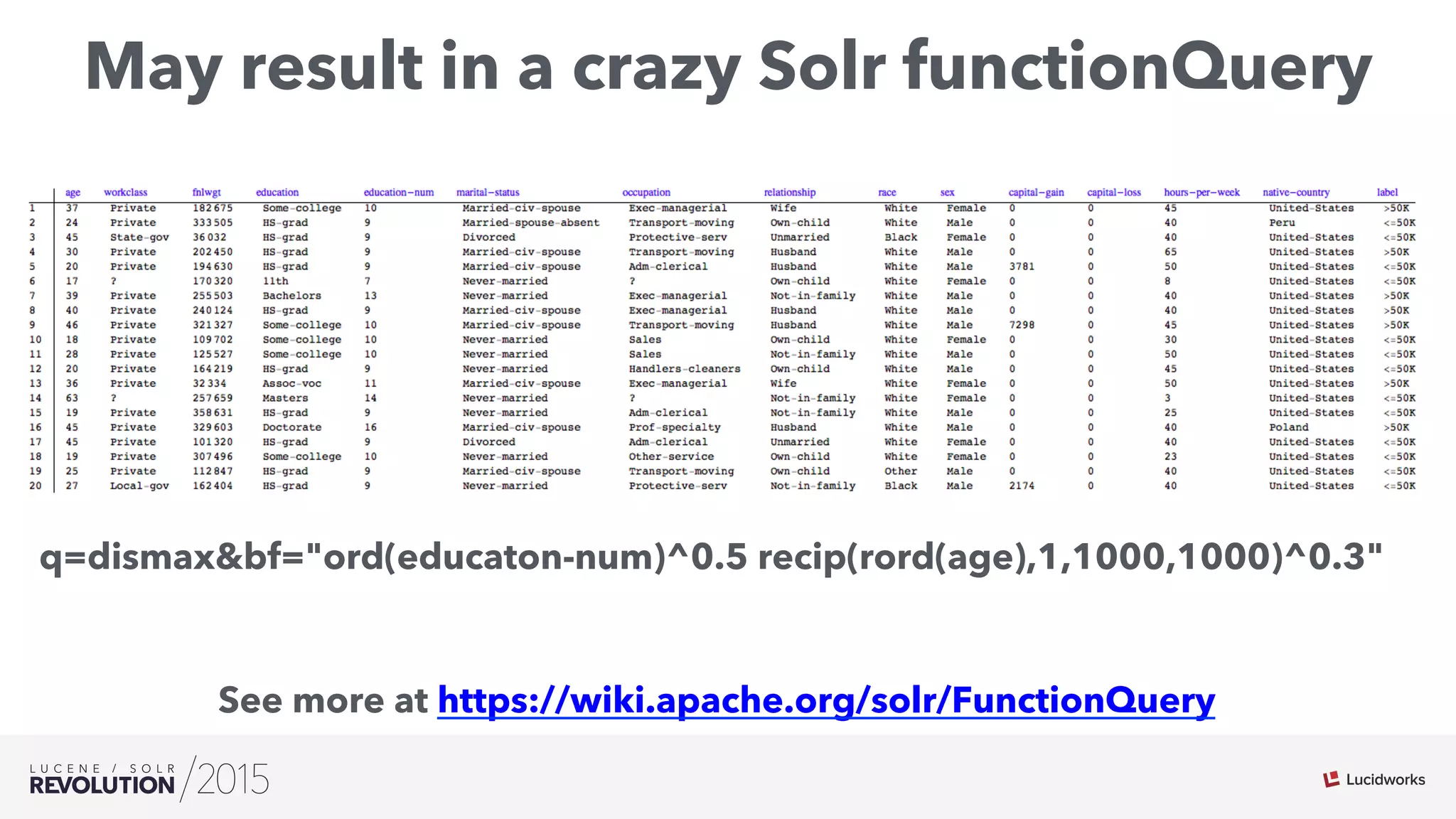
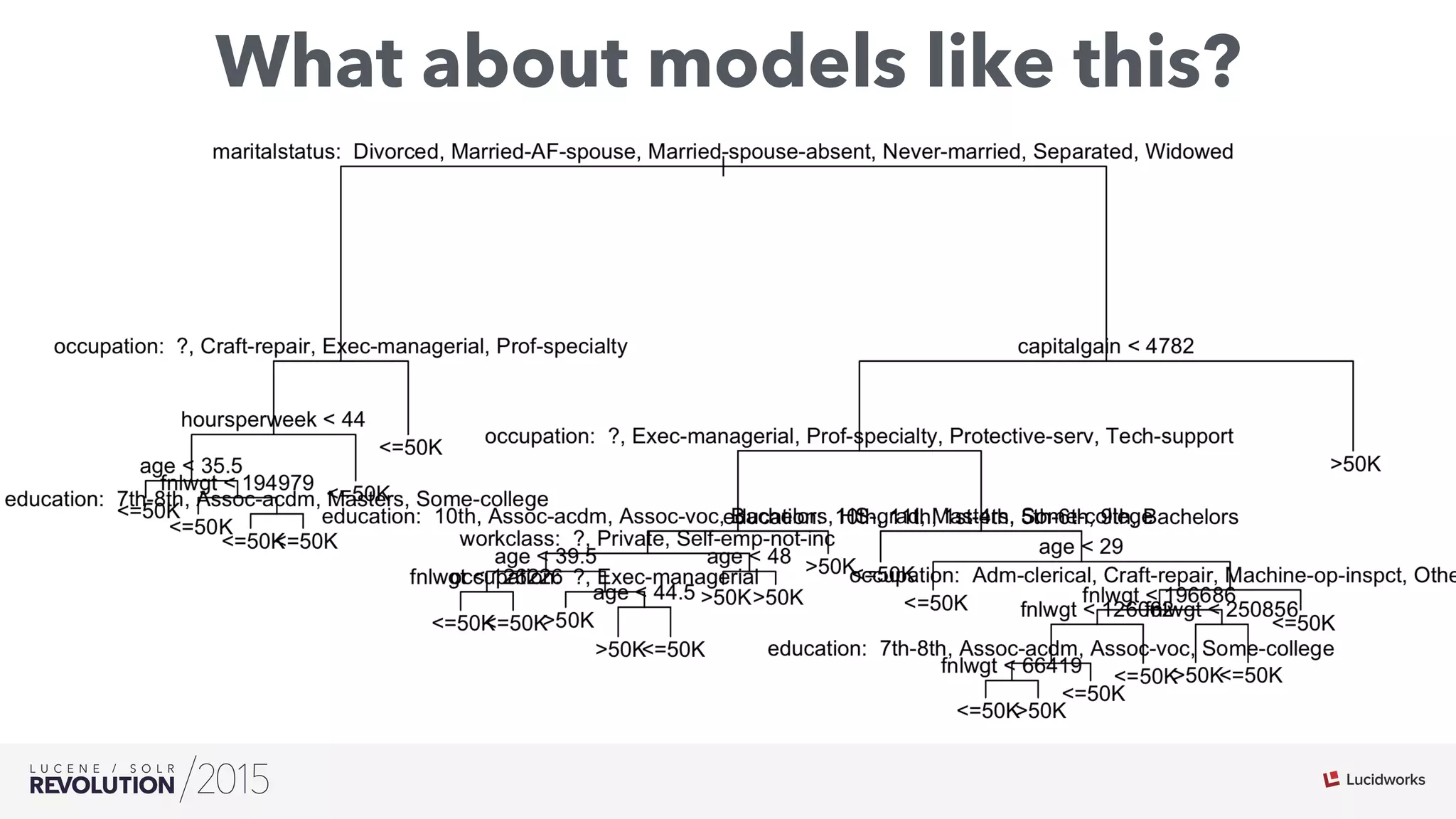
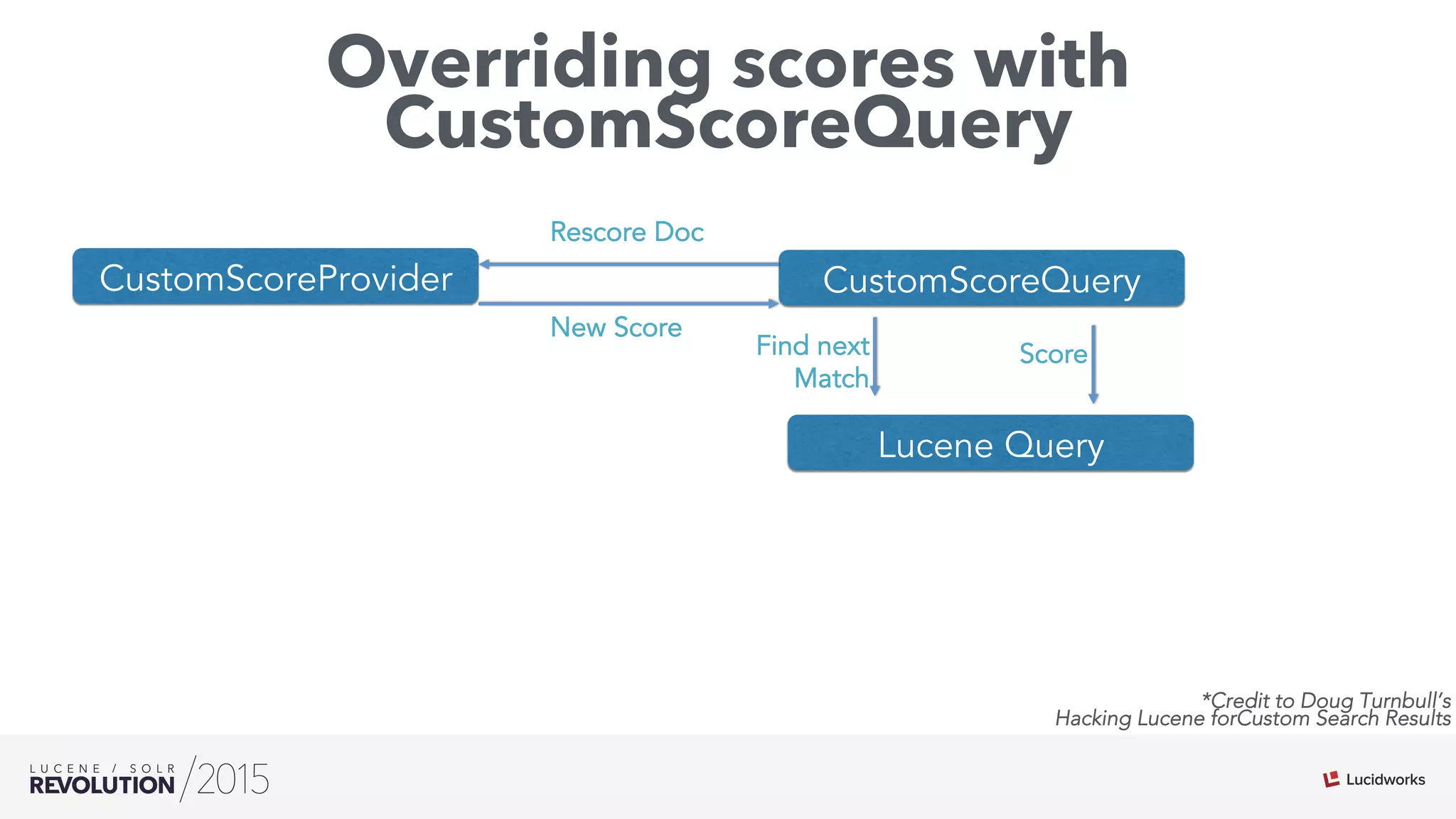
The document discusses the intersection of search technologies and machine learning, highlighting the challenges of scaling learning systems for real-world applications. It presents strategies for integrating machine learning into search systems, such as using custom scoring queries and the PMML for model interoperability. The authors emphasize the complexity of implementing effective and efficient learning systems while addressing issues related to performance, scalability, and system architecture.































































![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
